Clear Sky Science · en
Efficient monocular 3D lane detection via Mamba-enhanced CM-3DLane framework
Sharper digital road sense
Staying safely in your lane is something most drivers do without thinking. For self-driving cars, however, understanding where lane markings run in three dimensions is a demanding puzzle. This study introduces CM-3DLane, a new computer vision system that lets a car with only a single front-facing camera read the shape of lanes in 3D more accurately and efficiently, even on hills, curves, and in bad weather.
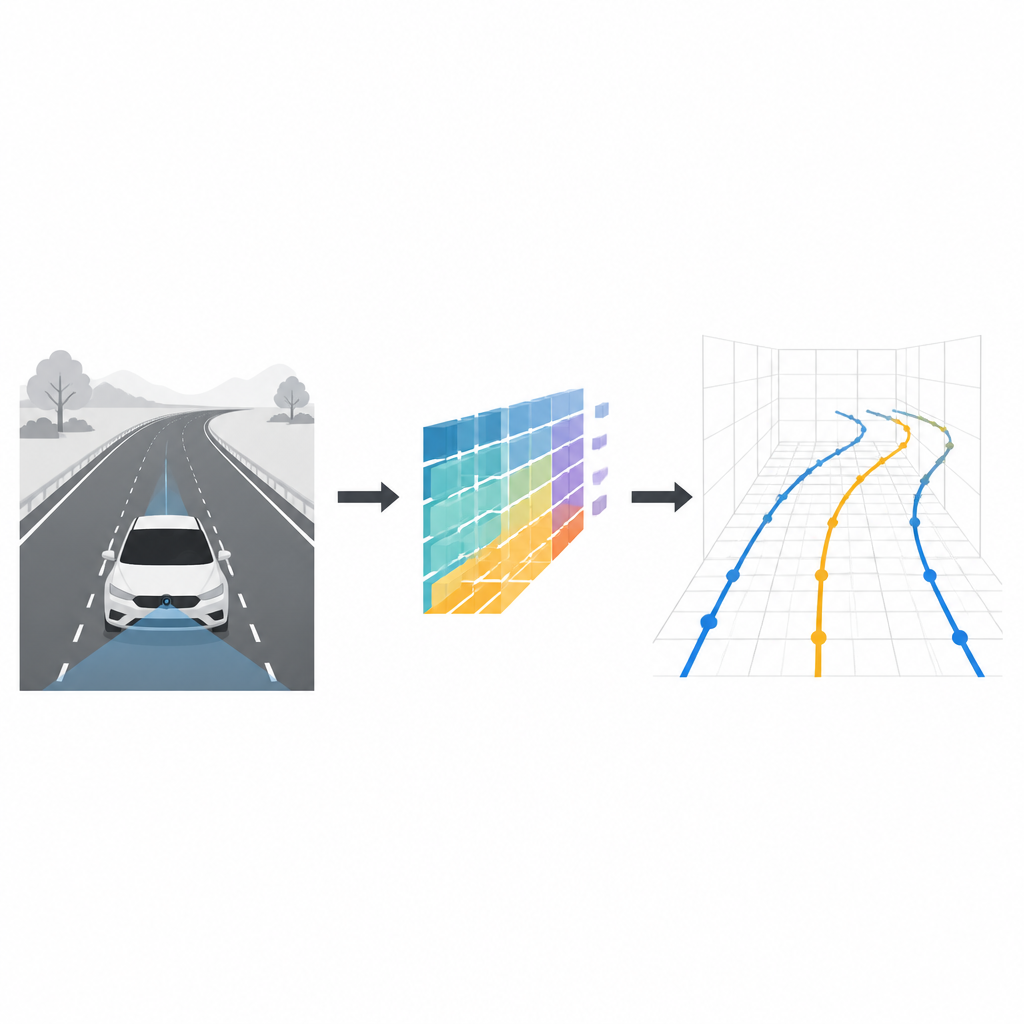
Why lanes in 3D really matter
Most driver-assistance systems today treat lane detection as a flat, two-dimensional problem: they mark lanes on the camera image or on a bird’s-eye map of the road. That is often good enough for simple highway driving, but it breaks down on steep hills, ramps, and complex junctions. A flat model cannot fully describe how far away a lane line is, how it rises or falls, or how it curves in space. Three-dimensional lane detection offers richer spatial detail, which helps planning smooth trajectories, keeping safe distances, and making better decisions at high speed.
Limits of current camera methods
Existing camera-based systems usually work in one of two ways. Many first warp the camera view into a bird’s-eye projection using a simple flat-road assumption, then lift those 2D lanes back into 3D. This shortcut fails when the road slopes or has bumps, and it also distorts vehicles and other objects that sit on the road surface. Other recent methods skip the bird’s-eye view and instead model lanes directly as 3D curves anchored in space. While more accurate in principle, these approaches struggle because lane markings are thin, faint, and often broken, making it hard to connect their distant pieces using standard neural networks without consuming huge computing power.
A smarter way to read lanes from one camera
The CM-3DLane framework aims to capture both the fine details and the big-picture structure of lanes while staying lightweight enough for real-time use in a car. It starts with a conventional image network that extracts features at several scales from the front camera view, ranging from coarse outlines to fine textures. A Cross-Scale Attention Fusion module then learns how to blend these scales, so that distant, narrow lanes and nearby, wide ones are both handled well, and confusing background textures are suppressed. This helps the system focus on true lane paint rather than shadows, cracks, or road markings that look similar.
