Clear Sky Science · pt
PatchCLIP permite treinamento conjunto contrastivo específico de região entre prontuários e imagens com perda de incorporação por patch
Ajuda mais inteligente a partir de radiografias de tórax
Radiologistas interpretam radiografias de tórax diariamente para detectar condições como pneumonia, líquido ao redor dos pulmões ou pneumotórax. A inteligência artificial já consegue sinalizar que “algo está errado” numa imagem, mas frequentemente tem dificuldade em indicar com precisão onde está o problema. Este estudo apresenta o Patch‑CLIP, um novo método de IA projetado não apenas para dizer se existe uma anormalidade, mas também para destacar sua localização provável na radiografia, usando muito menos anotações de especialistas do que os sistemas tradicionais.
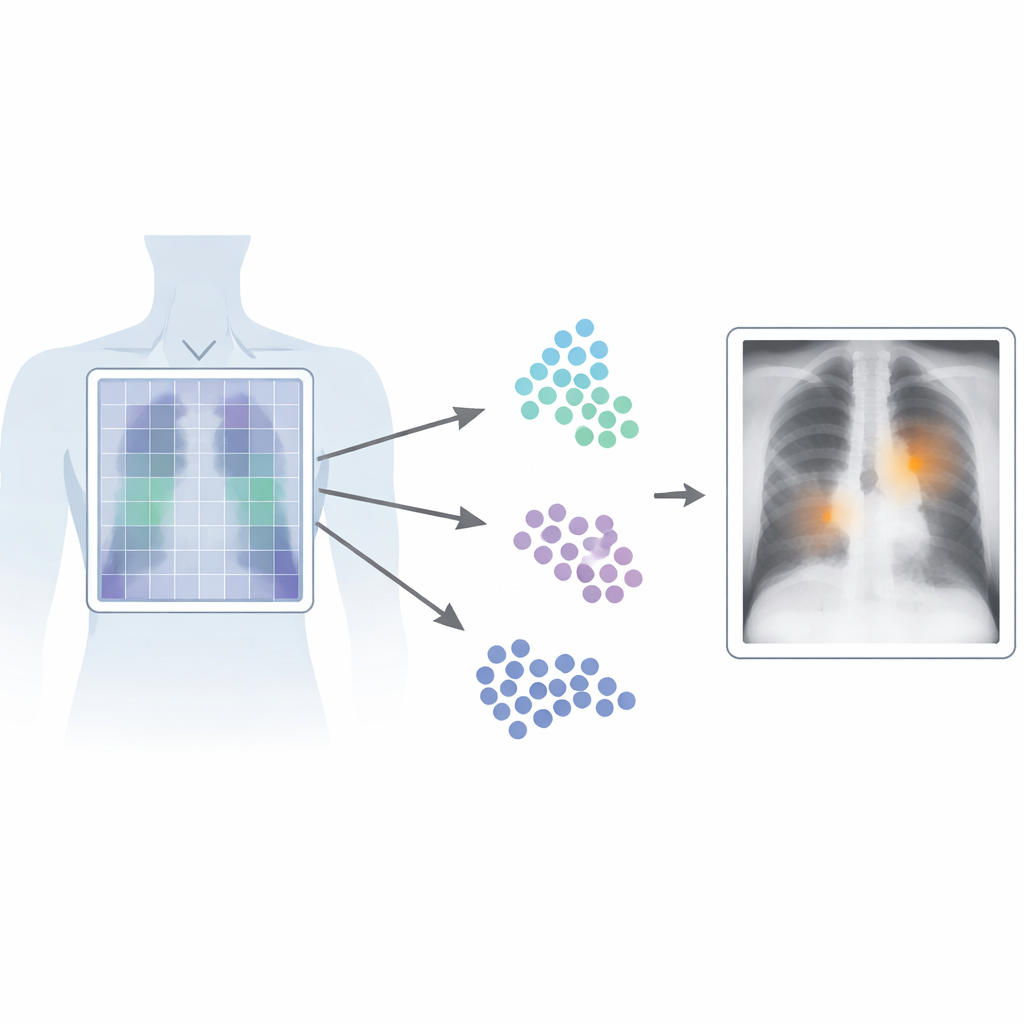
Por que encontrar o ponto exato importa
Em imagens médicas, tempo e precisão são críticos. Sistemas atuais visão‑linguagem aprendem a partir de pares de imagens e relatórios associados, permitindo reconhecer padrões sem rótulos pixel a pixel feitos manualmente. No entanto, a maioria desses sistemas trata a imagem como um todo, capturando o “essencial” mas perdendo detalhes finos. Isso é um problema para radiografias de tórax, onde uma linha sutil ou uma pequena sombra pode indicar uma condição grave. Detectores convencionais de alto desempenho contornam isso treinando com muitas caixas cuidadosamente desenhadas ao redor das anormalidades, mas esse tipo de rotulagem é caro, lento e difícil de padronizar entre radiologistas e hospitais.
