Clear Sky Science · fr
Libérer le potentiel de la découverte de médicaments phénotypique par calcul : méthodes, défis et orientations futures
Pourquoi cette nouvelle manière de trouver des médicaments compte
La plupart des nouveaux médicaments échouent quelque part entre le laboratoire et la clinique, même après des années de travail et des coûts considérables. Cet article présente une alternative émergente appelée découverte de médicaments phénotypique, qui étudie comment des composés modifient le comportement de cellules ou d'organismes entiers plutôt que de cibler une seule molécule pré‑sélectionnée. Avec l'aide de l'intelligence artificielle et de vastes jeux de données biologiques, cette approche pourrait révéler des traitements pour des maladies complexes qui ont résisté aux méthodes traditionnelles.
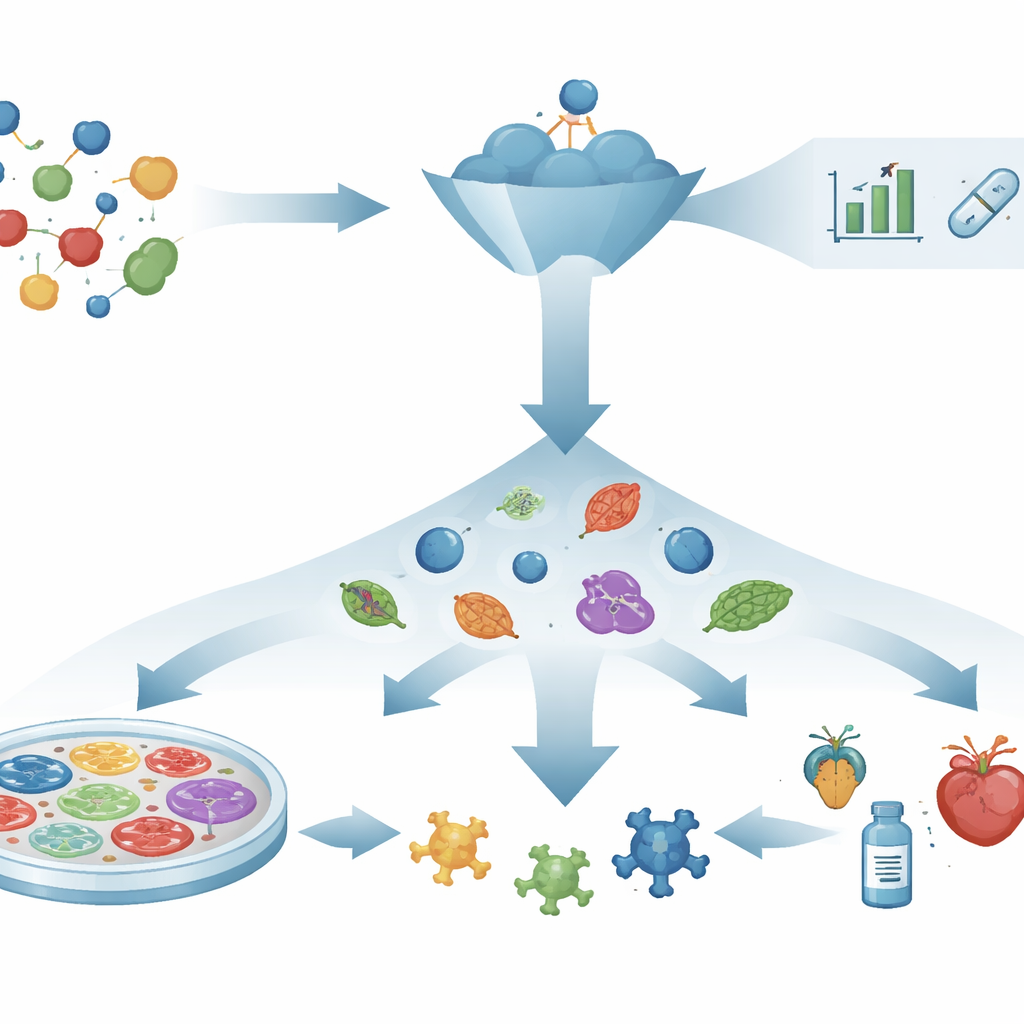
Du raisonnement « serrure‑clé » à l'observation des systèmes vivants
Pendant des décennies, la découverte de médicaments a suivi un script « mécanisme d'abord » : choisir une protéine unique considérée comme responsable de la maladie, concevoir ou rechercher des composés qui s'y lient, puis espérer que ces interactions se traduisent par des bénéfices cliniques. Des outils puissants comme la prédiction de structures protéiques, la conception assistée par ordinateur et le criblage virtuel ont accéléré cette recherche. Pourtant, de nombreuses cibles soigneusement choisies et molécules prometteuses n’aident pas les patients, car modifier une seule molécule ne suffit pas toujours à réparer un réseau de maladies complexe. Cet écart entre le succès en éprouvette et le succès chez l'humain a relancé l'intérêt pour des stratégies centrées sur ce qui se passe réellement dans les systèmes vivants.
