Clear Sky Science · fr
Détection monoculaire 3D des voies efficace via le cadre CM-3DLane amélioré par Mamba
Une perception routière numérique plus nette
Rester en sécurité dans sa voie est quelque chose que la plupart des conducteurs font sans y penser. Pour les voitures autonomes, en revanche, comprendre où passent les marquages de voie en trois dimensions est un casse-tête exigeant. Cette étude présente CM-3DLane, un nouveau système de vision par ordinateur qui permet à une voiture disposant d’une seule caméra frontale de lire la forme des voies en 3D de manière plus précise et efficace, même sur des côtes, des courbes et par mauvais temps.
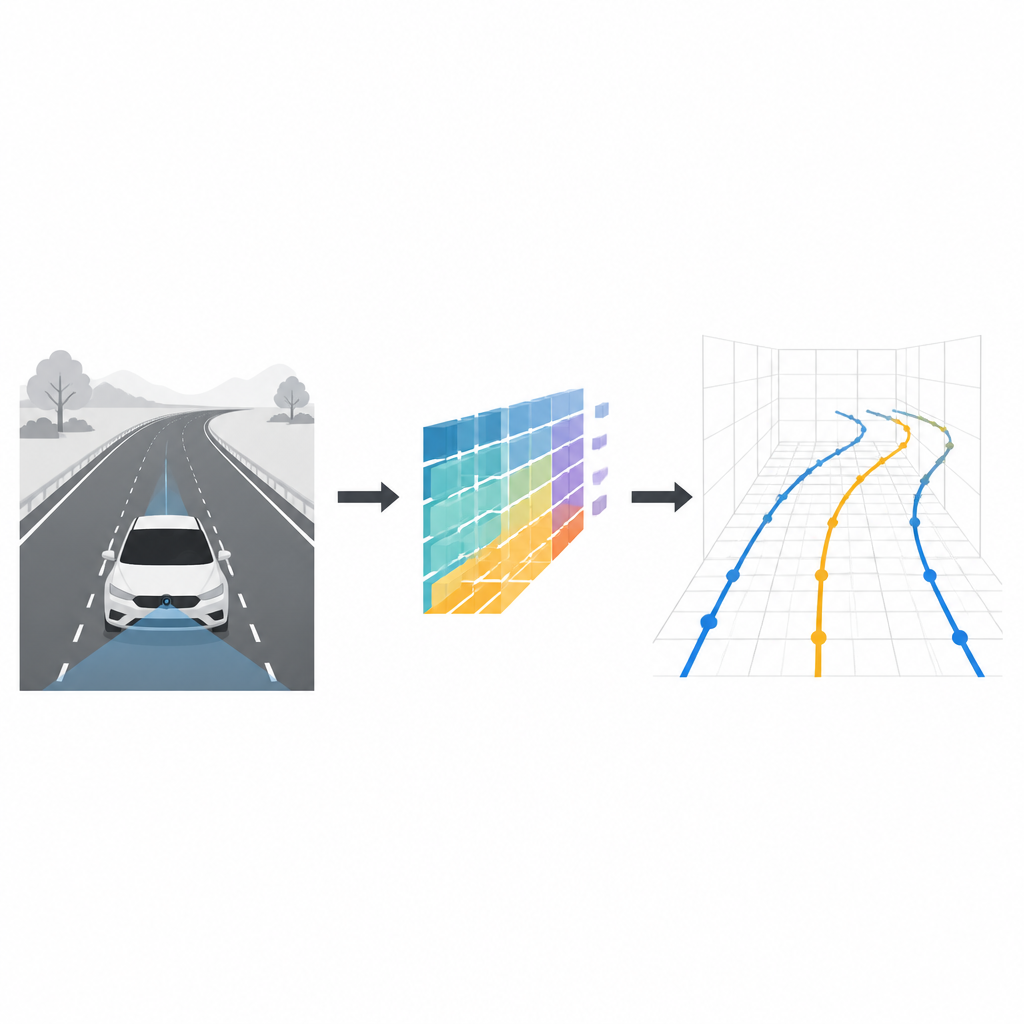
Pourquoi les voies en 3D comptent vraiment
La plupart des systèmes d’aide à la conduite traitent aujourd’hui la détection de voies comme un problème plat en deux dimensions : ils marquent les voies sur l’image de la caméra ou sur une carte en vue de dessus. Cela suffit souvent pour une conduite simple sur autoroute, mais cela échoue sur des pentes raides, des bretelles et des carrefours complexes. Un modèle plat ne peut pas décrire complètement la distance d’un trait de voie, sa montée ou sa descente, ni sa courbure dans l’espace. La détection de voies en trois dimensions offre des détails spatiaux plus riches, ce qui aide à planifier des trajectoires fluides, à maintenir des distances de sécurité et à prendre de meilleures décisions à grande vitesse.
