Clear Sky Science · fr
PatchCLIP permet un entraînement contrastif conjoint des dossiers médicaux et des images, spécifique aux régions, avec perte d'encodage par patch
Une aide plus intelligente pour les radiographies thoraciques
Les radiologues lisent des radiographies thoraciques quotidiennement pour repérer des affections telles que la pneumonie, un épanchement pleural ou un pneumothorax. L'intelligence artificielle sait déjà signaler qu'« il y a quelque chose » sur une image, mais peine souvent à indiquer précisément où se situe le problème. Cette étude présente Patch‑CLIP, une nouvelle méthode d'IA conçue non seulement pour dire si une anomalie est présente, mais aussi pour en souligner l'emplacement probable sur la radiographie, en utilisant beaucoup moins d'annotations expertes que les systèmes traditionnels.
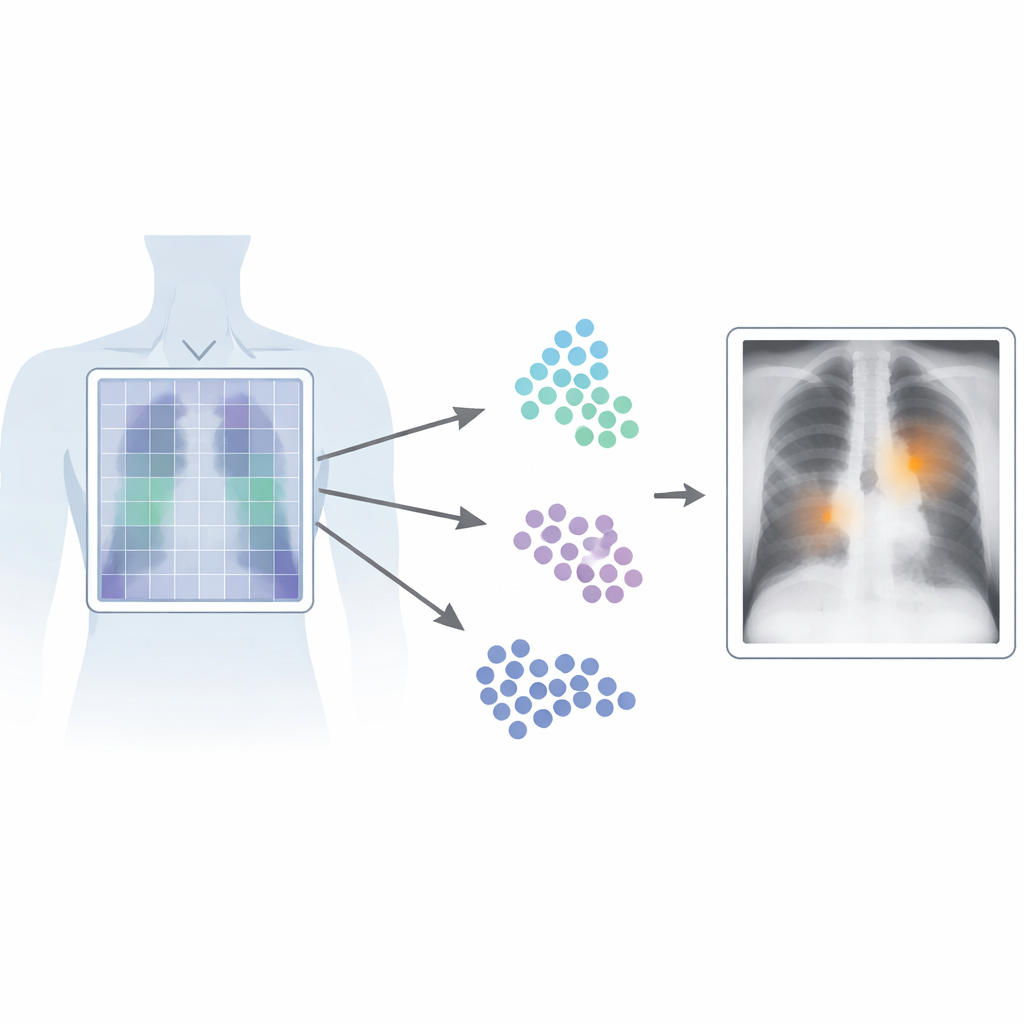
Pourquoi localiser précisément importe
En imagerie médicale, le temps et la précision sont essentiels. Les systèmes vision‑langage actuels apprennent à partir de paires image‑rapport, ce qui leur permet de reconnaître des motifs sans avoir besoin d'étiquettes pixel‑par‑pixel fastidieuses fournies par des experts. Cependant, la plupart de ces systèmes considèrent l'image dans son ensemble, captant le « sens général » mais manquant les détails fins. C'est problématique pour les radiographies thoraciques, où une ligne subtile ou une petite ombre peut signaler une atteinte grave. Les détecteurs conventionnels à haute performance contournent cela en s'entraînant sur de nombreux cadres dessinés minutieusement autour des anomalies, mais ce type d'annotation est coûteux, lent et difficile à standardiser entre radiologues et établissements.
