Clear Sky Science · zh
PatchCLIP:通过补丁嵌入损失实现区域特定的对比性病历与影像联合训练
胸片带来更智能的辅助
放射科医师每天都在读胸片,以发现如肺炎、胸腔积液或气胸等病变。人工智能已经能够在影像上提示“有异常”,但经常难以精确指出问题所在的位置。这项研究提出了Patch‑CLIP,一种新的人工智能方法,旨在不仅判断是否存在异常,还能在胸片上高亮其可能位置,并且所需的专家标注远少于传统系统。
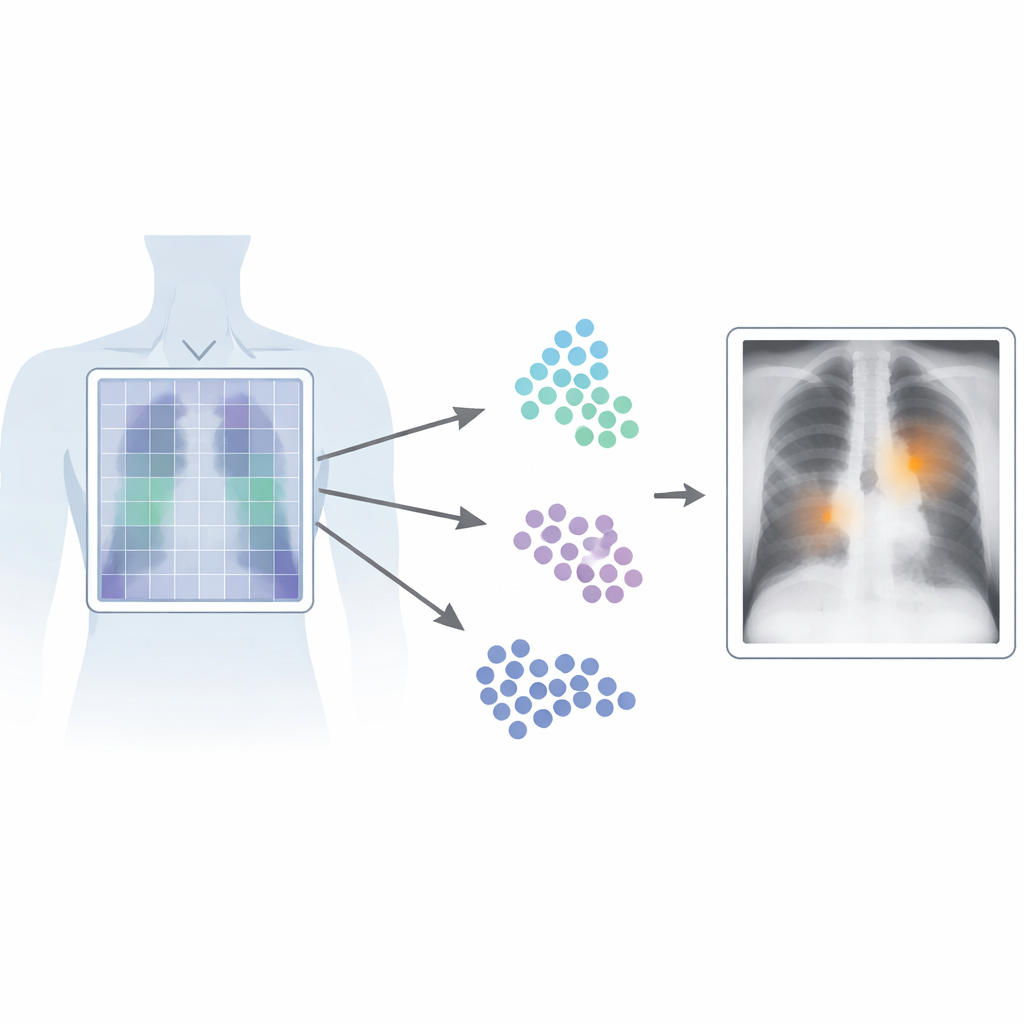
为何定位精确位置很重要
在医学影像中,时间和精确性至关重要。现有的视觉‑语言系统通过图像与随附报告的配对来学习,使其能在没有繁复像素级标注的情况下识别模式。然而,这些系统大多把整张图像当作一个整体来处理,只捕捉“总体印象”,却漏掉了细微信息。这在胸片上是个问题,因为一条细线或小阴影就可能标志着严重疾病。传统的高性能检测器通过在许多异常处训练精确绘制的框来克服这一点,但这种标注既昂贵又耗时,而且难以在不同放射科医师和医院之间标准化。
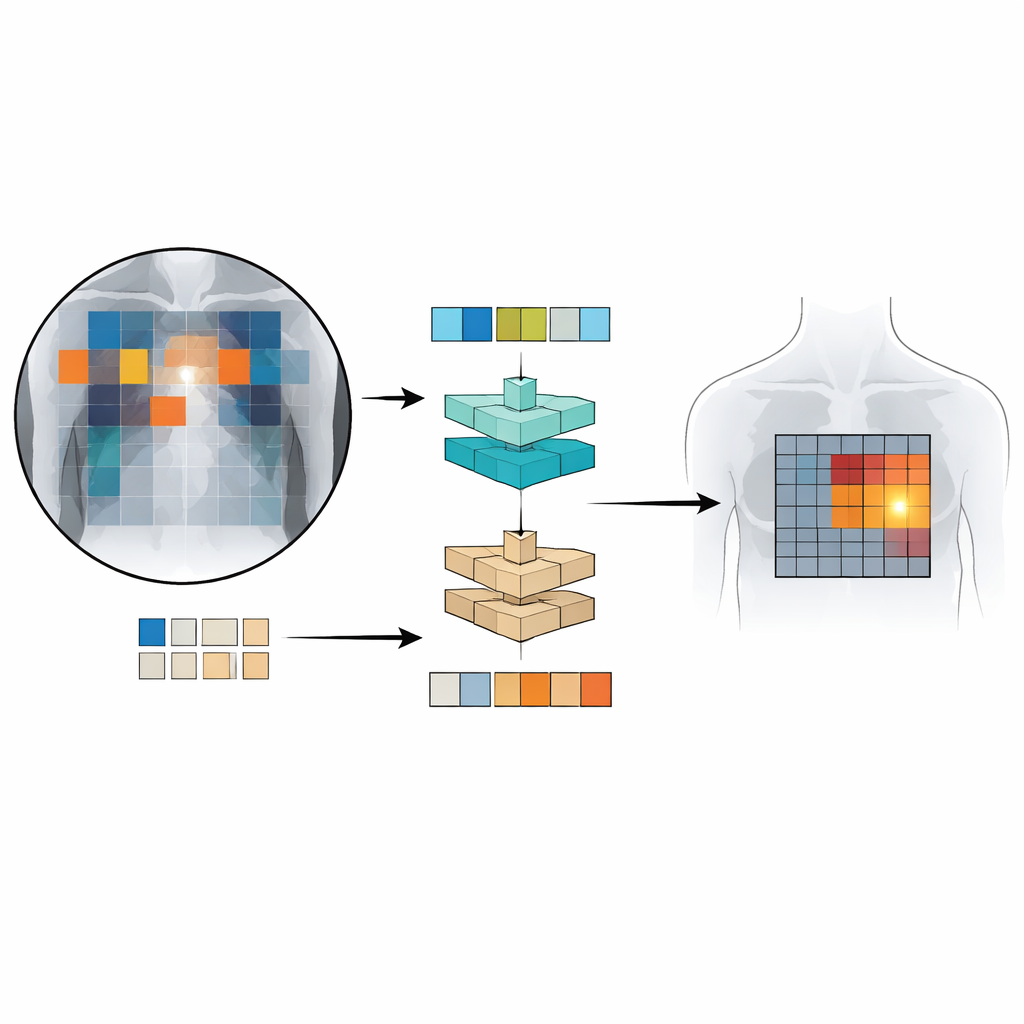
逐补丁查看胸片
Patch‑CLIP 建立在流行的 CLIP 框架之上,该框架联合学习图像和文本,并对其进行了扩展以更适合医疗需求。新方法不仅生成整张胸片的单一摘要,还将图像表示为小补丁的网格。每个补丁被映射到与描述医学发现(例如“肺积液”或“未见积液”)的文本相同的抽象空间。作者引入了额外的训练目标,鼓励相关补丁组表现得像局部检测器:与异常区域重叠的补丁在该抽象空间中被推动得更靠近描述该异常的文本,而来自健康区域的补丁则被拉向“未见异常”。
用更少的标注教会系统
