Clear Sky Science · pl
Ulepszanie oceny edukacyjnej poprzez automatyczną klasyfikację pytań z użyciem zespołu modeli opartych na RoBERTa
Bardziej inteligentne testy dla nowoczesnych klas
Co roku nauczyciele tworzą tysiące pytań egzaminacyjnych, aby ocenić, jak dobrze uczniowie się uczą — nie tylko jakie fakty zapamiętują, ale jak głęboko potrafią myśleć. Rozróżnienie pytań sprawdzających proste przypomnienie od tych wymagających prawdziwego rozwiązywania problemów jest istotne, lecz wykonywane ręcznie jest powolne i często niespójne. W artykule przedstawiono system sztucznej inteligencji, który automatycznie sortuje pytania egzaminacyjne według stopnia trudności myślenia, obiecując sprawiedliwsze testy i więcej czasu na nauczanie.

Dlaczego poziomy myślenia mają znaczenie
Przez dekady nauczyciele opierali się na ramie zwanej Taksonomią Blooma przy projektowaniu lekcji i egzaminów. Opisuje ona sześć poziomów myślenia — od przypominania podstawowych faktów, przez rozumienie, stosowanie, analizowanie i ocenianie, aż po tworzenie czegoś nowego. Dobry egzamin powinien obejmować to pełne spektrum, zamiast skupiać się wyłącznie na najłatwiejszych poziomach. Klasyfikacja każdego pytania jako należącego do jednego z poziomów jest jednak oceną subiektywną i nauczyciele mogą się nie zgadzać. Automatyzacja tego kroku może uczynić ocenianie bardziej obiektywnym i szybko pokazać, czy test naprawdę angażuje umysły uczniów, a nie tylko sprawdza pamięć.
Nauczanie maszyny rozumienia pytań egzaminacyjnych
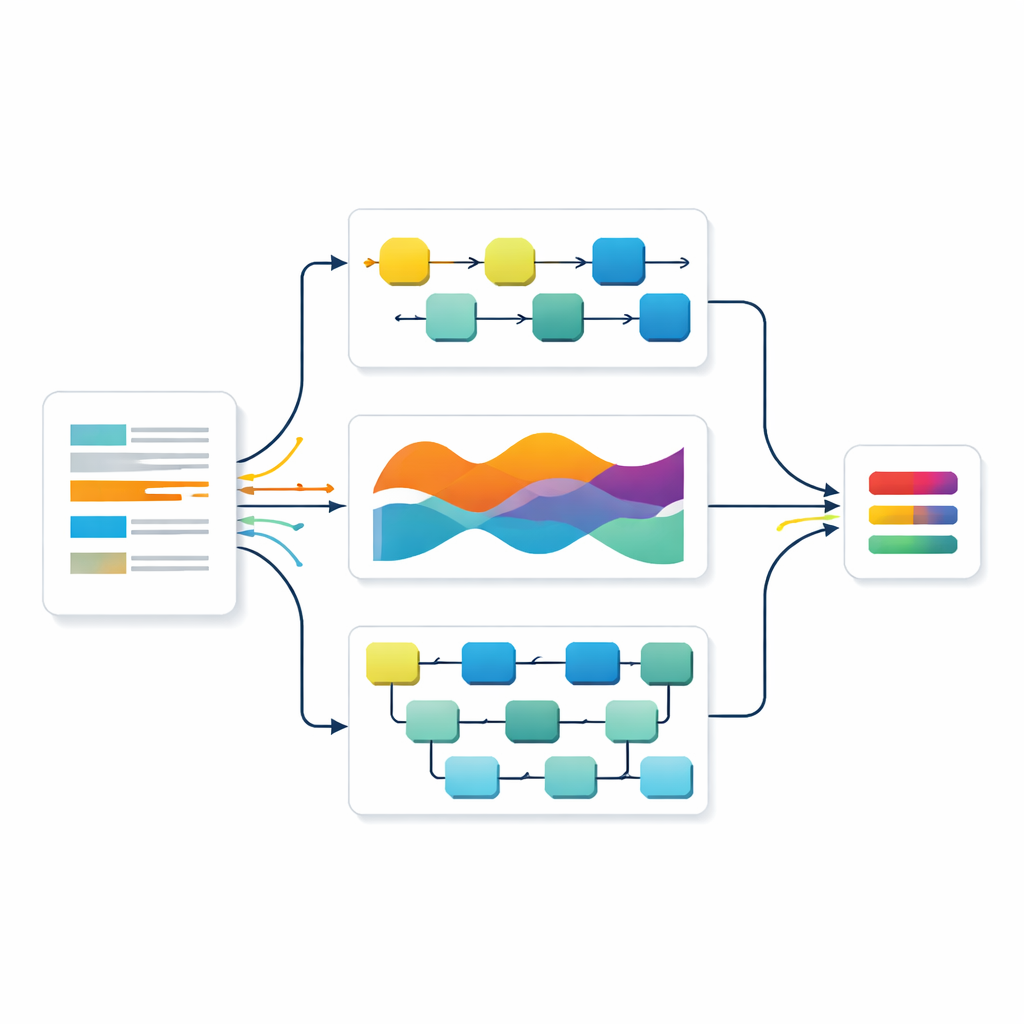
Autorzy zbudowali system w oparciu o potężny model językowy o nazwie RoBERTa, trenowany na ogromnych zbiorach tekstu, by uchwycić subtelne znaczenia. Gdy model czyta pytanie egzaminacyjne, konwertuje każde słowo na bogatą reprezentację numeryczną odzwierciedlającą jego relacje z otaczającymi słowami. Te reprezentacje trafiają następnie do trzech wyspecjalizowanych sieci neuronowych. Jedna koncentruje się na tym, jak informacja rozwija się wzdłuż kolejności wyrazów, druga śledzi długoterminowe wzorce, a trzecia wyszukuje kluczowe lokalne frazy. Razem uczą się rozpoznawać formułowania sygnalizujące, czy pytanie wymaga od ucznia przypomnienia, wyjaśnienia, zastosowania czy tworzenia nowego rozwiązania.
Łączenie różnych perspektyw AI
