Clear Sky Science · pl
Udoskonalone wykrywanie zagrożeń cyberbezpieczeństwa z wykorzystaniem nowych tri-metaheurystycznych funkcji straty w generatywnych sieciach przeciwstawnych z adaptacyjnym zachowaniem uwagi dla augmentacji ruchu sieciowego
Dlaczego mądrzejsza obrona cybernetyczna ma znaczenie
Za każdym razem, gdy przeglądasz sieć, robisz zakupy online lub łączysz urządzenie w domu, w tle toczą się ciche starcia, gdy systemy bezpieczeństwa próbują wyłowić złośliwy ruch spośród miliardów nieszkodliwych połączeń. Atakujący nieustannie wymyślają nowe sztuczki, podczas gdy obrońcy borykają się z niewielką liczbą przykładów prawdziwych ataków i rosnącymi kosztami energii wynikającymi z coraz większych modeli AI. Artykuł bada sposób na jednoczesne wzmocnienie obron cyfrowych i ograniczenie zużycia energii potrzebnej do ich trenowania przez nauczenie wyspecjalizowanego modelu generatywnego tworzenia realistycznych, zróżnicowanych „ćwiczebnych ataków” dla systemów wykrywania włamań — nie przez wynajdywanie zupełnie nowych algorytmów, lecz poprzez połączenie i adaptację sprawdzonych pomysłów w starannie zaprojektowany sposób.
Tworzenie bardziej realistycznych danych do ćwiczeń
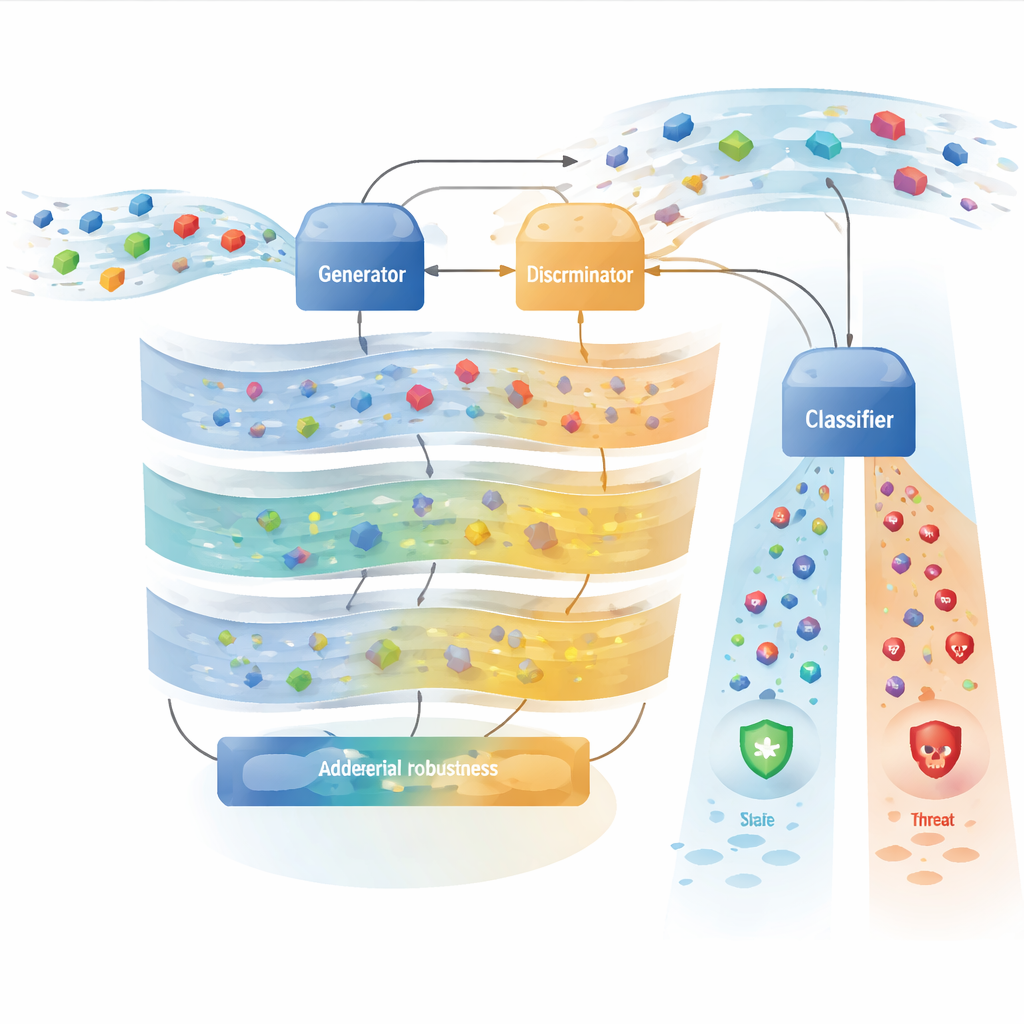
Nowoczesne systemy obrony cybernetycznej często polegają na systemach uczenia głębokiego, które skanują ruch sieciowy pod kątem śladów włamań. Systemy te osiągają najlepsze wyniki, gdy są trenowane na wielu przykładach zarówno normalnego zachowania, jak i ataków. W praktyce normalny ruch znacznie przewyższa liczebnie ruch niebezpieczny, a niektóre typy ataków są wyjątkowo rzadkie, więc modele mają tendencję do ich pomijania. Autorzy wykorzystują rodzaj modelu generatywnego, Generative Adversarial Network (GAN), aby wygenerować syntetyczny ruch atakujący, który wygląda i zachowuje się jak prawdziwe ataki. Zamiast polegać na jednej regule straty kierującej uczeniem, projektują ramy z trzema składnikami straty, które zachęcają generator do zachowania cech naprawdę istotnych przy rozróżnianiu ataków, utrzymania realistycznych statystyk ruchu i zachowania szerokiej różnorodności wzorców ataków. Efektem jest bogatszy, bardziej zrównoważony zestaw treningowy dla systemów wykrywania włamań.
