Clear Sky Science · it
PatchCLIP consente l’addestramento congiunto contrastivo regione-specifico di referti clinici e immagini tramite perdita su embedding di patch
Un aiuto più intelligente dalle radiografie del torace
I radiologi leggono radiografie del torace ogni giorno per individuare condizioni come polmonite, liquido intorno ai polmoni o pneumotorace. L’intelligenza artificiale può già segnalare che “c’è qualcosa che non va” in un’immagine, ma spesso fatica a indicare con precisione dove si trova il problema. Questo studio presenta Patch‑CLIP, un nuovo metodo di IA pensato non solo per dire se è presente un’anomalia, ma anche per evidenziarne la probabile posizione sulla radiografia, usando molte meno annotazioni di esperti rispetto ai sistemi tradizionali.
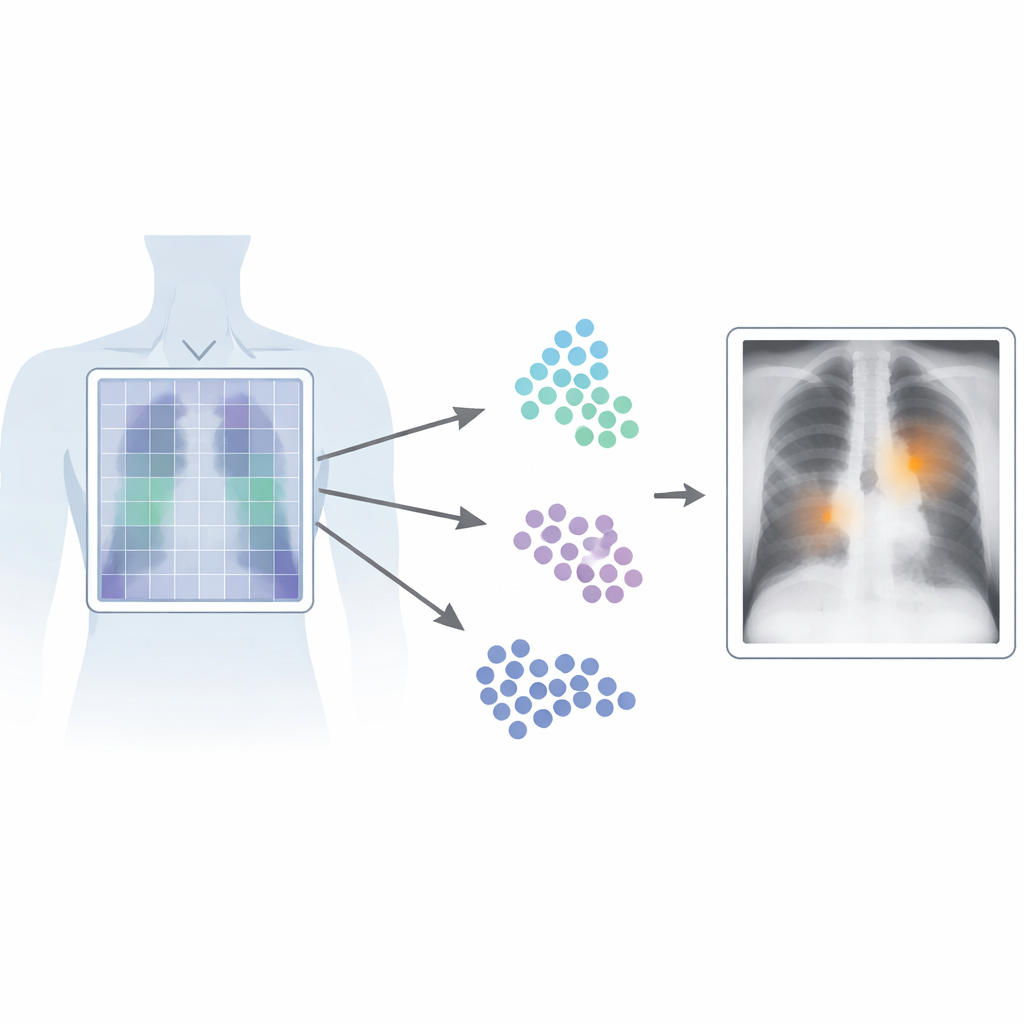
Perché è importante trovare il punto esatto
Nelle immagini mediche, tempo e precisione sono fondamentali. Gli attuali sistemi visione‑linguaggio apprendono da coppie di immagini e referti associati, permettendo loro di riconoscere schemi senza etichette pixel‑per‑pixel fornite dagli esperti. Tuttavia, la maggior parte di questi sistemi tratta l’immagine come un tutto, cogliendo il “senso generale” ma perdendo dettagli fini. Questo è un problema per le radiografie del torace, dove una linea sottile o una piccola ombra può segnalare una condizione seria. I rilevatori tradizionali ad alte prestazioni superano questo limite addestrando su molte bounding box disegnate accuratamente attorno alle anomalie, ma questo tipo di annotazione è costoso, lento e difficile da standardizzare tra radiologi e ospedali.
