Clear Sky Science · en
PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss
Smarter Help from Chest X‑Rays
Radiologists read chest X‑rays every day to spot conditions such as pneumonia, fluid around the lungs, or a collapsed lung. Artificial intelligence can already flag “something is wrong” on an image, but often struggles to point precisely to where the problem is. This study introduces Patch‑CLIP, a new AI method designed not only to say whether an abnormality is present, but also to highlight its likely location on the X‑ray, using far fewer expert annotations than traditional systems.
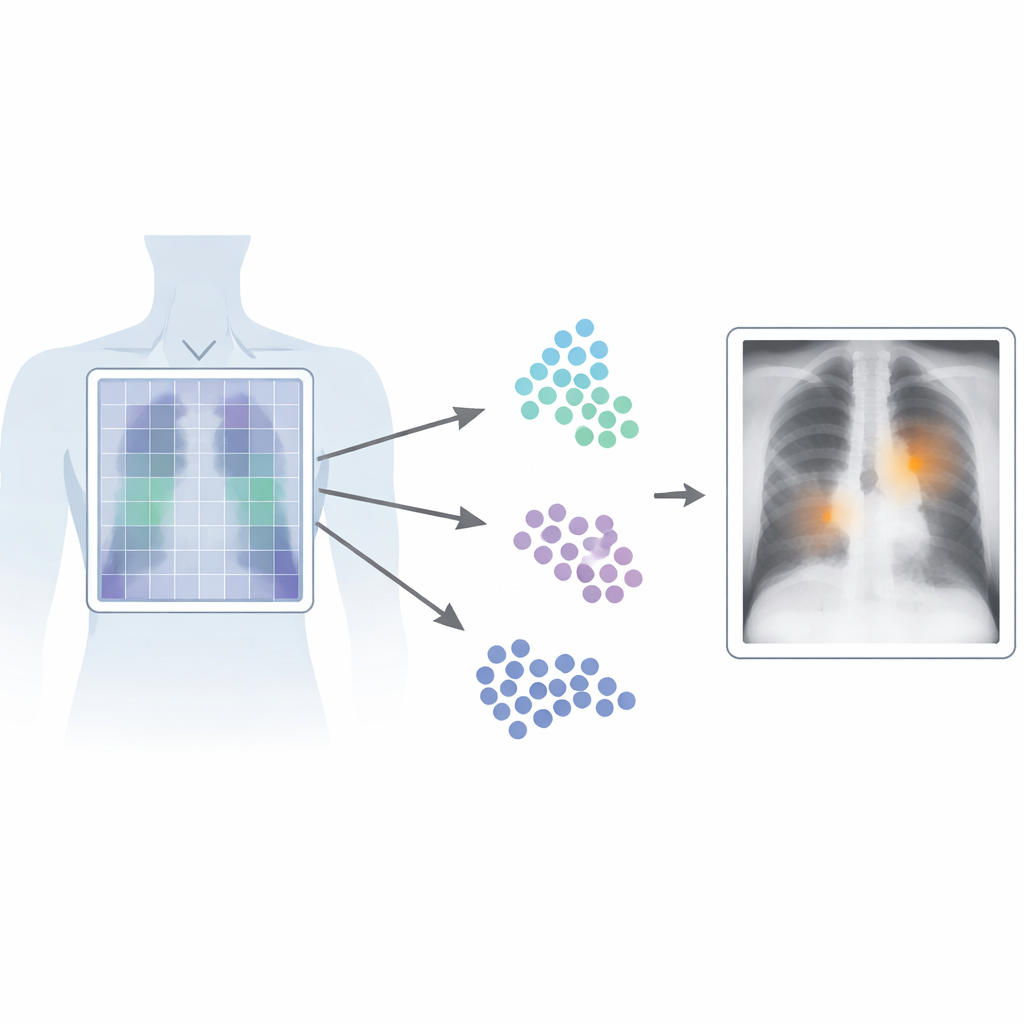
Why Finding the Exact Spot Matters
In medical imaging, time and precision are critical. Current vision‑language systems learn from pairs of images and accompanying reports, allowing them to recognize patterns without painstaking, pixel‑level labels from experts. However, most of these systems treat the image as a whole, capturing the “gist” but missing fine‑grained details. That is a problem for chest X‑rays, where a subtle line or small shadow can signal a serious condition. Conventional high‑performance detectors overcome this by training on many carefully drawn boxes around abnormalities, but this kind of labeling is expensive, slow, and difficult to standardize across radiologists and hospitals.
Looking at X‑Rays Patch by Patch
Patch‑CLIP builds on the popular CLIP framework, which jointly learns from images and text, and extends it in a way that is better suited to medical needs. Instead of just producing a single summary of the whole X‑ray, the new method also represents the image as a grid of small patches. Each patch is mapped into the same abstract space as the text that describes a medical finding, such as “fluid in the lung” or “no fluid.” The authors introduce extra training objectives that encourage groups of relevant patches to behave like local detectors: patches overlapping an abnormal region are pushed closer, in this abstract space, to the text describing that abnormality, while patches from healthy regions are pulled toward “no finding.”
