Clear Sky Science · ru
PatchCLIP позволяет обучать совместную контрастивную модель для записей о здоровье и изображений с локализацией по патчам с помощью потерь эмбеддинга патча
Более умная помощь от рентгена грудной клетки
Рентгенологи ежедневно читают снимки грудной клетки, чтобы обнаружить такие состояния, как пневмония, скопление жидкости вокруг лёгких или коллабированный лёгкое. Искусственный интеллект уже умеет сигнализировать, что «что‑то не так» на изображении, но часто затрудняется точно указать, где именно проблема. В этом исследовании представлена Patch‑CLIP — новый метод ИИ, который не только определяет наличие аномалии, но и выделяет её вероятное местоположение на рентгене, требуя значительно меньше экспертных аннотаций, чем традиционные системы.
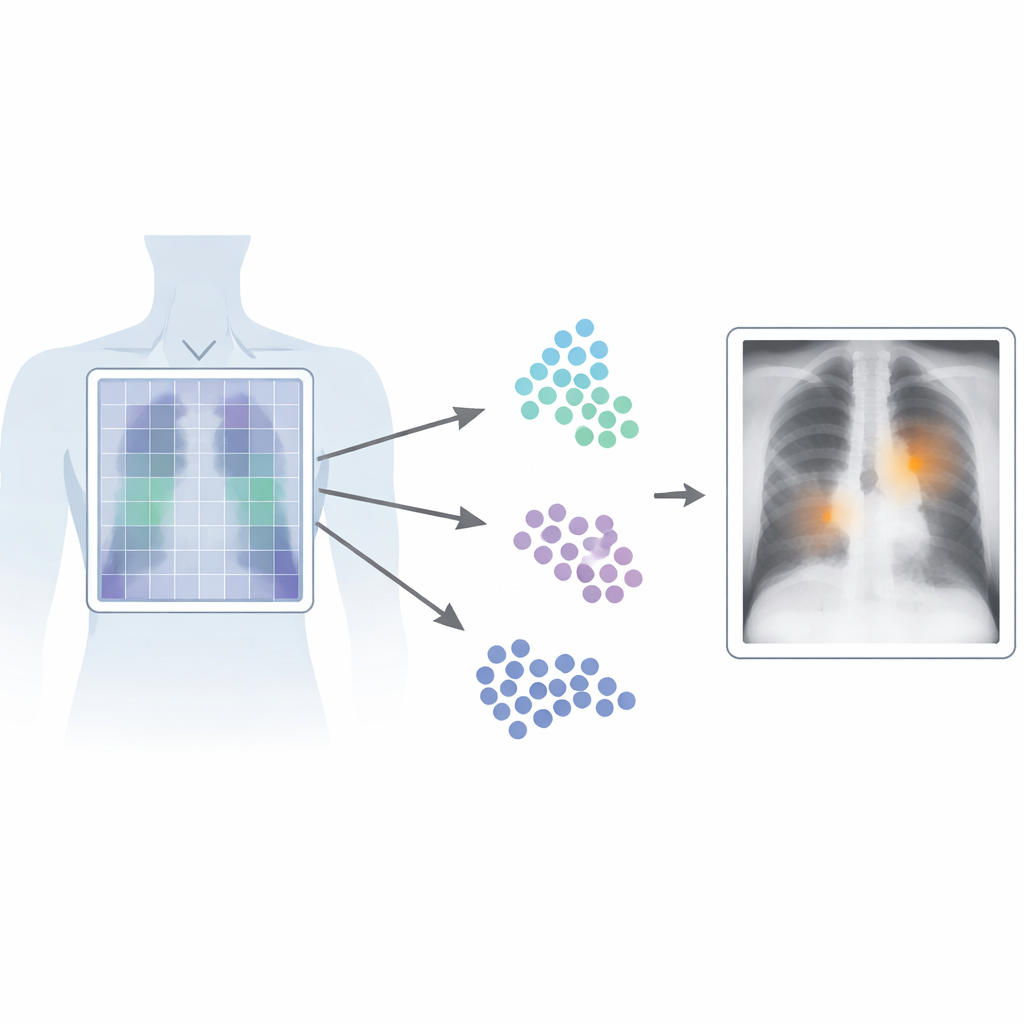
Почему важно найти точное место
В медицинской визуализации критичны время и точность. Современные системы «видение‑язык» обучаются на парах изображений и сопровождающих отчётов, что позволяет им распознавать паттерны без трудоёмкой пометки на уровне пикселей экспертами. Однако большинство таких систем рассматривают изображение целиком, улавливая «общую идею», но пропускают тонкие детали. Для рентгенов грудной клетки это проблема: едва заметная линия или маленькая тень могут сигнализировать о серьёзном состоянии. Традиционные высокопроизводительные детекторы решают это, обучаясь на множестве аккуратно нарисованных рамок вокруг аномалий, но такого рода разметка дорогая, медленная и трудно стандартизируемая между радиологами и больницами.
