Clear Sky Science · ar
التحسين البنيوي لجزيئات الأدوية باستخدام نماذج لغوية مدرَّبة تدريجياً
تعليم الحواسيب على العبث بالأدوية
تبدأ الأدوية الحديثة غالباً بجزيئات واعدة لكنها ناقصة تتطلب من الكيميائيين تعديلها بدقة لتصبح عقاقير آمنة وفعّالة. تُظهر هذه الدراسة كيفية قدرة نظام ذكاء اصطناعي «يقرأ» الصيغ الكيميائية كاللغة على تعلّم إجراء بعض هذه التعديلات بنفسه، مقترحاً مرشحين دوائيين جدد قد يكونون أقوى من أفضل الأمثلة المعروفة—دون الاعتماد على أدوات تقييم خارجية أو على تجارب محاولات وخطأ قائمة على التخمين.
لماذا يعد تحسين جزيئات الأدوية أمراً صعباً
عندما يجد الباحثون جزيئاً أولياً يؤثر على هدف بيولوجي، يبدأ العمل الحقيقي: تحويل تلك النواة الأولية إلى مركب قوي، انتقائي، ومناسب كدواء. تقليدياً، يصمم الكيميائيون عشرات أو مئات الأقارب القريبة من التركيب الأصلي، ويصنعونها في المختبر، ويختبرون كل واحد منها. تتطلب هذه دورات التصميم–الصنع–الاختبار سنوات من الخبرة وجهود تجريبية كبيرة. حاولت الطرق الحاسوبية المساعدة، لكن كثيراً منها يركز على خواص بسيطة مثل ذوبان الدهون بدلاً من التأثير البيولوجي الكامل. وتعتمد طرق أخرى على أدوات توقع منفصلة («أوراكلز») لتقدير النشاط، والتي قد تكون غير موثوقة أو غير متاحة للعديد من الأهداف.
استخدام الجمل الكيميائية لتوجيه التصميم
يبني المؤلفون عملهم على نماذج لغوية كيميائية، نوع من أنظمة التعلم العميق التي تعامل الجزيئات كسلاسل حروف (SMILES) وتتعلّم «قواعد» وأنماط تجعل التركيب معقولاً كيميائياً ومهماً بيولوجياً. أولاً، يقومون بعمل تدريب أولي للنموذج على مئات الآلاف من الجزيئات المعروفة بنشاطها البيولوجي، مع تصفية متعمدة لأي شيء ذي صلة بالأهداف المحددة التي سيدرسونها لاحقاً. ينتج عن ذلك نموذج عام يفهم الكيمياء لكنه لا يمتلك معرفة سابقة عن المستقبلات المختارة، مما يضمن أن أي نجاح لاحق ينبع فعلاً من التدريب الجديد الذي يتلقاه وليس من انحياز مخفي في بيانات البداية.
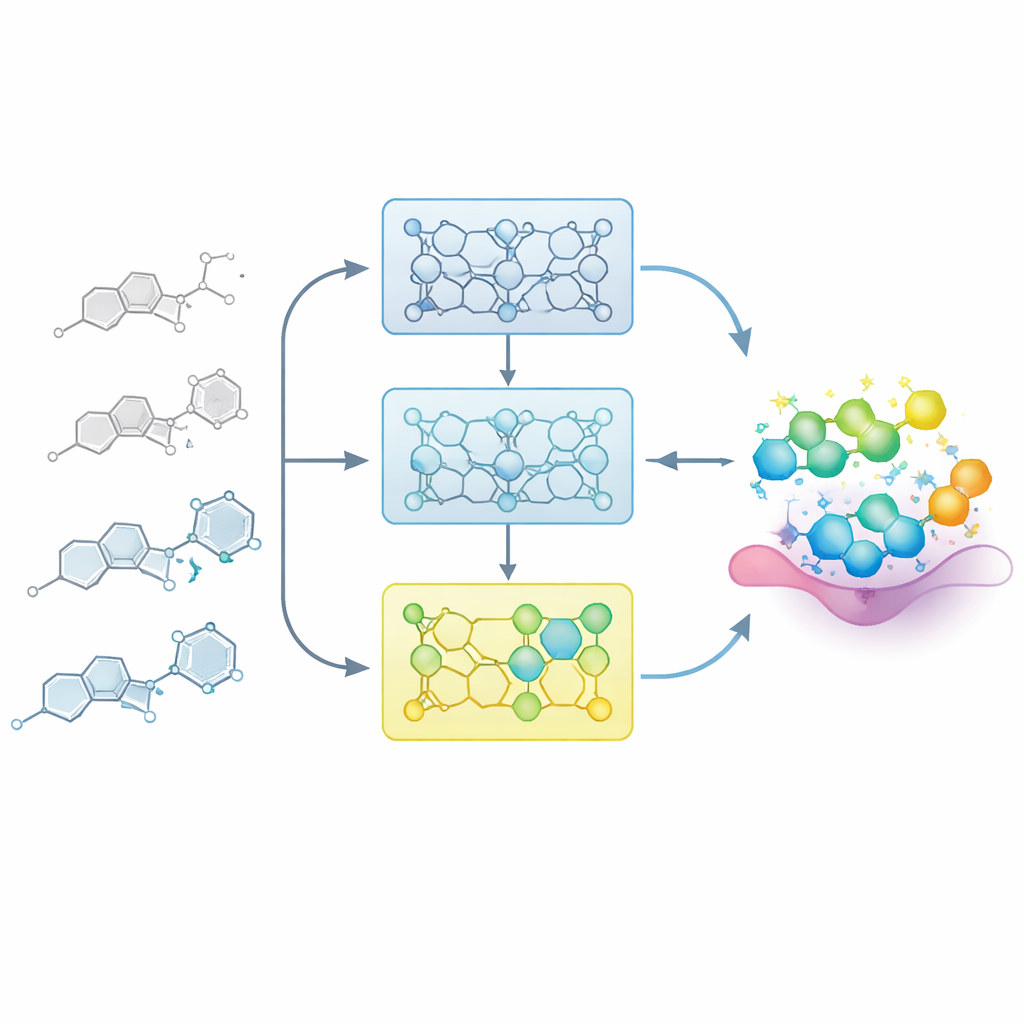
ترك النموذج يتعلم مثل كيميائي أدوياتي
في مشاريع الأدوية الواقعية، يبني الكيميائيون تدريجياً خريطة بين البنية والنشاط: تغييرات صغيرة في هيكل أساسي يمكن أن تجعل المركب أضعف أو أقوى. يحاكي الباحثون هذا المسار عبر تغذية النموذج بسلاسل مرتبة بعناية من الجزيئات المرتبطة، وتُدعى سلاسل علاقات البنية–النشاط (SAR). بدلاً من ضبط النموذج دفعة واحدة على جميع الأمثلة المعروفة، يقسمون كل سلسلة إلى خطوات بناءً على الفعالية، من الأعضاء الأضعف إلى الأقوى. يتعرّض النموذج أولاً للمركبات الأقل نشاطاً، ثم يتم ضبطه تدريجياً بمجموعات فرعية تحتوي على أمثلة أكثر قوة. يخلق هذا «التدريب المتدرج» مسار تعلم يوجّه النموذج بلطف نحو منطقة الفضاء الكيميائي حيث تكمن أفضل الجزيئات.