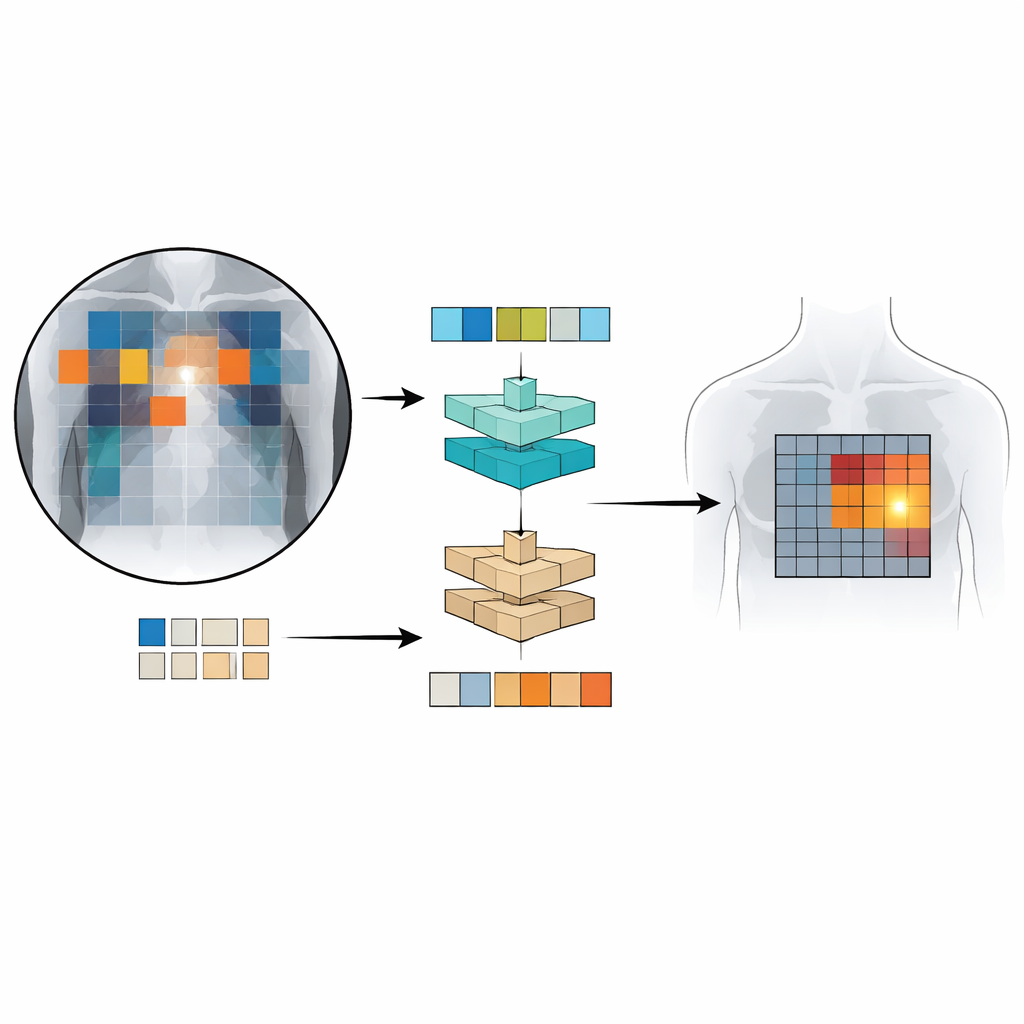
Olhando as radiografias patch por patch
Patch‑CLIP se baseia na popular arquitetura CLIP, que aprende conjuntamente a partir de imagens e texto, e a estende de forma mais adequada às necessidades médicas. Em vez de produzir apenas um resumo único de toda a radiografia, o novo método também representa a imagem como uma grade de pequenos patches. Cada patch é mapeado para o mesmo espaço abstrato do texto que descreve um achado médico, como “líquido no pulmão” ou “sem líquido”. Os autores introduzem objetivos de treinamento extras que incentivam grupos de patches relevantes a se comportarem como detectores locais: patches que se sobrepõem a uma região anormal são aproximados, nesse espaço abstrato, ao texto que descreve essa anormalidade, enquanto patches de regiões saudáveis são puxados para “sem achado”.
