Clear Sky Science · pl
Optymalizacja strukturalna cząsteczek leków za pomocą językowych modeli trenowanych przyrostowo
Nauczanie komputerów majsterkowania przy lekach
Współczesne leki często zaczynają się jako obiecujące, lecz niedoskonałe cząsteczki, które chemicy muszą mozolnie poprawiać, aby stały się bezpiecznymi i skutecznymi lekami. W pracy tej pokazano, jak system sztucznej inteligencji, który „czyta” wzory chemiczne jak język, może samodzielnie przeprowadzać część takich poprawek, proponując nowych kandydatów na leki o aktywności przewyższającej najlepsze znane przykłady — bez polegania na zewnętrznych narzędziach oceniających czy na metodach prób i błędów opartych na zgadywaniu.
Dlaczego optymalizacja cząsteczek leków jest tak trudna
Gdy badacze znajdą wstępną cząsteczkę oddziałującą na cel biologiczny, zaczyna się prawdziwa praca: przekształcenie tego wczesnego „hitu” w coś silnego, selektywnego i nadającego się na lek. Tradycyjnie chemicy projektują dziesiątki lub setki bliskich krewnych pierwotnej struktury, syntezują je w laboratorium i testują każdy z osobna. Te cykle projektuj–wykonaj–testuj wymagają lat doświadczenia i dużych nakładów eksperymentalnych. Metody komputerowe próbowały pomagać, ale wiele z nich koncentruje się na prostych właściwościach, takich jak lipofilność związku, zamiast na pełnym biologicznym efekcie. Inne podejścia polegają na oddzielnych narzędziach predykcyjnych („wyroczniach”), które oceniają aktywność i mogą być zawodnym lub niedostępnym źródłem dla wielu celów.
Używanie chemicznych zdań do prowadzenia projektowania
Autorzy bazują na modelach języka chemicznego, rodzaju systemu głębokiego uczenia, który traktuje cząsteczki jako ciągi znaków (SMILES) i uczy się „gramatyki” oraz wzorców czyniących strukturę chemicznie sensowną i biologicznie interesującą. Najpierw wstępnie trenują model na setkach tysięcy znanych bioaktywnych cząsteczek, jednocześnie celowo filtrując wszystko, co związane z konkretnymi celami, które będą później badane. To daje modelu ogólnemu zrozumienie chemii, ale bez uprzedniej wiedzy o wybranych receptorach, co zapewnia, że późniejsze sukcesy rzeczywiście wynikają z nowego treningu, a nie z ukrytych uprzedzeń w danych startowych.
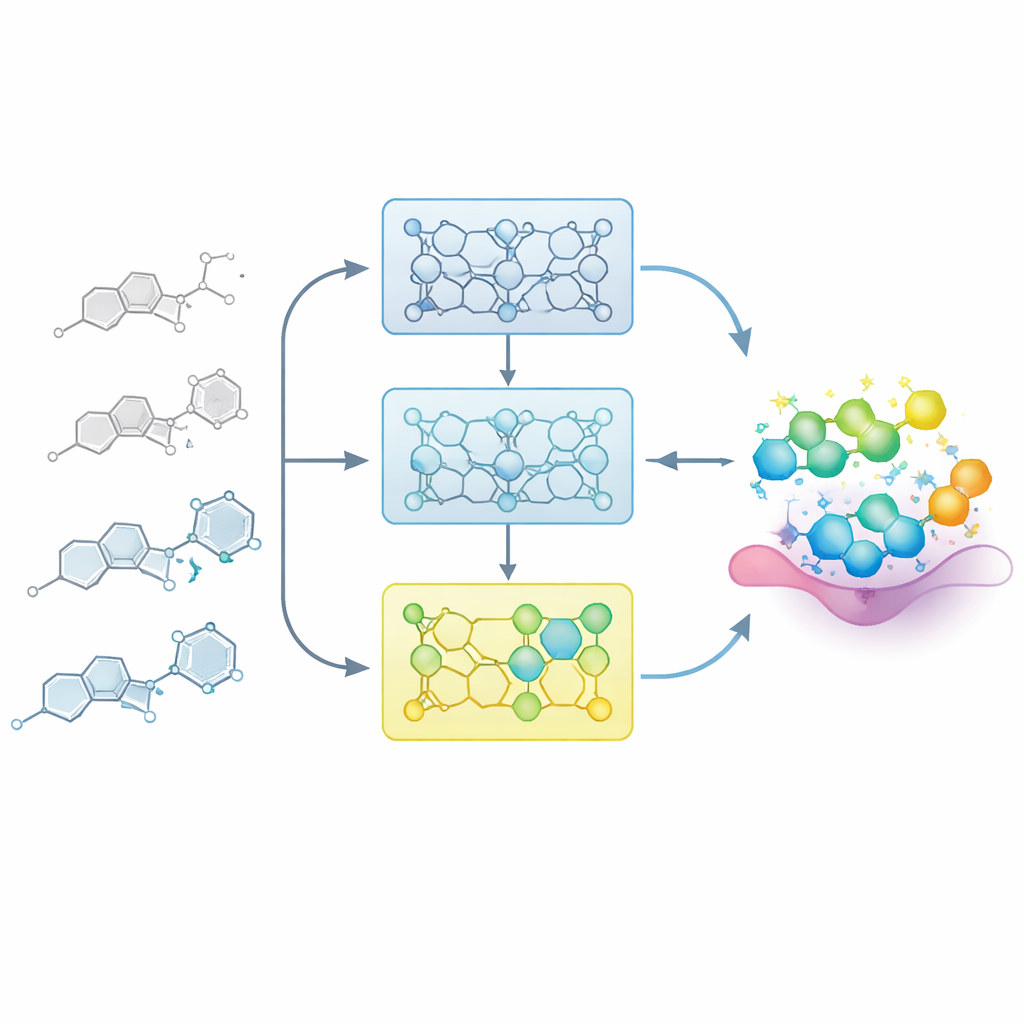
Pozwalanie modelowi uczyć się jak chemik medyczny
W rzeczywistych projektach lekowych chemicy stopniowo budują mapę między strukturą a aktywnością: małe zmiany rdzenia mogą osłabić lub wzmocnić związek. Badacze naśladują ten proces, podając modelowi starannie uporządkowane serie powiązanych cząsteczek, zwane seriami relacji struktura–aktywność (SAR). Zamiast dostrajać model jednorazowo na wszystkich znanych przykładach, dzielą każdą serię na kroki według mocy działania, od słabszych do silniejszych członków. Model najpierw jest wystawiany na mniej aktywne związki, a następnie kolejno dostrajany podzbiorami zawierającymi coraz silniejsze przykłady. To „przyrostowe trenowanie” tworzy trajektorię uczenia, w której model jest łagodnie kierowany w stronę regionu przestrzeni chemicznej, gdzie leżą najlepsze cząsteczki.