Limites des méthodes actuelles à caméra
Les systèmes basés sur caméra existants fonctionnent généralement de deux manières. Beaucoup reprojectent d’abord la vue de la caméra en une projection en vue de dessus en supposant une route plate, puis remontent ces voies 2D en 3D. Ce raccourci échoue lorsque la route est en pente ou bosselée, et il déforme aussi les véhicules et autres objets posés sur la chaussée. D’autres méthodes récentes sautent la vue en plongée et modélisent les voies directement comme des courbes 3D ancrées dans l’espace. Bien que plus précises en principe, ces approches peinent parce que les marquages de voie sont fins, peu contrastés et souvent interrompus, rendant difficile la connexion de leurs segments lointains par des réseaux neuronaux standards sans consommer une très grande puissance de calcul.
Une façon plus intelligente de lire les voies avec une seule caméra
Le cadre CM-3DLane vise à capturer à la fois les détails fins et la structure d’ensemble des voies tout en restant suffisamment léger pour une utilisation en temps réel dans un véhicule. Il commence par un réseau d’image conventionnel qui extrait des caractéristiques à plusieurs échelles depuis la vue frontale, allant des contours grossiers aux textures fines. Un module de Fusion par Attention Inter-échelles apprend ensuite à combiner ces échelles, de sorte que les voies étroites et lointaines comme les voies larges et proches soient traitées correctement, et que les textures d’arrière-plan trompeuses soient supprimées. Cela aide le système à se concentrer sur la peinture des voies plutôt que sur les ombres, les fissures ou d’autres marquages routiers similaires.
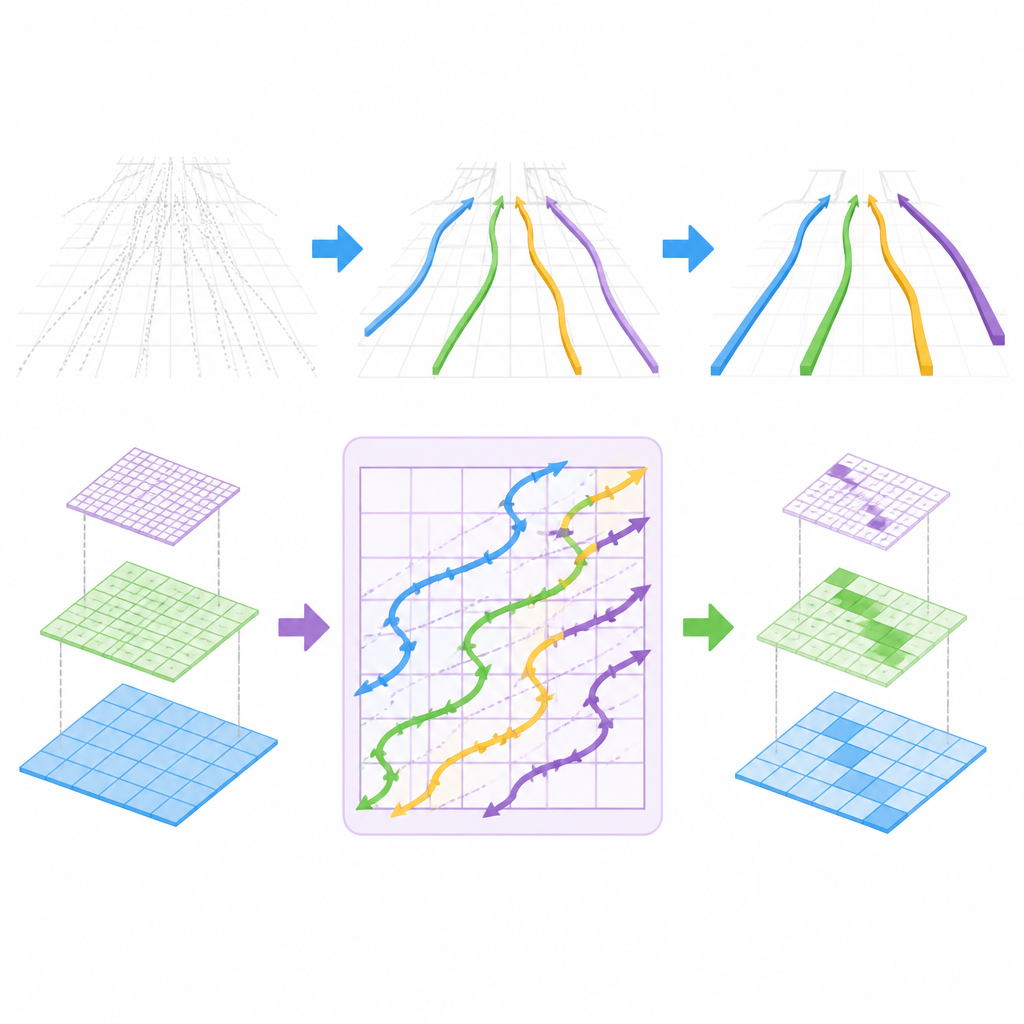
Suivre les courbes des voies comme un scanner
L’innovation clé réside dans la façon dont CM-3DLane modélise la structure des voies sur de longues distances. Les auteurs adaptent une famille récente de modèles connus sous le nom de modèles d’espace d’état, conçus à l’origine pour un traitement rapide des séquences, en un bloc Lane-Aware Mamba. Au lieu de lire les pixels image ligne