Zamiast polegać na pojedynczej sieci, badacze połączyli wszystkie trzy, stosując strategię zapożyczoną z systemów głosowania. Każdy model daje własne przypuszczenie co do poziomu pytania oraz miarę pewności. Te przewidywania są następnie uśredniane, lecz nie równomiernie — modele, które okazały się dokładniejsze na oddzielnym zbiorze walidacyjnym, otrzymują większą wagę. Takie podejście „ważonego zespołu” pozwala mocnym stronom jednego modelu zrównoważyć słabości innego. Zespół starannie przygotował też dane, rozszerzając publiczny zbiór pytań egzaminacyjnych o starannie sprawdzone parafrazy, aby system mógł uczyć się na większej liczbie przykładów bez wprowadzania szumów.
Jak dobrze to działa?
Na wydzielonym zbiorze testowym, którego modele nie widziały podczas treningu, każda z trzech indywidualnych sieci sklasyfikowała pytania z dokładnością powyżej 90 procent, już przewyższając wiele wcześniejszych metod opisanych w literaturze. Połączony zespół radził sobie jeszcze lepiej, poprawnie oznaczając około 92 procent pytań i utrzymując zrównoważone wyniki we wszystkich sześciu poziomach myślenia, w tym na bardziej zaawansowanych. Test statystyczny potwierdził, że ta poprawa w stosunku do najlepszego pojedynczego modelu była mało prawdopodobna do przypisania przypadkowi. Szczegółowe analizy błędów wykazały, że zespół zredukował zamieszanie między sąsiednimi poziomami myślenia, które często są najtrudniejsze do odróżnienia także dla ludzi.
Co to znaczy dla nauczycieli i uczniów
Automatyczne sortowanie pytań egzaminacyjnych według poziomów myślenia może pomóc nauczycielom szybko sprawdzić, czy ich testy rzeczywiście mierzą szeroki zakres umiejętności — od podstawowego przypomnienia po kreatywne rozwiązywanie problemów. System może wskazywać luki — na przykład gdy egzamin zawiera zbyt wiele łatwych pytań i zbyt mało tych pobudzających głębsze rozumowanie — oraz pomagać szkołom projektować bardziej spójne oceny w dłuższej perspektywie. Narzędzie nie zastąpi profesjonalnego osądu, ale oferuje szybki, oparty na dowodach punkt wyjścia, który zmniejsza obciążenie pracą i ludzkie uprzedzenia. Patrząc w przyszłość, autorzy planują integrować takie systemy z platformami e‑learningowymi oraz rozszerzać je o nowe rodzaje umiejętności, które będą miały znaczenie w epoce, gdy uczniowie coraz częściej będą współpracować z AI.
Cytowanie: Hamid, M., Malik, S., Saleem, M. et al. Enhancing educational assessment through automated question classification using a RoBERTa-based ensemble model. Sci Rep 16, 13754 (2026). https://doi.org/10.1038/s41598-026-45486-1
Słowa kluczowe: ocena edukacyjna, Taksonomia Blooma, automatyczna klasyfikacja pytań, uczenie głębokie w edukacji, modele językowe