Clear Sky Science · it
Il momentum asimmetrico duale migliora il unlearning federato nei sistemi edge
Perché insegnare alle macchine a dimenticare è importante
I nostri telefoni, orologi e dispositivi domestici apprendono costantemente dai dati che forniamo loro, dalle foto e clip vocali alle letture sanitarie. Ma cosa succede quando le leggi o gli utenti richiedono che determinati dati vengano cancellati, non solo dallo storage ma anche dal comportamento stesso dei modelli di intelligenza artificiale coinvolti? Riaddestrare quei modelli da zero può essere lento, costoso e talvolta irrealistico su milioni di piccoli dispositivi. Questo articolo esplora una via più leggera per far “dimenticare” a grandi sistemi di apprendimento distribuito informazioni selezionate mantenendo comunque buone prestazioni sul resto.
Apprendere insieme senza condividere i tuoi dati
Molti sistemi moderni usano il federated learning, dove un server centrale coordina l'addestramento mentre i dati grezzi restano su ciascun dispositivo. Telefoni o sensori aggiornano un modello condiviso usando i loro dati locali, quindi inviano solo le modifiche del modello. Questa configurazione aiuta a proteggere la privacy e a risparmiare banda, ma non elimina tutti i rischi. Il modello può comunque conservare tracce di chi o cosa ha visto, e ricerche hanno dimostrato che attacchi sofisticati possono talvolta rilevare se dati specifici sono stati usati durante l'addestramento. Normative sulla privacy in crescita, come il diritto all'oblio in Europa, hanno quindi creato pressione per procedure di “machine unlearning” che riducano la dipendenza di un modello da dati designati, come una classe di immagini o un gruppo particolare di utenti.
Perché l'unlearning nel mondo reale è così difficile
In teoria, la soluzione più pulita è scartare i dati indesiderati e riaddestrare il modello dall'inizio usando solo le informazioni rimanenti. In pratica, il riaddestramento completo comporta costi di comunicazione enormi, ripetuta coordinazione tra molti clienti e lunghi tempi di esecuzione, specialmente quando i dati sono distribuiti in modo non uniforme sui dispositivi. Inoltre, cercare di dimenticare una conoscenza può danneggiare le prestazioni sul resto, perché gli stessi parametri del modello supportano entrambi. Gli autori mostrano che la macchina interna dell'addestramento, in particolare lo stato di momentum dell'ottimizzatore che smussa gli aggiornamenti nel tempo, può mescolare i segnali di “dimentica” e “mantieni” in modo che gli sforzi per cancellare una classe interferiscano con le altre abilità del modello.
Un leggero head aggiuntivo per dimenticare
Il metodo proposto, chiamato FedDAM, affronta queste sfide cambiando solo una piccola parte del modello dopo che è stato già addestrato. La rete principale che estrae le feature dai dati e il suo classificatore originale vengono congelati. Sopra di essi, gli autori aggiungono un nuovo e piccolo “auxiliary head” il cui compito è modulare le predizioni finali in modo controllato. Durante l'unlearning, viene aggiornato e condiviso solo questo auxiliary head, riducendo molto comunicazione e calcolo rispetto al riaddestramento dell'intero modello. Agendo direttamente sul livello dei punteggi finali, il metodo può spostare i confini decisionali per una classe obiettivo lasciando intatto l'estrattore di feature profondo, risultando attraente per telefoni e dispositivi edge con risorse limitate.