Teaching the System with Fewer Labels
To train and test Patch‑CLIP, the researchers used several large collections of chest X‑rays paired with radiology reports, including more than half a million images. Most of these were used without detailed manual markings; only a subset of roughly 16,000 images had expert‑drawn boxes around specific findings. First, a “downscaler” network learns how best to shrink the large medical images to a resolution that matches a standard vision‑language model, while preserving important details. Then, during a fine‑tuning phase on the smaller, expertly annotated set, the new patch‑based losses teach the model to connect particular parts of the image grid with particular phrases from the reports. This setup lets the system learn both global decisions (“is pneumothorax present?”) and coarse localization (“where is it likely located?”) at the same time.
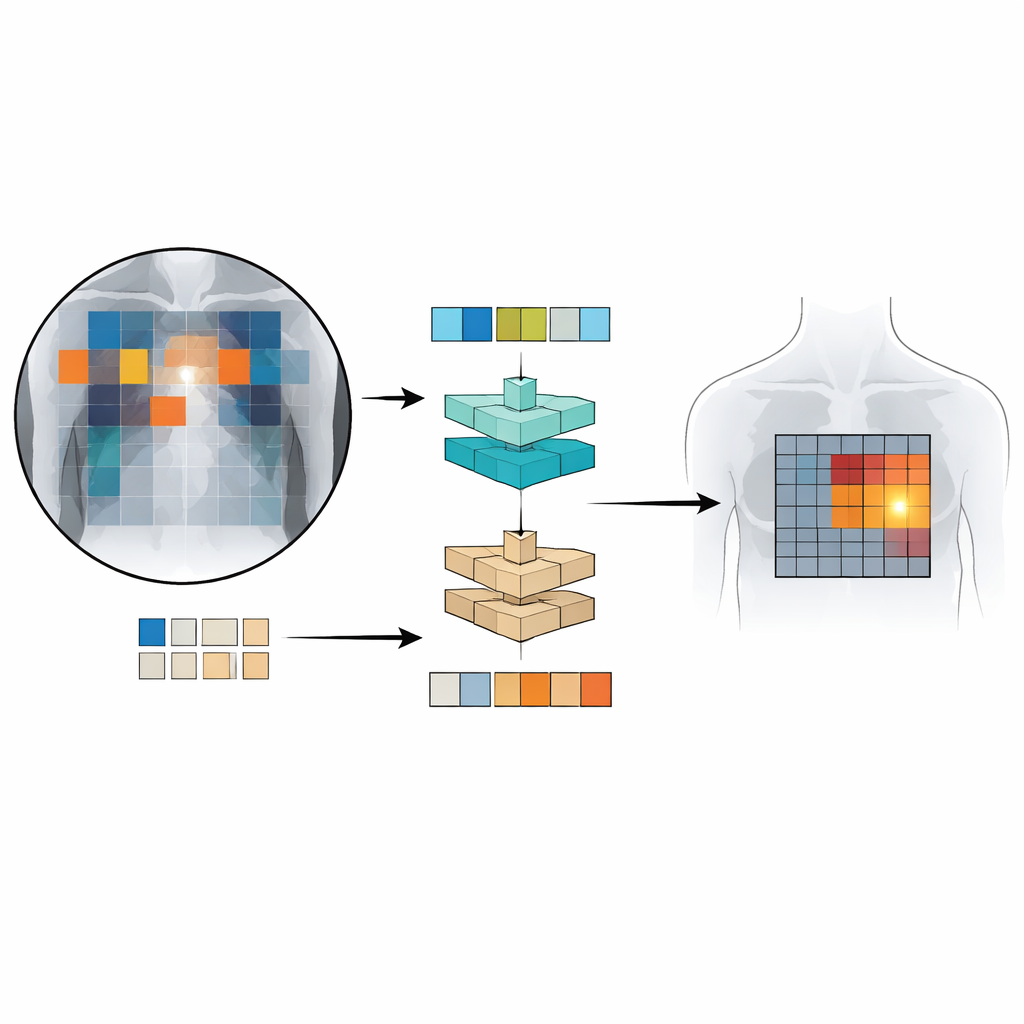
How Well Does Patch‑CLIP Perform?
The team compared Patch‑CLIP to strong commercial chest X‑ray detectors and to an advanced vision‑language detection system originally developed for everyday photographs. Using a clinical evaluation measure that balances sensitivity against the number of false alarms per image, Patch‑CLIP achieved state‑of‑the‑art or near‑state‑of‑the‑art performance on multiple lung and heart findings. Importantly, the patch‑based maps produced by Patch‑CLIP generated fewer spurious highlighted regions than standard attention, which often lights up large, irrelevant areas. For conditions that tend to occupy larger regions of the chest, like fluid buildup or enlarged heart size, the method localized abnormalities particularly well. It was less effective for extremely small findings, which can fall within a single patch, hinting that even finer image grids or improved architectures may further boost performance.
What This Means for Future Care
For non‑specialists, the key message is that Patch‑CLIP makes better use of the written reports already created in everyday clinical practice to teach AI systems where to look on an X‑ray. By aligning text descriptions with small image regions, it helps computers both recognize and roughly localize important findings with fewer detailed labels from experts. While it will not replace radiologists, this approach could act as a more reliable “second pair of eyes,” pointing to suspicious areas while keeping the number of false alarms low. As the method is extended to more diseases, higher‑resolution images, and even other imaging types, it may become an important building block for scalable, explainable medical AI.
Citation: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Keywords: chest x-ray AI, medical image localization, vision-language models, weakly supervised learning, radiology computer assistance