Clear Sky Science · es
Mejorar la evaluación educativa mediante la clasificación automatizada de preguntas con un modelo en conjunto basado en RoBERTa
Exámenes más inteligentes para las aulas modernas
Cada año, los docentes redactan miles de preguntas de examen para medir cuánto están aprendiendo los alumnos—no solo qué hechos recuerdan, sino cuán profundamente pueden pensar. Decidir qué preguntas evalúan la mera memoria y cuáles requieren un verdadero razonamiento es importante; sin embargo, hacerlo a mano es lento y con frecuencia inconsistente. Este artículo presenta un sistema de inteligencia artificial que puede clasificar automáticamente las preguntas de examen según la exigencia que plantean a las habilidades de pensamiento de los estudiantes, prometiendo pruebas más justas y más tiempo para la enseñanza.

Por qué importan los niveles de pensamiento
Durante décadas, los educadores han confiado en un marco conocido como la Taxonomía de Bloom para orientar lecciones y exámenes. Describe seis niveles de pensamiento, desde recordar hechos básicos pasando por comprender, aplicar, analizar y evaluar, hasta crear algo nuevo. Un buen examen debería cubrir todo este espectro en lugar de agruparse en los niveles más fáciles. Pero clasificar cada pregunta en uno de estos niveles es una decisión subjetiva, y distintos docentes pueden discrepar. Automatizar este paso puede hacer las evaluaciones más objetivas y revelar rápidamente si un examen realmente desafía la mente de los estudiantes en lugar de limitarse a comprobar la memoria.
Enseñar a una máquina a leer preguntas de examen
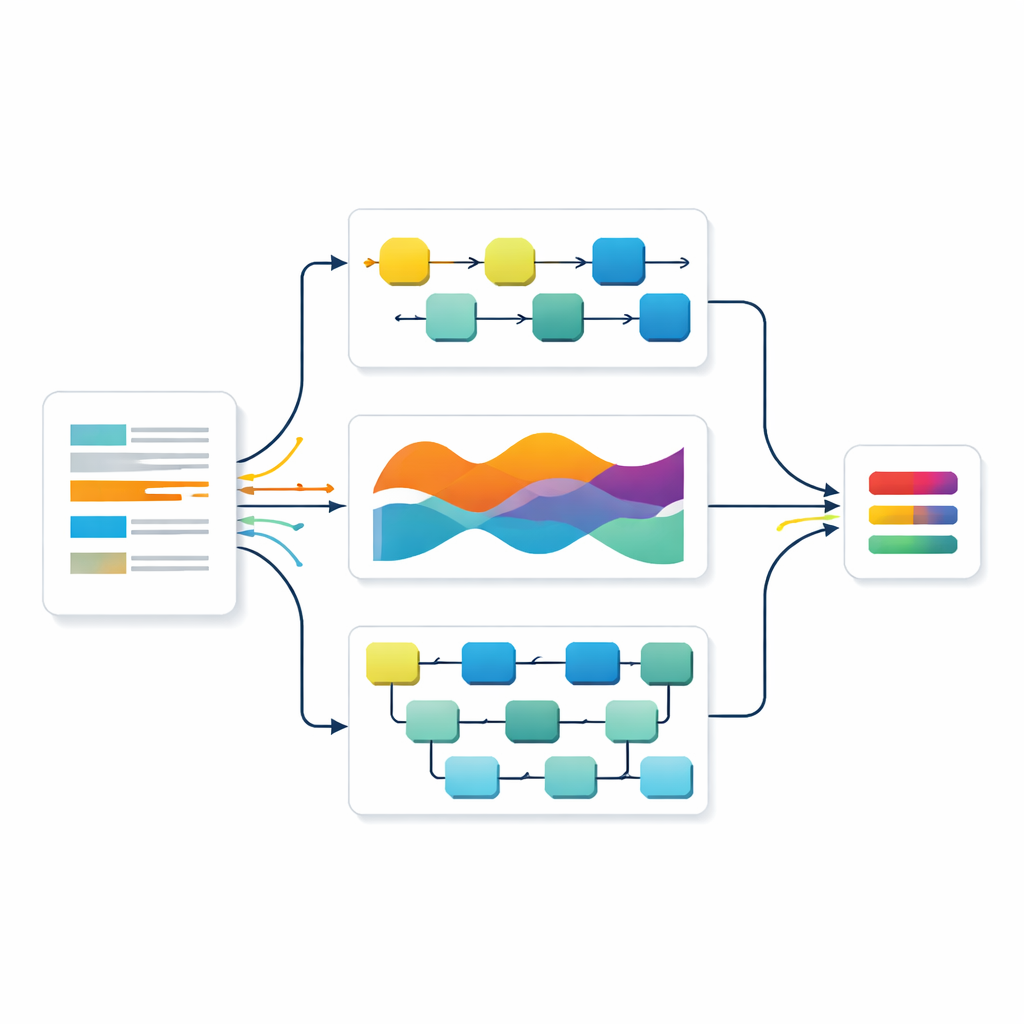
Los autores construyeron su sistema sobre un potente modelo de lenguaje llamado RoBERTa, entrenado con enormes cantidades de texto para capturar matices del significado. Cuando el modelo procesa una pregunta de examen, convierte cada palabra en una rica representación numérica que refleja cómo se relaciona con las palabras que la rodean. Estas representaciones se introducen luego en tres redes neuronales especializadas. Una se centra en cómo se desarrolla la información a lo largo de la frase en orden, otra sigue patrones a largo plazo y una tercera busca frases locales clave. Juntas, aprenden a detectar los tipos de redacción que señalan si una pregunta pide a los estudiantes recordar, explicar, aplicar o innovar.
Mezclando diferentes perspectivas de la IA
