Clear Sky Science · ar
PatchCLIP يمكّن التدريب المشترك التبايني للسجلات الصحية والصور مع خسارة تضمين القطع في مناطق محددة
مساعدة أذكى من صور أشعة الصدر
يقوم أطباء الأشعة بقراءة صور أشعة الصدر يومياً لاكتشاف حالات مثل الالتهاب الرئوي، أو تجمع السوائل حول الرئتين، أو انخماص الرئة. يمكن للذكاء الاصطناعي بالفعل الإشارة إلى وجود «خطأ ما» في الصورة، لكنه غالباً ما يواجه صعوبة في الإشارة بدقة إلى مكان المشكلة. تقدم هذه الدراسة Patch‑CLIP، طريقة ذكاء اصطناعي جديدة مصمَّمة ليس فقط للإجابة عما إذا كانت هناك شذوذات، بل أيضاً لتسليط الضوء على الموقع المحتمل لها في الأشعة باستخدام عدد أقل بكثير من تعليمات الخبراء مقارنة بالأنظمة التقليدية.
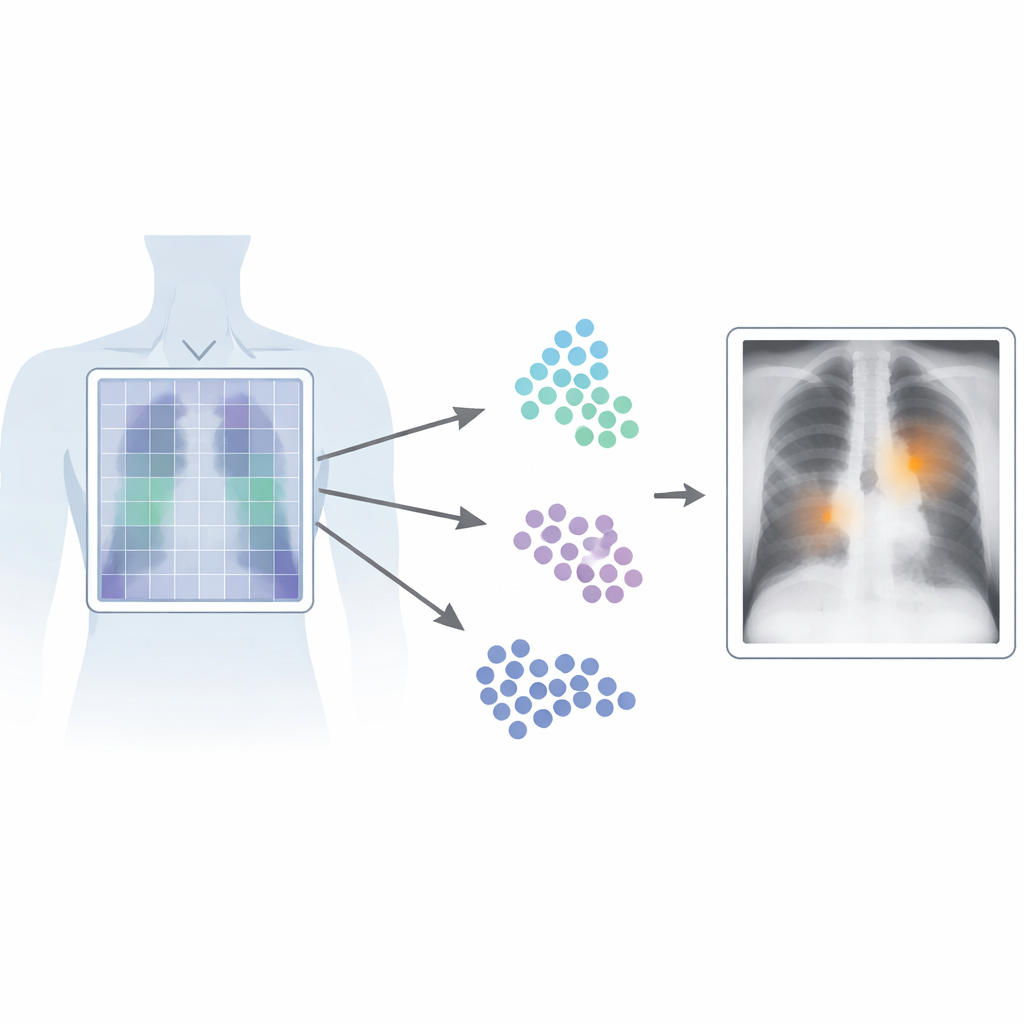
لماذا يهم إيجاد البقعة الدقيقة
في التصوير الطبي، الزمن والدقة حاسمان. تتعلم أنظمة الرؤية واللغة الحالية من أزواج الصور والتقارير المصاحبة لها، مما يسمح لها بالتعرّف على الأنماط دون الحاجة إلى تسميات بكسل‑ببكسل من الخبراء. ومع ذلك، فإن معظم هذه الأنظمة تعامل الصورة كوحدة واحدة، فتلتقط «الملخص» لكنها تفوّت التفاصيل الدقيقة. وهذا يمثل مشكلة في صور أشعة الصدر، حيث قد تكون خط رفيع أو ظل صغير مؤشراً لحالة خطيرة. تتغلب أجهزة الكشف عالية الأداء التقليدية على ذلك بالتدريب على العديد من المربعات المرسومة بعناية حول الشذوذات، لكن هذا النوع من الوسم مكلف وبطيء وصعب التوحيد بين أطباء ومرافق مختلفة.