Une approche « composé d'abord » pour repérer des changements bénéfiques
La découverte phénotypique renverse le raisonnement. Au lieu de partir d'une cible connue, elle pose une question plus directe : un composé ramène‑t‑il un système malade vers la santé ? Les chercheurs exposent des cellules, des tissus ou de petits organismes à de nombreux composés et recherchent des changements visibles ou mesurables, comme la restauration de la morphologie cellulaire, la survie de cellules fragiles ou le retour d'un comportement normal. Ce n'est qu'après l'observation d'un effet prometteur que les scientifiques enquêtent sur le mode d'action du composé à l'intérieur de la cellule. Cette approche agnostique par rapport à la cible a déjà conduit à des médicaments, par exemple pour la mucoviscidose et l'atrophie musculaire spinale, dont les mécanismes détaillés ont été élucidés ultérieurement. Elle est particulièrement utile pour les maladies impliquant de multiples voies simultanément, où choisir une seule cible « maîtresse » est irréaliste.
Transformer des lectures biologiques riches en chiffres
Les criblages phénotypiques modernes génèrent des quantités énormes de données : images haute résolution de cellules colorées, mesures d'activité génique, cartographies des modifications protéiques et même comportements d'organismes modèles. Pour donner du sens à cette complexité, le domaine s'appuie sur des « embeddings » — des méthodes qui convertissent la chimie, les images, l'expression génique et les réseaux d'interactions en empreintes numériques compactes. Ces empreintes captent des motifs dans l'apparence des médicaments, la manière dont ils modifient les cellules et leurs liens avec les gènes et les maladies. Des modèles d'apprentissage automatique, des algorithmes classiques aux réseaux neuronaux profonds et aux méthodes basées sur des graphes, apprennent ensuite à relier ces empreintes à des résultats tels que la toxicité, le bénéfice probable ou la similarité avec des médicaments connus. Dans certains cas, ils peuvent même suggérer de nouveaux composés ou de nouvelles indications pour des molécules existantes.
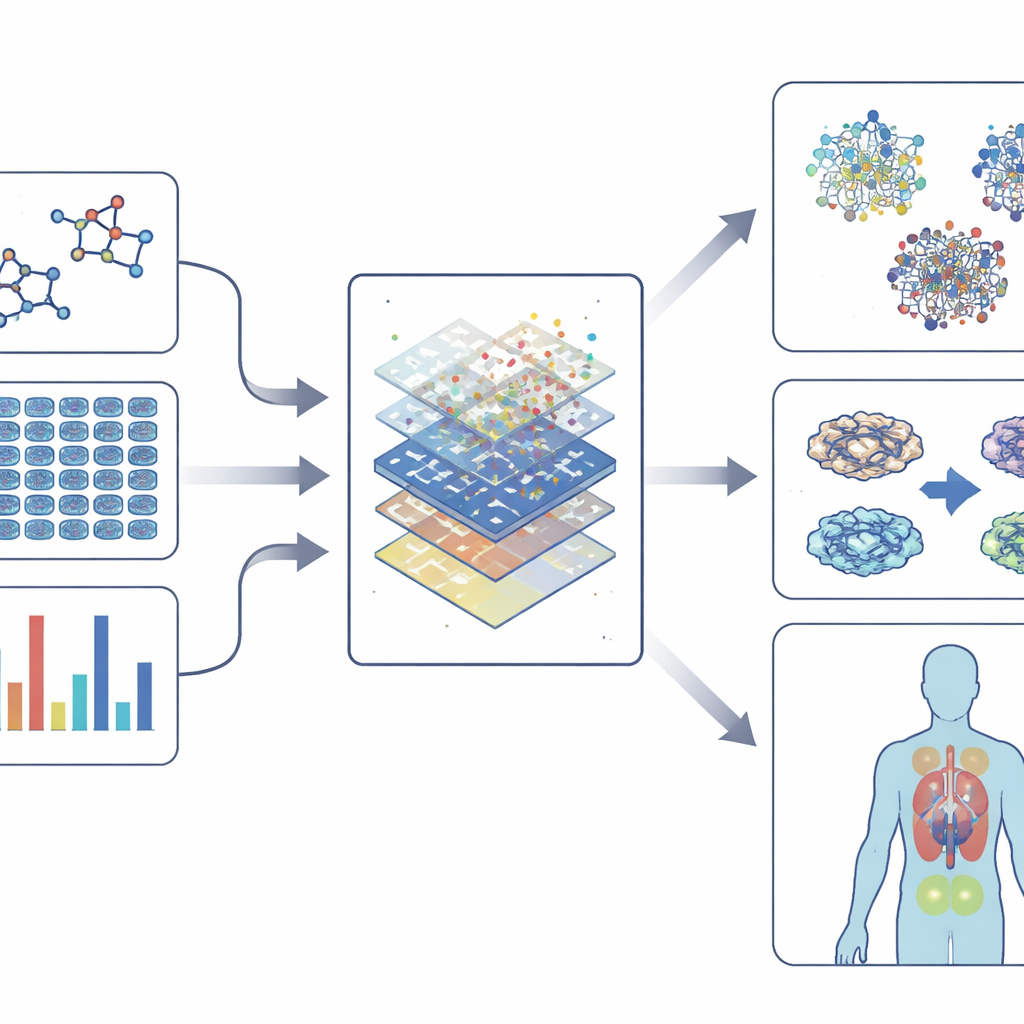
Utiliser des modèles plus intelligents tout en les rendant compréhensibles
