Clear Sky Science · pt
Detecção monocular eficiente de faixas 3D via estrutura CM-3DLane aprimorada com Mamba
Percepção viária digital mais nítida
Manter-se com segurança na própria faixa é algo que a maioria dos motoristas faz sem pensar. Para carros autônomos, entretanto, entender onde as marcações de faixa correm em três dimensões é um quebra-cabeça exigente. Este estudo apresenta o CM-3DLane, um novo sistema de visão computacional que permite a um carro equipado apenas com uma câmera frontal ler a forma das faixas em 3D de maneira mais precisa e eficiente, mesmo em subidas, curvas e condições meteorológicas adversas.
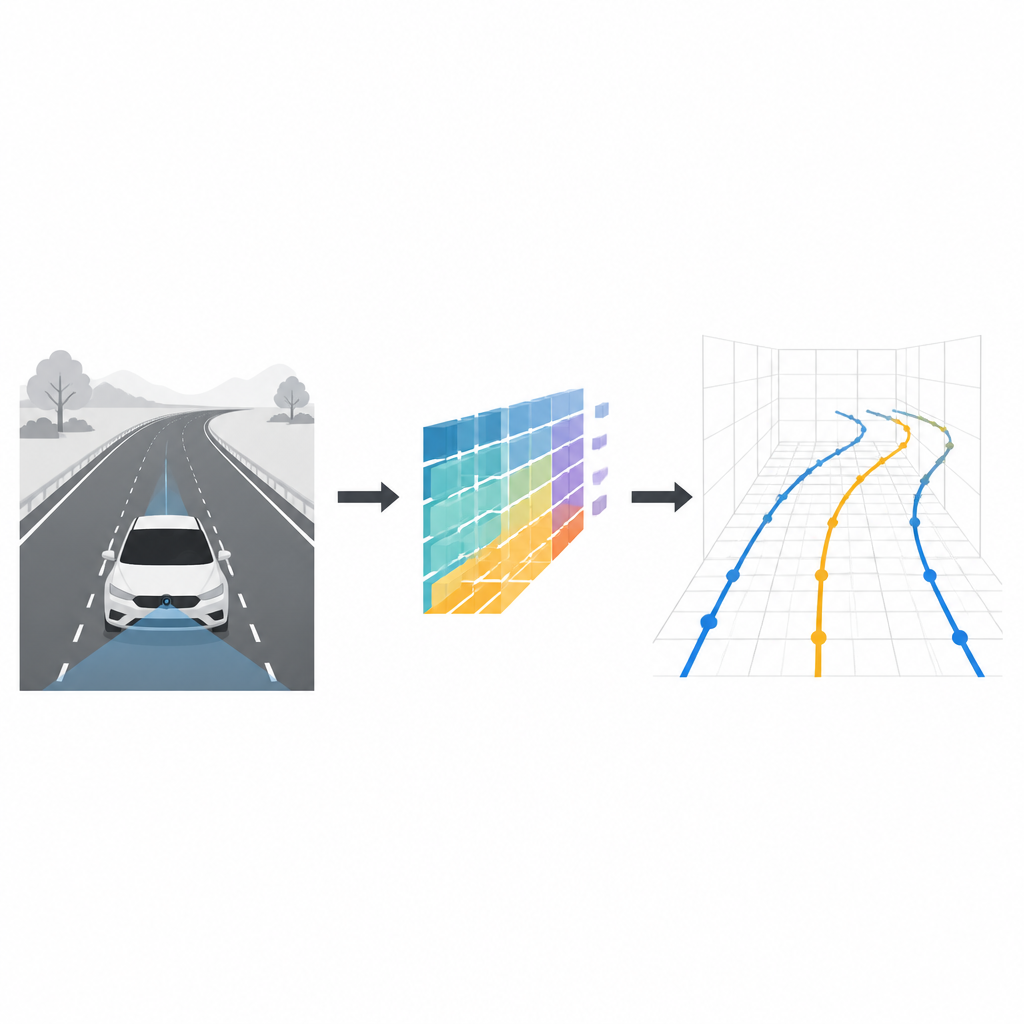
Por que as faixas em 3D realmente importam
A maioria dos sistemas de assistência ao motorista hoje trata a detecção de faixas como um problema plano, bidimensional: eles marcam as faixas na imagem da câmera ou em um mapa vista de cima da estrada. Isso costuma ser suficiente para direção simples em rodovias, mas falha em ladeiras íngremes, rampas e cruzamentos complexos. Um modelo plano não descreve completamente quão distante está uma linha de faixa, como ela sobe ou desce, ou como se curva no espaço. A detecção de faixas em três dimensões oferece detalhes espaciais mais ricos, o que ajuda a planejar trajetórias suaves, manter distâncias seguras e tomar melhores decisões em alta velocidade.