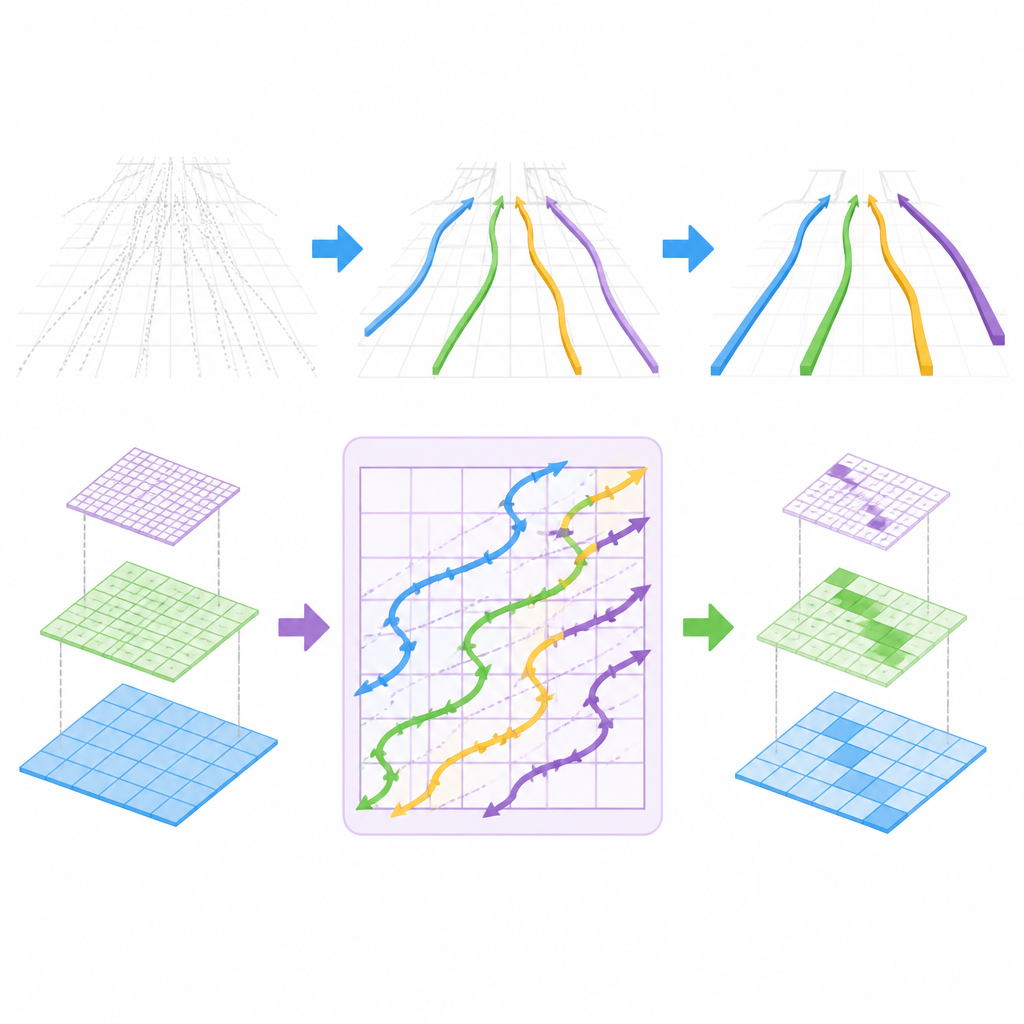
Following lane curves like a scanner
The key innovation lies in how CM-3DLane models long-range lane structure. The authors adapt a recent family of models known as state space models, originally designed for fast sequence processing, into a Lane-Aware Mamba block. Instead of reading image pixels row by row, this block scans features along special snaking diagonal paths that better follow natural lane curves as they recede into the distance. In doing so, it stitches together scattered lane clues over large areas of the scene, while keeping computation low enough for real-time operation.
Keeping only the most useful lane candidates
Another challenge is that the system must consider many possible 3D curves and decide which ones truly correspond to lanes. CM-3DLane introduces a Refined Anchor Dynamic Ranking module that scores these candidate curves using a simple helper map of likely lane positions and their local appearance. It then keeps only the most promising candidates, reducing both confusion and computation. This selection step is guided by simple geometric rules that prefer smooth, consistent lane shapes over jagged or implausible ones.
What the results mean for future cars
Tested on two demanding benchmarks, including a large real-world dataset built from city and highway scenes, CM-3DLane reaches higher accuracy than previous methods while running at up to dozens of frames per second on a single graphics card and remaining practical even on embedded car hardware. For non-specialists, the take-home message is that the system allows a car with just one camera to build a clearer 3D picture of its lanes in varied and messy conditions, moving a step closer to safer and more reliable automated driving without relying on expensive depth sensors.
Citation: Yang, Y., Zhang, X. & Liu, Y. Efficient monocular 3D lane detection via Mamba-enhanced CM-3DLane framework. Sci Rep 16, 15074 (2026). https://doi.org/10.1038/s41598-026-44870-1
Keywords: 3D lane detection, autonomous driving, monocular vision, state space models, computer vision