par ligne, ce bloc balaie les caractéristiques le long de trajectoires diagonales en zigzag qui suivent mieux les courbes naturelles des voies à mesure qu’elles s’éloignent. Ce faisant, il recoud ensemble des indices de voie épars sur de larges zones de la scène, tout en maintenant une charge de calcul suffisamment basse pour une opération en temps réel.
Ne garder que les candidats de voie les plus utiles
Un autre défi est que le système doit considérer de nombreuses courbes 3D possibles et décider lesquelles correspondent réellement à des voies. CM-3DLane introduit un module de Classement Dynamique des Ancres Raffiné qui évalue ces courbes candidates à l’aide d’une carte d’aide simple des positions probables des voies et de leur apparence locale. Il ne conserve ensuite que les candidats les plus prometteurs, réduisant à la fois la confusion et le calcul. Cette étape de sélection est guidée par des règles géométriques simples qui favorisent des formes de voies lisses et cohérentes plutôt que des formes dentelées ou peu plausibles.
Ce que les résultats signifient pour les voitures de demain
Testé sur deux bancs d’essai exigeants, dont un grand jeu de données du monde réel construit à partir de scènes urbaines et autoroutières, CM-3DLane atteint une précision supérieure aux méthodes précédentes tout en fonctionnant à des dizaines d’images par seconde sur une seule carte graphique et en restant pratique même sur du matériel embarqué. Pour les non-spécialistes, l’idée à retenir est que le système permet à une voiture équipée d’une seule caméra de construire une image 3D plus claire de ses voies dans des conditions variées et désordonnées, rapprochant un peu plus d’une conduite automatisée plus sûre et plus fiable sans dépendre de capteurs de profondeur coûteux.
Citation: Yang, Y., Zhang, X. & Liu, Y. Efficient monocular 3D lane detection via Mamba-enhanced CM-3DLane framework. Sci Rep 16, 15074 (2026). https://doi.org/10.1038/s41598-026-44870-1
Mots-clés: détection de voies 3D, conduite autonome, vision monoculaire, modèles d’espace d’état, vision par ordinateur