Examiner les radiographies patch par patch
Patch‑CLIP s'appuie sur le cadre populaire CLIP, qui apprend conjointement à partir d'images et de texte, et l'étend d'une manière mieux adaptée aux besoins médicaux. Plutôt que de produire uniquement un résumé unique de toute la radiographie, la nouvelle méthode représente aussi l'image comme une grille de petits patches. Chaque patch est projeté dans le même espace abstrait que le texte décrivant une constatation médicale, comme « liquide dans le poumon » ou « pas de liquide ». Les auteurs introduisent des objectifs d'entraînement supplémentaires qui encouragent des groupes de patches pertinents à se comporter comme des détecteurs locaux : les patches qui chevauchent une région anormale sont rapprochés, dans cet espace abstrait, du texte décrivant cette anomalie, tandis que les patches issus de régions saines sont attirés vers « aucune anomalie ».
Enseigner au système avec moins d'étiquettes
Pour entraîner et tester Patch‑CLIP, les chercheurs ont utilisé plusieurs grandes collections de radiographies thoraciques associées à des comptes rendus de radiologie, totalisant plus d'un demi‑million d'images. La plupart ont été utilisées sans annotations manuelles détaillées ; seul un sous‑ensemble d'environ 16 000 images contenait des cadres tracés par des experts autour de constatations spécifiques. D'abord, un réseau « réducteur de résolution » apprend comment réduire au mieux les grandes images médicales à une résolution qui correspond à un modèle vision‑langage standard, tout en préservant les détails importants. Ensuite, lors d'une phase d'affinage sur l'ensemble plus petit et annoté par des experts, les nouvelles pertes basées sur les patches apprennent au modèle à relier des parties particulières de la grille d'images à des phrases spécifiques des comptes rendus. Cette configuration permet au système d'apprendre à la fois des décisions globales (« y a‑t‑il un pneumothorax ? ») et une localisation approximative (« où est‑il probablement situé ? ») simultanément.
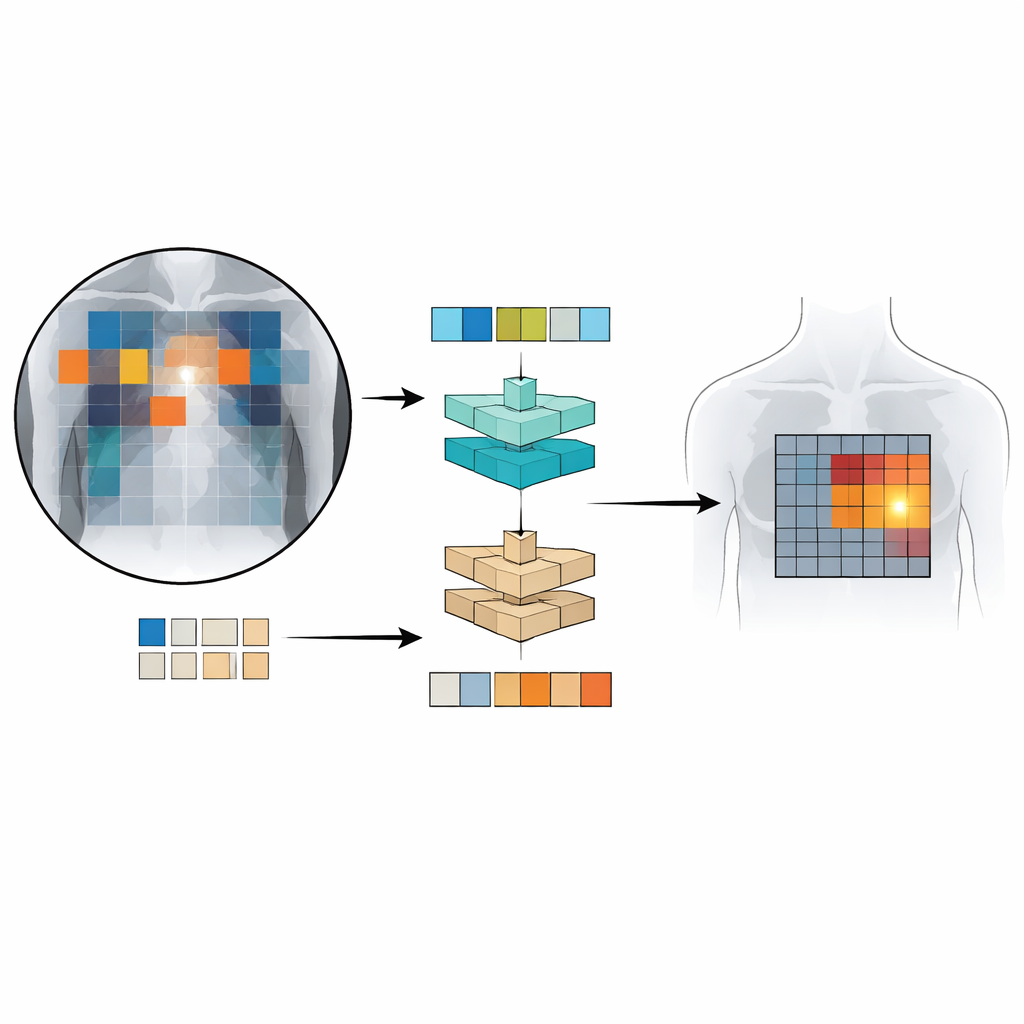
Quelle est la performance de Patch‑CLIP ?