Esaminare le radiografie patch dopo patch
Patch‑CLIP si basa sul popolare framework CLIP, che apprende congiuntamente da immagini e testo, e lo estende in modo più adatto alle esigenze mediche. Invece di produrre soltanto un riassunto unico dell’intera radiografia, il nuovo metodo rappresenta anche l’immagine come una griglia di piccole patch. Ogni patch viene mappata nello stesso spazio astratto del testo che descrive un reperto medico, come “liquido nel polmone” o “assenza di liquido”. Gli autori introducono obiettivi di addestramento aggiuntivi che incoraggiano gruppi di patch rilevanti a comportarsi come rilevatori locali: le patch che sovrappongono una regione anomala vengono avvicinate, in questo spazio astratto, al testo che descrive quell’anomalia, mentre le patch di regioni sane vengono spinte verso la descrizione “nessun reperto”.
Addestrare il sistema con meno etichette
Per addestrare e testare Patch‑CLIP, i ricercatori hanno utilizzato diverse grandi raccolte di radiografie del torace abbinate ai referti radiologici, comprendendo oltre mezzo milione di immagini. La maggior parte di queste è stata usata senza marcature manuali dettagliate; solo un sottoinsieme di circa 16.000 immagini aveva box disegnati da esperti intorno a reperti specifici. Innanzitutto, una rete “downscaler” impara come ridurre al meglio le immagini mediche di grande dimensione a una risoluzione che corrisponda a un modello visione‑linguaggio standard, preservando i dettagli importanti. Poi, durante una fase di fine‑tuning sul sottoinsieme più piccolo e annotato da esperti, le nuove perdite basate su patch insegnano al modello a collegare parti specifiche della griglia di immagine a frasi particolari dei referti. Questa impostazione permette al sistema di apprendere contemporaneamente decisioni globali (“è presente pneumotorace?”) e una localizzazione approssimativa (“dove è probabilmente localizzato?”).
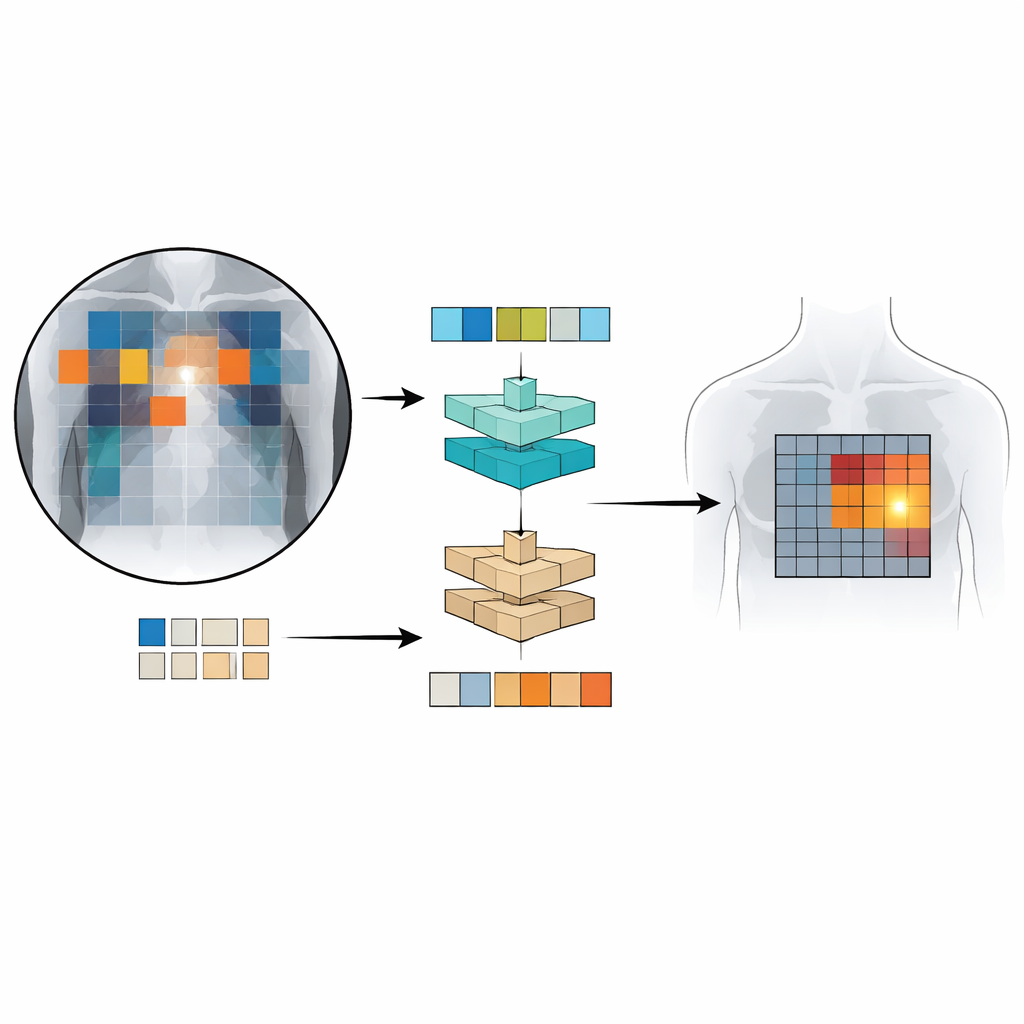
Quanto bene funziona Patch‑CLIP?