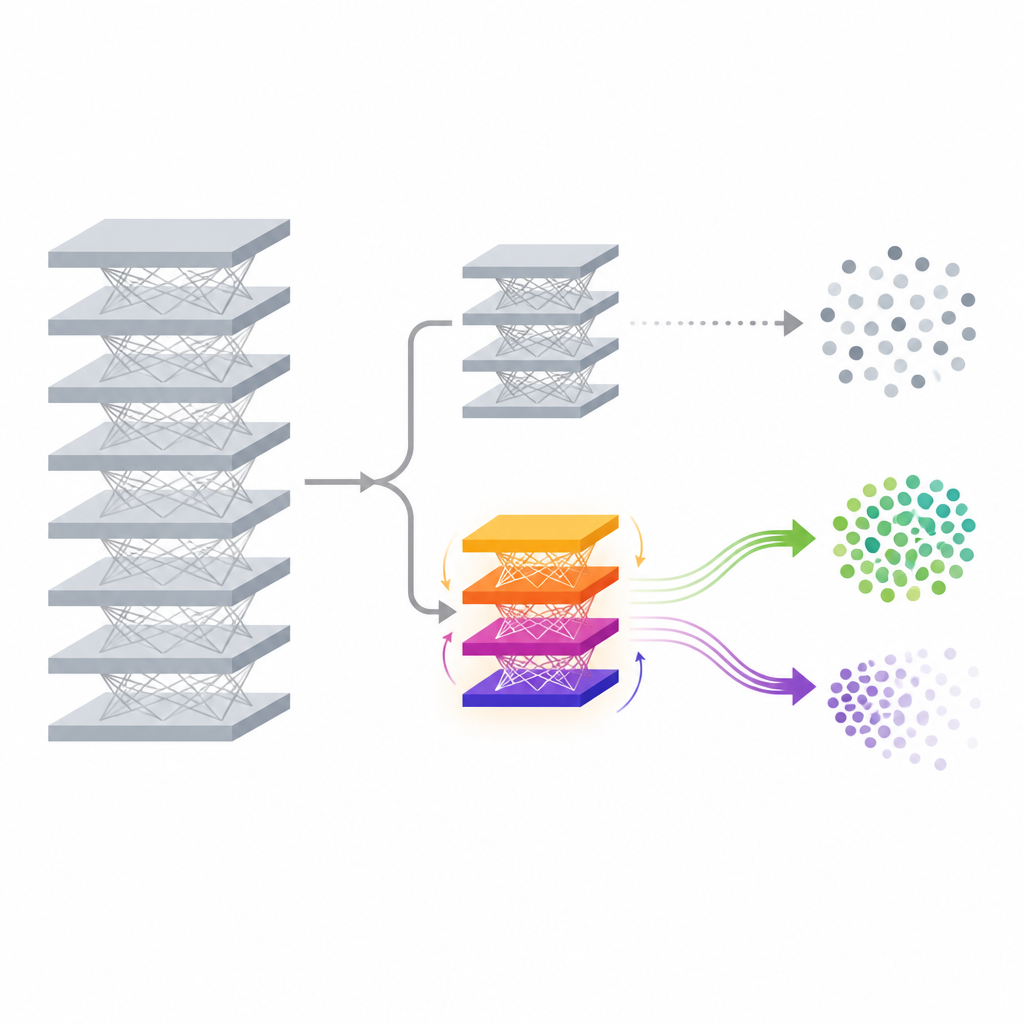
Due flussi di memoria per mantenere e dimenticare
L'idea tecnica chiave in FedDAM è separare le forze che vogliono dimenticare da quelle che vogliono preservare la conoscenza. Ciascun client partecipante divide i suoi dati locali in insiemi “retain” e “forget”, quindi alterna aggiornamenti basati su ciascuno. Invece di alimentare entrambi in un unico stato di momentum, il metodo conserva due buffer di momentum distinti, uno per la conservazione e uno per l'oblio, e li combina in modo asimmetrico quando aggiorna l'auxiliary head. Gli aggiornamenti di forgetting hanno una memoria più corta e un peso leggermente maggiore, così il modello reagisce rapidamente quando vede dati che devono essere cancellati, mantenendo però l'influenza più debole dei dati da conservare. Attraverso esperimenti, gli autori mostrano che questo doppio flusso riduce i conflitti diretti tra i due obiettivi e allinea gli aggiornamenti più strettamente al comportamento di dimenticanza desiderato.
Quanto funziona nella pratica il dimenticare selettivo
Il team testa FedDAM su collezioni di immagini standard, inclusi CIFAR-10, CIFAR-100 e una configurazione ImageNet-100 di medie dimensioni, in condizioni federate realistiche dove ogni client ha solo una porzione dei dati e alcuni client potrebbero non avere esempi da dimenticare. Confrontano il loro metodo con diverse alternative che usano un unico momentum condiviso, proiettano gradienti in conflitto o rimuovono direzioni sovrapposte, oltre al riaddestramento completo del modello compresso. In tutti questi studi, FedDAM raggiunge costantemente una migliore accuratezza sulle classi mantenute a livelli di dimenticanza simili, con guadagni di circa 7–9 punti percentuali su dataset più difficili e diversificati. Allo stesso tempo, utilizza molta meno comunicazione e tempo di esecuzione rispetto al riaddestramento completo, anche quando quest'ultimo è fortemente compresso.
Cosa significa per i dispositivi di tutti i giorni
Per i non specialisti, il messaggio principale è che è possibile progettare sistemi di apprendimento che possano successivamente “dimenticare” categorie di dati in modo più flessibile, senza ricominciare da capo e senza danneggiare eccessivamente le prestazioni sul resto. FedDAM offre una ricetta pratica per farlo in contesti federati e edge congelando la maggior parte del modello, regolando solo un piccolo auxiliary head e separando con cura le influenze dei dati che vogliamo mantenere da quelli che vogliamo dimenticare. Pur non fornendo garanzie formali di privacy e non potendo gestire ogni possibile tipo di richiesta di rimozione, l'approccio offre un compromesso utile tra non fare nulla e pagare il prezzo pieno del riaddestramento, avvicinando il concetto di machine unlearning a una reale applicazione pratica.
Citazione: Patra, A., Mayaluri, Z.L., Sahoo, P.K. et al. Dual asymmetric momentum improves federated class unlearning in edge systems. Sci Rep 16, 14748 (2026). https://doi.org/10.1038/s41598-026-45631-w
Parole chiave: federated learning, machine unlearning, edge computing, privacy in AI, neural networks