Czerpanie pomysłów z natury, zrealizowane w matematyce
Ramę inspirują trzy rodziny tzw. metod metaheurystycznych nazwanych od świetlików, meduz i krewetek modliszkowych. Klasyczne wersje tych algorytmów są oparte na populacjach i niedyferencjowalne, co czyni je słabo dopasowanymi do współczesnego uczenia głębokiego. Tutaj autorzy nie uruchamiają tych algorytmów bezpośrednio. Zamiast tego przekładają zasadnicze pomysły projektowe na gładkie, dyferencjowalne składniki funkcji straty, które można optymalizować standardowym wstecznym przekazywaniem błędu. Jedna grupa składników, inspirowana zachowaniem „świetlików”, zachęca syntetyczny ruch do dopasowania się do ważnych cech ataku i odwzorowania rozkładu statystycznego prawdziwych danych. Inna grupa, wzorowana na ławicach „meduz”, popycha wewnętrzne reprezentacje podobnych ataków do grupowania się, a różnych ataków do rozdzielania, przy stopniowym zwiększaniu trudności zadania w trakcie treningu. Trzeci zestaw, koncepcyjnie związany z precyzją „krewetek modliszkowych”, koncentruje się na odporności — zapewniając, że generowane ataki pozostaną wykrywalne nawet po drobnych, adwersarialnych modyfikacjach.
Oszczędzanie energii dzięki ukierunkowanej uwadze
Ponadto autorzy zajmują się coraz palącym problemem: energią potrzebną do trenowania dużych modeli bezpieczeństwa. Centra danych już zużywają 1–2% globalnej energii elektrycznej, a monitorowanie bezpieczeństwa działa non-stop. Aby zmniejszyć ten koszt, rama zawiera mechanizm uwagi z uwzględnieniem zużycia energii. Zamiast poświęcać równą ilość obliczeń na każdy przepływ sieciowy, lekki moduł oceniający szacuje, jak podejrzany jest dany przykład. Wysoce podejrzane przepływy otrzymują pełną, wysokorozdzielczą uwagę i arytmetykę o wysokiej precyzji; umiarkowanie podejrzane — średnią uwagę; ruch ewidentnie nieszkodliwy jest przetwarzany z mniejszą liczbą głów uwagi, krótszymi sekwencjami i niższą precyzją numeryczną. Dodatkowe techniki rozrzedzają wagi uwagi i skracają okno kontekstu dla ruchu nieszkodliwego. Te wybory projektowe obniżają zużycie energii podczas treningu o około 40% w eksperymentach autorów, przy zachowaniu wydajności wykrywania ruchu atakującego.