L'équipe a comparé Patch‑CLIP à de robustes détecteurs commerciaux de radiographies thoraciques et à un système avancé de détection vision‑langage initialement développé pour des photographies ordinaires. En utilisant une mesure d'évaluation clinique qui équilibre la sensibilité et le nombre de fausses alertes par image, Patch‑CLIP a obtenu des performances à l'état de l'art ou proches de l'état de l'art sur plusieurs constatations pulmonaires et cardiaques. Fait important, les cartes basées sur les patches produites par Patch‑CLIP généraient moins de régions mises en évidence de manière erronée que l'attention standard, qui allume souvent de larges zones non pertinentes. Pour les affections occupant des régions thoraciques plutôt étendues, comme l'accumulation de liquide ou l'augmentation de taille cardiaque, la méthode a localisé les anomalies particulièrement bien. Elle était moins efficace pour des constats extrêmement petits, qui peuvent tenir dans un seul patch, ce qui suggère que des grilles d'image plus fines ou des architectures améliorées pourraient encore améliorer les performances.
Ce que cela signifie pour les soins futurs
Pour les non‑spécialistes, le message clé est que Patch‑CLIP utilise mieux les comptes rendus écrits déjà produits dans la pratique clinique quotidienne pour apprendre aux systèmes d'IA où regarder sur une radiographie. En alignant les descriptions textuelles avec de petites régions d'image, il aide les ordinateurs à la fois à reconnaître et à localiser approximativement des constatations importantes avec moins d'étiquettes détaillées d'experts. Bien qu'il ne remplace pas les radiologues, cette approche pourrait servir de « seconde paire d'yeux » plus fiable, indiquant les zones suspectes tout en maintenant un faible taux de fausses alertes. À mesure que la méthode sera étendue à davantage de maladies, à des images de plus haute résolution et même à d'autres types d'imagerie, elle pourrait devenir un composant important pour une IA médicale évolutive et explicable.
Citation: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Mots-clés: IA pour radiographies thoraciques, localisation d'images médicales, modèles vision‑langage, apprentissage faiblement supervisé, assistance informatique en radiologie