Просмотр рентгена по патчам
Patch‑CLIP опирается на популярную архитектуру CLIP, которая совместно обучает изображения и текст, и расширяет её для задач медицины. Вместо того чтобы выдавать единое сводное представление всего рентгена, новый метод также представляет изображение в виде сетки небольших патчей. Каждый патч отображается в то же абстрактное пространство, что и текст, описывающий медицинское наблюдение, например «жидкость в лёгком» или «без признаков». Авторы вводят дополнительные целевые функции обучения, которые поощряют группы релевантных патчей вести себя как локальные детекторы: патчи, перекрывающие аномальную область, сдвигаются ближе в этом абстрактном пространстве к тексту, описывающему аномалию, тогда как патчи из здоровых областей притягиваются к «нет находки».
Обучение системы с меньшим количеством меток
Для обучения и тестирования Patch‑CLIP исследователи использовали несколько крупных коллекций рентгенов грудной клетки в связке с радиологическими отчётами, включая более полумиллиона изображений. Большая часть использовалась без детальной ручной разметки; только подмножество около 16 000 изображений имело экспертно нарисованные боксы вокруг конкретных находок. Сначала «даунскейлер» (сеть с уменьшением разрешения) учится, как лучше сжимать крупные медицинские изображения до разрешения, соответствующего стандартной модели «видение‑язык», при сохранении важных деталей. Затем во время дообучения на меньшем, экспертно размеченном наборе новые потери на основе патчей учат модель связывать конкретные части сетки изображения с определёнными фразами из отчётов. Такая схема позволяет системе одновременно усваивать глобальные решения («есть ли пневмоторакс?») и грубую локализацию («где он, вероятно, расположен?»).
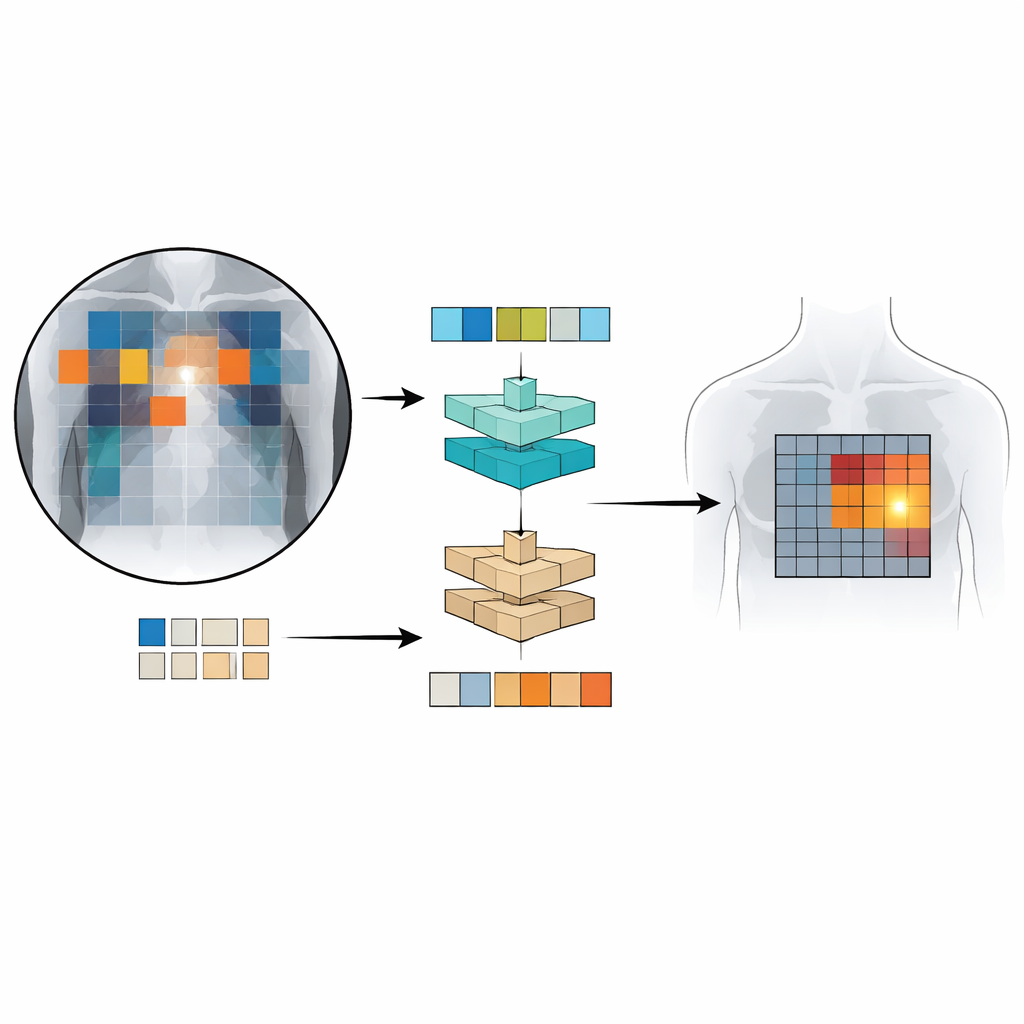
Насколько хорош Patch‑CLIP?