من النظرية إلى مرشحين دوائيين جدد وأقوى
لاختبار ما إذا كانت استراتيجية التدريب هذه مفيدة فعلاً، يتحقق الفريق أولاً مما إذا كان النموذج قادراً على «إعادة اكتشاف» جزيئات نشطة تم حجبها عمداً عن التدريب. مع التدريب المتدرج، يولّد النموذج تصميمات مرتّبة تصدرت النتائج وتطابقت مع هذه المركبات القوية المخفية أكثر بكثير من النماذج المدربة في خطوة واحدة، ما يدل على أنه استوعب الأنماط التي تقود النشاط العالي. ثم ينتقل المؤلفون إلى التصميم العملي لهدفين ذوي صلة طبية: PPARγ، المرتبط بالتمثيل الغذائي والالتهاب، وRORγ، المتورط في تنظيم المناعة. بعد التدريب المتدرج على الروابط المعروفة لكل هدف، يقترح النموذج نظائر جديدة للهيكليات الأساسية المختارة. عندما تم تحضير واختبار عدة من هذه في المختبر، كانت جميع التصاميم التسعة لـ PPARγ نّاشطات قوية بامتياز، وتجاوز الكثير منها المركب الأفضل السابق بفارق كبير، بينما اقترب تصميم جديد لـ RORγ من قوة أقوى مركب معروف في سلسلته مع كونه مختلفاً بنيوياً.
ماذا يعني هذا للأدوية المستقبلية
من خلال إظهار أن نموذجاً على نمط اللغة يمكنه ليس فقط ابتكار جزيئات بل أيضاً تحسين الهياكل القائمة لتتفوق على أفضل الأمثلة المعروفة—دون الاعتماد على أدوات تقييم خارجية—يشير هذا العمل إلى نهج جديد في كيمياء الأدوية. يتيح نهج التدريب المتدرج للنموذج استيعاب قواعد علاقات البنية–النشاط الدقيقة واعتمادياتها بعيدة المدى، ثم تمديدها إلى مناطق غير مستكشفة. للخارجين عن التخصص، الخلاصة الأساسية هي أن الذكاء الاصطناعي يمكنه الآن أن يتصرف بشكل أقل كمولّد أفكار عشوائية وأكثر كمساعد كيميائي مُدرَّب رقمياً، يقترح تحسينات مركزة وقابلة للاختبار للجزيئات الواعدة وقد يسرّع مسار التحول من الضربات الأولية إلى الأدوية المحسّنة.
الاستشهاد: Hörmann, T., Mayer, D., Lewandowski, M. et al. Structural optimization of drug molecules with incrementally trained language models. Nat Commun 17, 3456 (2026). https://doi.org/10.1038/s41467-026-71591-w
الكلمات المفتاحية: نماذج لغوية كيميائية, تصميم أدوية من الصفر, علاقات البنية–النشاط, كيمياء توليدية, الذكاء الاصطناعي في كيمياء الأدوية