Limites dos métodos atuais com câmeras
Os sistemas baseados em câmeras existentes normalmente funcionam de duas maneiras. Muitos primeiro deformam a visão da câmera para uma projeção em vista aérea usando a suposição simples de estrada plana, e então elevam essas faixas 2D de volta para 3D. Esse atalho falha quando a estrada tem inclinações ou remendos, e também distorce veículos e outros objetos sobre a superfície da via. Outros métodos recentes ignoram a vista aérea e modelam as faixas diretamente como curvas 3D ancoradas no espaço. Embora mais precisos em princípio, esses métodos enfrentam dificuldades porque as marcações de faixa são finas, tênues e frequentemente interrompidas, tornando difícil conectar suas partes distantes usando redes neurais padrão sem consumir muito poder computacional.
Uma forma mais inteligente de ler faixas com uma câmera
A estrutura CM-3DLane busca capturar tanto os detalhes finos quanto a estrutura em grande escala das faixas, mantendo-se leve o suficiente para uso em tempo real no carro. Começa com uma rede de imagem convencional que extrai características em várias escalas a partir da visão frontal da câmera, variando de contornos grosseiros a texturas finas. Um módulo de Fusão por Atenção entre Escalas (Cross-Scale Attention Fusion) então aprende a mesclar essas escalas, de modo que faixas estreitas e distantes e faixas largas e próximas sejam tratadas adequadamente, e texturas de fundo confusas sejam suprimidas. Isso ajuda o sistema a focar na pintura real da faixa em vez de sombras, rachaduras ou marcações rodoviárias de aparência similar.
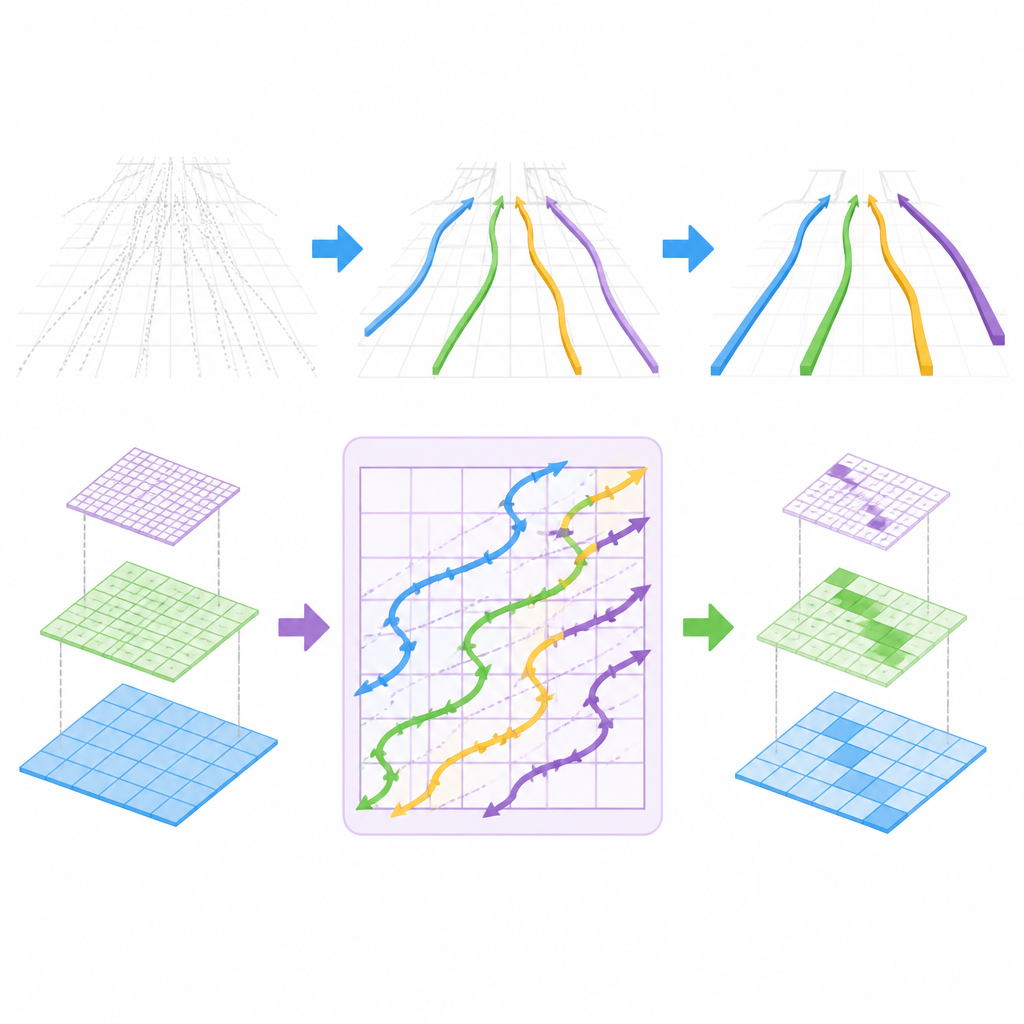
Acompanhando curvas de faixa como um scanner
A inovação chave está em como o CM-3DLane modela a estrutura de faixa em longo alcance. Os autores adaptam uma família recente de modelos conhecidos como modelos de espaço de estados, originalmente projetados para processamento rápido de sequências, em um bloco Lane-Aware Mamba. Em vez de ler pixels da imagem