Clear Sky Science · en
Dual asymmetric momentum improves federated class unlearning in edge systems
Why teaching machines to forget matters
Our phones, watches, and home gadgets constantly learn from the data we feed them, from photos and voice clips to health readings. But what happens when laws or users demand that certain data must be erased, not just from storage but from the very behavior of the artificial intelligence models involved? Retraining those models from scratch can be slow, expensive, and sometimes unrealistic on millions of tiny devices. This paper explores a lighter way to make large, distributed learning systems “forget” selected information while still working well on everything else.
Learning together without sharing your data
Many modern systems use federated learning, where a central server coordinates training while the raw data stays on each device. Phones or sensors update a shared model using their local data, then send only model changes back. This setup helps protect privacy and saves bandwidth, but it does not remove all risk. The model can still carry traces of who or what it has seen, and research has shown that clever attacks can sometimes tell whether specific data were used during training. Growing privacy rules such as Europe’s right to be forgotten have therefore created pressure for “machine unlearning” procedures that reduce a model’s dependence on designated data, such as one class of images or a particular group of users.
Why unlearning in the real world is so hard
In theory, the cleanest solution is to throw away the unwanted data and retrain the model from the start using only the remaining information. In practice, full retraining means huge communication costs, repeated coordination among many clients, and long runtimes, especially when data are unevenly spread across devices. On top of this, trying to forget one piece of knowledge can harm performance on everything else, because the same model parameters support both. The authors show that the internal training machinery, in particular the optimizer’s momentum state that smooths updates over time, can blend “forget” and “retain” signals together so that efforts to erase one class interfere with the rest of the model’s skills.
A lighter add on head for forgetting
The proposed method, called FedDAM, tackles these challenges by changing only a small part of the model after it has already been trained. The main network that extracts features from data and its original classifier are frozen in place. On top of them, the authors add a new, small “auxiliary head” whose job is to tweak the final predictions in a controlled way. During unlearning, only this auxiliary head is updated and shared across devices, which greatly reduces communication and computation compared with retraining the full model. By working directly at the level of final scores, the method can shift decision boundaries for a target class while leaving the deep feature extractor untouched, making it attractive for resource constrained phones and edge devices.
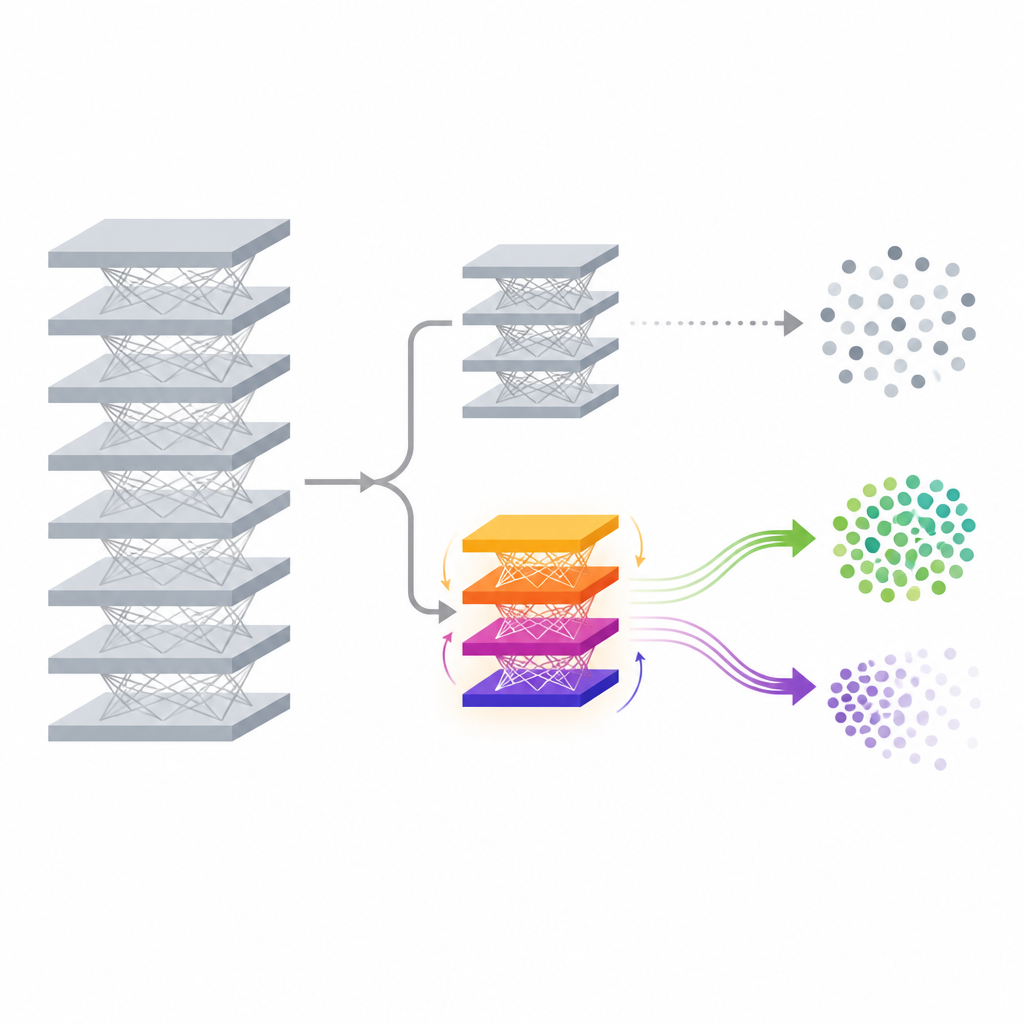
Two streams of memory for keeping and forgetting
The key technical idea in FedDAM is to separate the forces that want to forget from those that want to preserve knowledge. Each participating client divides its local data into “retain” and “forget” sets, then alternates updates based on each. Instead of feeding both into a single momentum state, the method keeps two distinct momentum buffers, one for retention and one for forgetting, and combines them asymmetrically when updating the auxiliary head. Forgetting updates are given a shorter memory and slightly higher weight, so the model reacts quickly when it sees data that should be erased, while still listening to the quieter pull of the retained data. Through experiments, the authors show that this dual stream reduces direct conflict between the two goals and aligns updates more closely with the intended forgetting behavior.
How well does selective forgetting work in practice
The team tests FedDAM on standard image collections, including CIFAR 10, CIFAR 100, and a mid sized ImageNet 100 setup, under realistic federated conditions where each client has only a slice of the data and some clients may have none of the examples that should be forgotten. They compare their method to several alternatives that either use a single shared momentum, project conflicting gradients, or scrub overlapping directions, as well as to compressed full model retraining. Across these studies, FedDAM consistently achieves better accuracy on the retained classes at similar levels of forgetting, with gains of around 7 to 9 percentage points on harder, more diverse datasets. At the same time, it uses far less communication and runtime than full retraining, even when the latter is aggressively compressed.
What this means for everyday devices
For non specialists, the main message is that it is possible to design learning systems that can later “unlearn” certain categories of data more flexibly, without starting over and without overly hurting performance on everything else. FedDAM offers a practical recipe for doing this in federated and edge settings by freezing most of the model, adjusting only a small auxiliary head, and carefully separating the influences of data we want to keep from data we want to forget. While it does not provide formal privacy guarantees and cannot handle every possible kind of removal request, the approach offers a useful middle ground between doing nothing and paying the full price of retraining, helping bring the idea of machine unlearning closer to real world deployment.
Citation: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Keywords: federated learning, machine unlearning, edge computing, privacy in AI, neural networks