Команда сравнила Patch‑CLIP с сильными коммерческими детекторами для рентгена грудной клетки и с продвинутой системой «видение‑язык» для бытовых фотографий. Используя клиническую метрику, которая балансирует чувствительность и число ложных срабатываний на изображение, Patch‑CLIP показал уровень производительности на уровне лучших методов или близкий к нему по нескольким находкам лёгких и сердца. Важно, что картограммы на основе патчей, которые генерирует Patch‑CLIP, давали меньше ложных выделений, чем стандартные механизмы внимания, которые часто подсвечивают большие нерелевантные области. Для состояний, занимающих более крупные области грудной клетки, таких как скопление жидкости или увеличение размера сердца, метод особенно хорошо локализовал аномалии. Он был менее эффективен для крайне мелких находок, которые могут попадать внутрь одного патча, что указывает на то, что ещё более тонкая сетка или улучшенные архитектуры могут дополнительно повысить качество.
Что это значит для будущей помощи
Для неспециалистов ключевая мысль в том, что Patch‑CLIP лучше использует текстовые отчёты, которые уже создаются в повседневной клинической практике, чтобы научить ИИ, куда смотреть на рентгене. Совмещая текстовые описания с малыми областями изображения, он помогает компьютерам как распознавать, так и приблизительно локализовать важные находки с меньшим количеством детальных меток от экспертов. Хотя это не заменит радиологов, подход может стать более надёжной «второй парой глаз», указывая на подозрительные зоны при низком количестве ложных тревог. По мере расширения метода на большее число заболеваний, изображения более высокого разрешения и другие типы визуализации, он может стать важным строительным блоком масштабируемого и объяснимого медицинского ИИ.
Цитирование: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Ключевые слова: ИИ для рентгена грудной клетки, локализация на медицинских изображениях, модели «видение‑язык», слабонаблюдаемое обучение, компьютерная поддержка в радиологии