Ensinando o sistema com menos rótulos
Para treinar e testar o Patch‑CLIP, os pesquisadores usaram várias coleções grandes de radiografias de tórax pareadas com relatórios de radiologia, incluindo mais de meio milhão de imagens. A maior parte foi usada sem marcações manuais detalhadas; apenas um subconjunto de cerca de 16.000 imagens tinha caixas desenhadas por especialistas ao redor de achados específicos. Primeiro, uma rede “reduzidora” aprende a melhor forma de diminuir grandes imagens médicas para uma resolução compatível com um modelo visão‑linguagem padrão, preservando detalhes importantes. Em seguida, durante uma fase de ajuste fino no conjunto menor e anotado por especialistas, as novas perdas baseadas em patches ensinam o modelo a conectar partes particulares da grade de imagem com frases específicas dos relatórios. Essa configuração permite ao sistema aprender decisões globais (“há pneumotórax?”) e localização aproximada (“onde provavelmente está?”) ao mesmo tempo.
Quão bem o Patch‑CLIP se sai?
A equipe comparou o Patch‑CLIP com detectores comerciais fortes para radiografia de tórax e com um sistema avançado visão‑linguagem originalmente desenvolvido para fotografias do cotidiano. Usando uma medida de avaliação clínica que equilibra sensibilidade com o número de alarmes falsos por imagem, o Patch‑CLIP alcançou desempenho de ponta ou próximo ao de ponta em vários achados pulmonares e cardíacos. Importante, os mapas baseados em patches produzidos pelo Patch‑CLIP geraram menos regiões destacadas espúrias do que a atenção padrão, que frequentemente acende grandes áreas irrelevantes. Para condições que tendem a ocupar regiões maiores do tórax, como acúmulo de líquido ou aumento do tamanho cardíaco, o método localizou anormalidades particularmente bem. Foi menos eficaz para achados extremamente pequenos, que podem caber dentro de um único patch, indicando que grades de imagem ainda mais finas ou arquiteturas melhoradas podem aumentar ainda mais o desempenho.
O que isso significa para cuidados futuros
Para não especialistas, a mensagem principal é que o Patch‑CLIP aproveita melhor os relatórios escritos já gerados na prática clínica cotidiana para ensinar sistemas de IA onde olhar numa radiografia. Ao alinhar descrições textuais com pequenas regiões da imagem, ele ajuda os computadores tanto a reconhecer quanto a localizar aproximadamente achados importantes com menos rótulos detalhados de especialistas. Embora não substitua radiologistas, essa abordagem pode atuar como um “segundo par de olhos” mais confiável, apontando áreas suspeitas enquanto mantém baixo o número de alarmes falsos. À medida que o método for estendido para mais doenças, imagens de maior resolução e até outros tipos de imagem, poderá tornar‑se um bloco de construção importante para IA médica escalável e explicável.
Citação: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Palavras-chave: IA para radiografia de tórax, localização em imagem médica, modelos visão-linguagem, aprendizado fracamente supervisionado, assistência computacional em radiologia