Il team ha confrontato Patch‑CLIP con robusti rilevatori commerciali per radiografie toraciche e con un avanzato sistema di rilevamento visione‑linguaggio originariamente sviluppato per fotografie quotidiane. Utilizzando una misura di valutazione clinica che bilancia la sensibilità con il numero di falsi allarmi per immagine, Patch‑CLIP ha raggiunto prestazioni allo stato dell’arte o vicine ad esse su molteplici reperti polmonari e cardiaci. È importante che le mappe basate su patch prodotte da Patch‑CLIP generassero meno aree evidenziate spurie rispetto all’attenzione standard, che spesso illumina vaste aree irrilevanti. Per condizioni che tendono a occupare regioni più ampie del torace, come accumulo di liquido o cardiomegalia, il metodo ha localizzato le anomalie in modo particolarmente efficace. È risultato meno efficace per reperti estremamente piccoli, che possono ricadere all’interno di una singola patch, suggerendo che griglie di immagine ancora più fini o architetture migliorate potrebbero aumentare ulteriormente le prestazioni.
Cosa significa questo per le cure future
Per i non specialisti, il messaggio chiave è che Patch‑CLIP sfrutta meglio i referti scritti già prodotti nella pratica clinica quotidiana per insegnare ai sistemi di IA dove guardare in una radiografia. Allineando le descrizioni testuali con piccole regioni d’immagine, aiuta i computer sia a riconoscere sia a localizzare approssimativamente reperti importanti con meno etichette dettagliate da parte degli esperti. Pur non sostituendo i radiologi, questo approccio potrebbe fungere da “secondo paio di occhi” più affidabile, indicando aree sospette mantenendo basso il numero di falsi allarmi. Man mano che il metodo viene esteso a più malattie, immagini a risoluzione più elevata e persino ad altri tipi di imaging, potrebbe diventare un mattoncino importante per un’IA medica scalabile e spiegabile.
Citazione: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Parole chiave: IA per radiografia toracica, localizzazione in immagini mediche, modelli visione-linguaggio, apprendimento debolmente supervisionato, assistenza computerizzata in radiologia