Próby systemu
Zespół ocenia swoje podejście na siedmiu powszechnie używanych zbiorach danych do wykrywania włamań obejmujących sieci korporacyjne, testowe środowiska chmurowe i Internet rzeczy, pokrywając wszystko od zalewów typu denial-of-service po skryte próby infiltracji. Trenują kilka klasyfikatorów uczenia głębokiego na trzech rodzajach danych: oryginalnych, niezrównoważonych danych, danych wzbogaconych standardowymi metodami, takimi jak SMOTE, oraz danych wzbogaconych za pomocą ich augmentacji opartej na GAN. Dzięki nowej ramie detektor oparty na transformerze osiąga około 98,7% dokładności i wartość F1 równą 0,987 na benchmarku NSL-KDD, przewyższając wcześniejsze warianty GAN i baseline’y skupiające się na energooszczędności. Starannie przeprowadzone badania ablacją pokazują, że mniej więcej połowa poprawy wynika z podstawowego wyrównania klas i tradycyjnej augmentacji, podczas gdy druga połowa wynika ze specyficznego połączenia składników straty i mechanizmów uwagi. System wykazuje również lepszą odporność przy ekspozycji na powszechne metody ataków adwersarialnych i potrafi relatywnie dobrze przenosić się między zbiorami danych bez pełnego ponownego trenowania.
Gdzie działa, a gdzie nadal ma trudności
Mimo tych zysków metoda nie jest cudownym rozwiązaniem. Autorzy wyraźnie przyznają, że niektóre typy ataków pozostają bardzo trudne do wykrycia — zwłaszcza powolne, skryte ataki infiltracyjne, gdzie czułość może spaść poniżej 30% nawet po augmentacji. Dodatkowo testy wdrożeniowe w rzeczywistych warunkach w pięciu organizacjach opierają się na zweryfikowanej „prawdzie ziemi” jedynie dla około 1,8% zebranych przepływów, co oznacza, że operacyjne oszacowania dokładności nadal są niepewne. Rama zależy także od relatywnie wydajnego sprzętu, takiego jak GPU NVIDIA A100, które mogą nie być dostępne w mniejszych organizacjach. Te zastrzeżenia podkreślają, że wyniki są obiecujące, ale ograniczone przez konkretne zbiory danych, sprzęt i procedury weryfikacyjne badane w pracy.
Co to oznacza dla codziennego bezpieczeństwa
Mówiąc wprost, praca ta sugeruje, że staranne zintegrowanie kilku dobrze znanych sztuczek uczenia głębokiego — zamiast wynajdywania zupełnie nowych — może dać system cyberbezpieczeństwa, który jednocześnie wykrywa więcej ataków i zużywa mniej energii do trenowania. Poprzez generowanie realistycznych syntetycznych ataków, które zachowują krytyczne wzorce, kierowanie procesu uczenia za pomocą wielu komplementarnych składników straty oraz dynamiczne skupianie mocy obliczeniowej tam, gdzie zagrożenia są najbardziej prawdopodobne, proponowana rama oferuje bardziej efektywny pod względem danych i środowiskowym sposób trenowania detektorów włamań. Poprawia wykrywanie na zbiorach benchmarkowych i wykazuje obiecującą odporność na unikające techniki atakujących, jednocześnie otwarcie przyznając się do słabych punktów w przypadku rzadkich, silnie zamaskowanych ataków. Dla użytkowników i organizacji podejścia takie zbliżają nas do narzędzi bezpieczeństwa, które są nie tylko mądrzejsze i bardziej odporne, ale też bardziej ekologiczne.
Cytowanie: Khalil, H.M., Elrefaiy, A., Elbaz, M. et al. Enhanced cybersecurity threat detection using novel tri-metaheuristic loss functions in generative adversarial networks with adaptive attention preservation for network traffic augmentation. Sci Rep 16, 12074 (2026). https://doi.org/10.1038/s41598-026-46375-3
Słowa kluczowe: wykrywanie włamań, generatywne sieci przeciwstawne, augmentacja ruchu sieciowego, odporność na ataki adwersarza, energooszczędna sztuczna inteligencja