À mesure que les modèles gagnent en puissance, ils risquent aussi de devenir plus opaques. Les outils d'IA explicable cherchent à ouvrir cette boîte noire en mettant en évidence les caractéristiques — par exemple des changements géniques particuliers ou des parties structurelles d'une molécule — qui motivent une prédiction. Cette transparence aide les chercheurs à faire confiance aux modèles, concevoir des composés plus sûrs et comprendre pourquoi un effet phénotypique se produit, et pas seulement constater qu'il existe. Parallèlement, les technologies unicellulaires et multi‑omiques permettent de voir comment différents types cellulaires dans un tissu répondent à un médicament, rapprochant le domaine de choix thérapeutiques plus personnalisés.
Obstacles sur la route vers de meilleurs médicaments
Malgré ses promesses, la découverte phénotypique de médicaments fait face à des défis importants. Les jeux de données de haute qualité restent fragmentaires et incohérents entre laboratoires, ce qui complique l'entraînement de modèles qui se généralisent bien. Les essais phénotypiques complexes peuvent être difficiles à reproduire, et passer d'un « hit » obtenu dans des cellules ou des animaux à une thérapie humaine sûre et efficace met souvent en lumière des défauts cachés. Démêler le mode d'action d'un hit phénotypique — le processus de déconvolution de la cible — peut être lent et incertain, surtout quand un composé agit sur plusieurs voies simultanément. Des études de cas de médicaments échoués ou repositionnés soulignent comment des mécanismes manquants ou mal compris peuvent conduire à des essais inutiles ou à des effets indésirables inattendus.
Vers où se dirige cette approche
L'article conclut que la véritable puissance de la découverte phénotypique viendra de la combinaison de modèles biologiques riches et de calculs avancés. Des cellules souches dérivées de patients, des mini‑organes tridimensionnels et une imagerie détaillée peuvent fournir des systèmes de test plus proches de l'humain, tandis que l'IA générative pourrait proposer des molécules adaptées à la correction de signatures de maladie spécifiques, même pour des maladies rares avec peu de données. Si les problèmes de qualité des données, de validation et d'identification des mécanismes peuvent être résolus, cette stratégie « composé d'abord », consciente des systèmes, pourrait rendre la découverte de médicaments plus rapide, plus efficace et davantage alignée sur le comportement réel des maladies chez les patients.
Citation: Kumar, S., Pal, A. & Chatterjee, S. Unlocking the potential of computational phenotypic drug discovery: methods, challenges, and future directions. npj Syst Biol Appl 12, 46 (2026). https://doi.org/10.1038/s41540-026-00676-5
Mots-clés: découverte de médicaments phénotypique, apprentissage automatique en découverte de médicaments, repositionnement de médicaments, dépistage à haut contenu, pharmacologie computationnelle