linha por linha, esse bloco varre características ao longo de caminhos diagonais especiais em zigue-zague que seguem melhor as curvas naturais das faixas à medida que se afastam. Ao fazer isso, ele costura pistas de faixa espalhadas por grandes áreas da cena, mantendo o custo computacional baixo o suficiente para operação em tempo real.
Manter apenas os candidatos de faixa mais úteis
Outro desafio é que o sistema deve considerar muitas curvas 3D possíveis e decidir quais realmente correspondem a faixas. O CM-3DLane introduz um módulo de Classificação Dinâmica de Âncoras Refinada (Refined Anchor Dynamic Ranking) que pontua essas curvas candidatas usando um mapa auxiliar simples de posições prováveis de faixas e sua aparência local. Em seguida, mantém apenas os candidatos mais promissores, reduzindo tanto a confusão quanto o cálculo. Essa etapa de seleção é guiada por regras geométricas simples que preferem formas de faixas suaves e consistentes em vez de jaggedas ou implausíveis.
O que os resultados significam para os carros do futuro
Testado em dois benchmarks exigentes, incluindo um grande conjunto de dados do mundo real construído a partir de cenas urbanas e rodoviárias, o CM-3DLane alcança maior precisão que métodos anteriores enquanto roda a até dezenas de quadros por segundo em uma única placa gráfica e permanece prático mesmo em hardware embarcado de veículos. Para não especialistas, a mensagem principal é que o sistema permite que um carro com apenas uma câmera construa uma imagem 3D mais clara de suas faixas em condições variadas e messy, aproximando-se de uma condução automatizada mais segura e confiável sem depender de sensores de profundidade caros.
Citação: Yang, Y., Zhang, X. & Liu, Y. Efficient monocular 3D lane detection via Mamba-enhanced CM-3DLane framework. Sci Rep 16, 15074 (2026). https://doi.org/10.1038/s41598-026-44870-1
Palavras-chave: detecção de faixas 3D, condução autônoma, visão monocular, modelos de espaço de estados, visão computacional