النظر إلى الأشعة قطعة قطعة
يبني Patch‑CLIP على إطار CLIP الشائع الذي يتعلم من الصور والنصوص معاً، ويطوِّره بطريقة تلائم الاحتياجات الطبية. بدلاً من إنتاج مُلخّص واحد لكامل الصورة، تمثّل الطريقة الجديدة الصورة أيضاً كشبكة من القطع الصغيرة. يُحْدَث لكل قطعة إسناد في نفس الفضاء التجريدي الذي تُمثَّل به النصوص التي تُوصَف بها النتائج الطبية، مثل «سائل في الرئة» أو «لا سائل». يقدّم الباحثون أهداف تدريب إضافية تشجّع مجموعات من القطع ذات الصلة لتعمل ككواشف محلية: تُقَرَّب القطع المتداخلة مع منطقة شاذة في ذلك الفضاء التجريدي إلى النص الذي يصف الشذوذ، بينما تُجذب قطع المناطق السليمة نحو نص «لا توجد نتيجة».
تدريب النظام بعدد أقل من الوسوم
لتدريب واختبار Patch‑CLIP، استخدم الباحثون عدة مجموعات كبيرة من أشعة الصدر المزودة بتقارير أشعة، بما في ذلك أكثر من نصف مليون صورة. استُخدمت معظم هذه الصور دون وسم يدوي مفصّل؛ فقط مجموعة فرعية تقارب 16,000 صورة كان لها مربعات مرسومة بواسطة خبراء حول النتائج المحددة. أولاً، يتعلّم شبكة «مخفضة الدقة» كيف تقلص الصور الطبية الكبيرة إلى دقة تتوافق مع نموذج رؤية‑لغة قياسي مع الحفاظ على التفاصيل المهمة. ثم، خلال مرحلة الضبط الدقيق على المجموعة الصغيرة المعلّمة بخبرة، تُعلِّم خسائر القطع الجديدة النموذج ربط أجزاء معينة من شبكة الصورة بعبارات محددة من التقارير. هذا الإعداد يتيح للنظام تعلم القرارات الكلية («هل هنالك نفاخ رئوي؟») والتحديد التقريبي للموقع («أين يحتمل وجوده؟») في آن واحد.
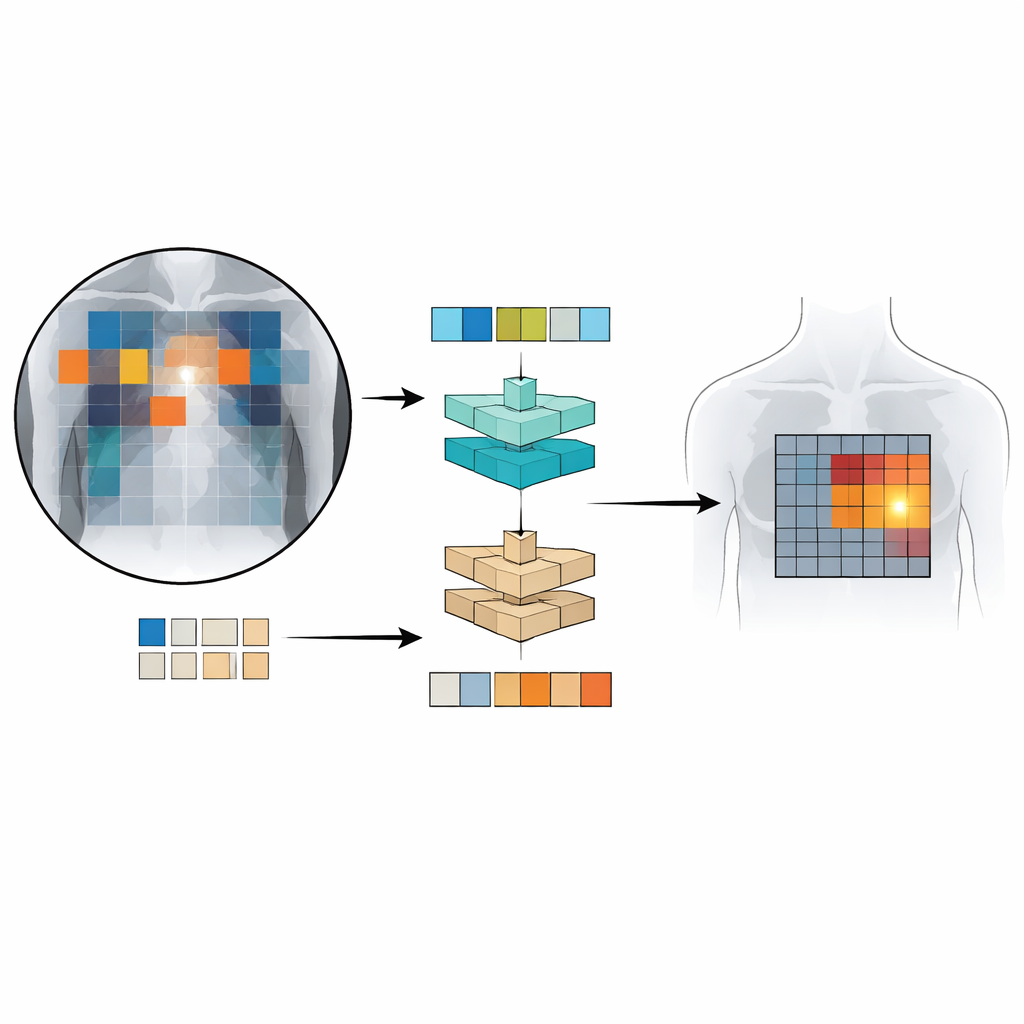
ما مدى فعالية Patch‑CLIP؟