Od teorii do nowych, silniejszych kandydatów na leki
Aby sprawdzić, czy ta strategia trenowania rzeczywiście pomaga, zespół najpierw testuje, czy model potrafi „odkryć na nowo” wysoce aktywne związki celowo wyłączone z treningu. Przy trenowaniu przyrostowym model generuje projekty na wysokich pozycjach, które pasują do tych ukrytych silnych związków znacznie częściej niż modele trenowane jednorazowo, co wskazuje, że model zainternalizował wzorce napędzające wysoką aktywność. Autorzy przechodzą następnie do projektowania w warunkach rzeczywistych dla dwóch celów medycznie istotnych: PPARγ, zaangażowanego w metabolizm i zapalenie, oraz RORγ, powiązanego z regulacją odporności. Po przyrostowym trenowaniu na znanych ligandach dla każdego celu, model proponuje nowe analogi wybranych szkieletów. Gdy kilka z tych związków zostaje zsyntezowanych i przetestowanych w laboratorium, wszystkie dziewięć projektów dla PPARγ okazuje się wysoce aktywnymi agonistami, z wieloma znacznie przewyższającymi poprzednio najlepszą cząsteczkę, a nowy projekt dla RORγ niemal osiąga aktywność na poziomie najsilniejszego znanego związku w swojej serii, przy czym jest strukturalnie odmienny.
Co to oznacza dla przyszłych leków
Pokazując, że model w stylu językowym potrafi nie tylko wymyślać cząsteczki, lecz także udoskonalać istniejące szkielety tak, aby przewyższały najlepsze znane przykłady — bez polegania na zewnętrznych narzędziach oceny — praca ta wskazuje nowy sposób prowadzenia chemii medycznej. Podejście przyrostowego trenowania pozwala modelowi przyswajać subtelne reguły relacji struktura–aktywność i ich dalekosiężne współzależności, a następnie rozszerzać je na nieodkryte obszary. Dla osób niebędących specjalistami kluczowy wniosek jest taki, że SI może teraz działać mniej jak generator losowych pomysłów, a bardziej jak cyfrowo wyszkolony asystent chemika, proponując ukierunkowane, testowalne ulepszenia obiecujących cząsteczek i potencjalnie przyspieszając drogę od wczesnych hitów do zoptymalizowanych leków.
Cytowanie: Hörmann, T., Mayer, D., Lewandowski, M. et al. Structural optimization of drug molecules with incrementally trained language models. Nat Commun 17, 3456 (2026). https://doi.org/10.1038/s41467-026-71591-w
Słowa kluczowe: model języka chemicznego, de novo projektowanie leków, relacje struktura–aktywność, chemia generatywna, Sztuczna inteligencja w chemii medycznej