为训练和测试 Patch‑CLIP,研究人员使用了若干大型的胸片与放射学报告配对的数据集,总计超过五十万张影像。大多数图像在训练中没有详细的人工标记;只有约 1.6 万张图像有专家绘制的异常框。首先,一个“下采样器”网络学习如何在保持重要细节的同时,将大尺寸医学影像缩到与标准视觉‑语言模型匹配的分辨率。然后,在对较小的专家注释集进行微调阶段时,新的基于补丁的损失教会模型将图像网格的特定部分与报告中的特定短语相关联。这样的设置使系统能够同时学习全局判断(“是否存在气胸?”)和粗略定位(“可能位于哪里?”)。
Patch‑CLIP 的表现如何?
团队将 Patch‑CLIP 与强大的商业胸片检测器以及最初为日常照片开发的先进视觉‑语言检测系统进行了比较。使用一种在灵敏度与每图像虚警次数之间权衡的临床评估指标,Patch‑CLIP 在多个肺和心脏相关发现上达到了或接近了最先进的性能。重要的是,Patch‑CLIP 生成的基于补丁的热图比标准注意力机制产生更少的伪高亮区域,后者往往会点亮大块无关区域。对于占据胸腔较大区域的病变(如液体积聚或心脏扩大),该方法的定位效果尤为显著。对于极小的病灶,其效果较弱——这些病灶可能落入单个补丁内——这提示更细的图像网格或改进的架构可能进一步提升性能。
这对未来医疗意味着什么
对非专业读者来说,关键是 Patch‑CLIP 更好地利用了日常临床实践中已经生成的文字报告,来教导人工智能系统在胸片上该看哪里。通过将文本描述与小图像区域对齐,它帮助计算机在需要较少专家详细标注的情况下既识别又粗略定位重要发现。它不会取代放射科医师,但这种方法可作为更可靠的“第二双眼睛”,在减少虚警的同时指示可疑区域。随着该方法扩展到更多疾病、更高分辨率的影像,乃至其他影像类型,它可能成为可扩展且可解释医疗人工智能的重要构件。
引用: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
关键词: 胸片人工智能, 医疗影像定位, 视觉-语言模型, 弱监督学习, 放射学计算辅助