قارن الفريق Patch‑CLIP مع كواشف تجارية قوية لأشعة الصدر ومع نظام كشف متقدم رؤية‑لغة طوّر أصلاً للصور الفوتوغرافية العامة. باستخدام مقياس تقييم سريري يوازن الحساسية مع عدد الإنذارات الكاذبة لكل صورة، حقق Patch‑CLIP أداءً في مستوى متقدِّم أو قريب من المتقدم عبر عدة نتائج متعلقة بالرئة والقلب. ومن المهم أن خرائط القطع التي يولدها Patch‑CLIP أظهرت مناطق مُحدَّدة أقل عشوائية مقارنةً بانتباه النموذج القياسي، الذي كثيراً ما يضيء مساحات كبيرة وغير ذات صلة. بالنسبة للحالات التي تشغل مناطق أكبر من الصدر، مثل تجمع السوائل أو تضخّم حجم القلب، نجح الأسلوب في تحديد مواقع الشذوذ بشكل جيد بشكل خاص. كان أقل فعالية للحالات الصغيرة للغاية التي قد تقع داخل قطعة واحدة، مما يشير إلى أن شبكات قطع أدق أو معماريات محسنة قد تعزز الأداء أكثر.
ماذا يعني هذا لرعاية المستقبل
بالنسبة لغير المتخصّصين، الرسالة الأساسية هي أن Patch‑CLIP يستفيد بشكل أفضل من التقارير المكتوبة التي تُنتَج في الممارسة السريرية اليومية لتعليم أنظمة الذكاء الاصطناعي أين تنظر في صورة الأشعة. من خلال محاذاة أوصاف النص مع مناطق صورة صغيرة، يساعد الحواسيب على التعرف وتحديد الموقع تقريباً للنتائج المهمة مع عدد أقل من الوسوم التفصيلية من الخبراء. وعلى الرغم من أنه لن يحل محل أطباء الأشعة، فقد يعمل هذا النهج كـ«زوج عيون ثانٍ» أكثر موثوقية، مشيراً إلى المناطق المشتبه بها مع إبقاء عدد الإنذارات الكاذبة منخفضاً. ومع توسيع الطريقة لتشمل أمراضاً أكثر وصوراً ذات دقة أعلى وأنواع تصوير أخرى، قد تصبح لبنة مهمة في بناء ذكاء طبي قابل للتوسع وسهل التفسير.
الاستشهاد: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
الكلمات المفتاحية: ذكاء اصطناعي لأشعة الصدر, تحديد مواضع الصور الطبية, نماذج الرؤية واللغة, التعلّم الموجَّه جزئياً, مساعدة حاسوبية في الإشعاعيات