En lugar de confiar en una sola red, los investigadores combinaron las tres usando una estrategia tomada de los sistemas de votación. Cada modelo produce su propia predicción sobre el nivel de una pregunta, junto con una medida de confianza. Estas predicciones se promedian, pero no por igual: los modelos que muestran mayor precisión en un conjunto de validación separado reciben más peso. Este enfoque de "conjunto ponderado" permite que las fortalezas de un modelo compensen las debilidades de otro. El equipo también preparó sus datos de forma rigurosa, ampliando un conjunto de datos público de preguntas de examen con paráfrasis cuidadosamente verificadas para que el sistema pudiera aprender de más ejemplos sin introducir ruido.
¿Qué tan bien funciona?
En un conjunto de prueba reservado que los modelos nunca vieron durante el entrenamiento, las tres redes individuales clasificaron preguntas con más del 90 por ciento de exactitud, superando ya a muchos enfoques anteriores en la literatura. El conjunto combinado funcionó aún mejor, etiquetando correctamente alrededor del 92 por ciento de las preguntas y manteniendo un rendimiento equilibrado en los seis niveles de pensamiento, incluidos los más avanzados. Una prueba estadística confirmó que esta mejora respecto al mejor modelo individual probablemente no se debía al azar. Análisis detallados de los errores mostraron que el conjunto redujo la confusión entre niveles adyacentes de pensamiento, que a menudo son los más difíciles de separar también para los humanos.
Qué significa esto para docentes y estudiantes
Al clasificar automáticamente las preguntas de examen por niveles de pensamiento, este sistema podría ayudar a los docentes a comprobar rápidamente si sus pruebas realmente miden una variedad de habilidades, desde la memoria básica hasta la resolución creativa de problemas. Puede señalar lagunas—por ejemplo, si un examen contiene demasiadas preguntas fáciles y muy pocas que fomenten un razonamiento más profundo—y puede ayudar a las escuelas a diseñar evaluaciones más coherentes a lo largo del tiempo. Aunque la herramienta no sustituye el juicio profesional, ofrece un punto de partida rápido y basado en evidencia que reduce la carga de trabajo y el sesgo humano. Mirando al futuro, los autores planean integrar estos sistemas en plataformas de aprendizaje en línea y extenderlos a nuevos tipos de habilidades que serán relevantes en una época en la que los estudiantes trabajarán cada vez más junto a la IA.
Cita: Hamid, M., Malik, S., Saleem, M. et al. Enhancing educational assessment through automated question classification using a RoBERTa-based ensemble model. Sci Rep 16, 13754 (2026). https://doi.org/10.1038/s41598-026-45486-1
Palabras clave: evaluación educativa, Taxonomía de Bloom, clasificación automatizada de preguntas, aprendizaje profundo en educación, modelos de lenguaje