Clear Sky Science · sv
PatchCLIP möjliggör regionsspecifik kontrastiv samträning av journaltext och bild med patch‑embeddings‑förlust
Smartare stöd från bröstkorgsröntgen
Radiologer läser bröstkorgsröntgenbilder dagligen för att upptäcka tillstånd som pneumoni, vätska runt lungorna eller kollapsad lunga. Artificiell intelligens kan redan flagga att ”något är fel” på en bild, men har ofta svårt att exakt ange var problemet sitter. Denna studie introducerar Patch‑CLIP, en ny AI‑metod utformad för att inte bara säga om en avvikelse finns, utan också att markera dess troliga läge på röntgenbilden, med avsevärt färre expertannoteringar än traditionella system.
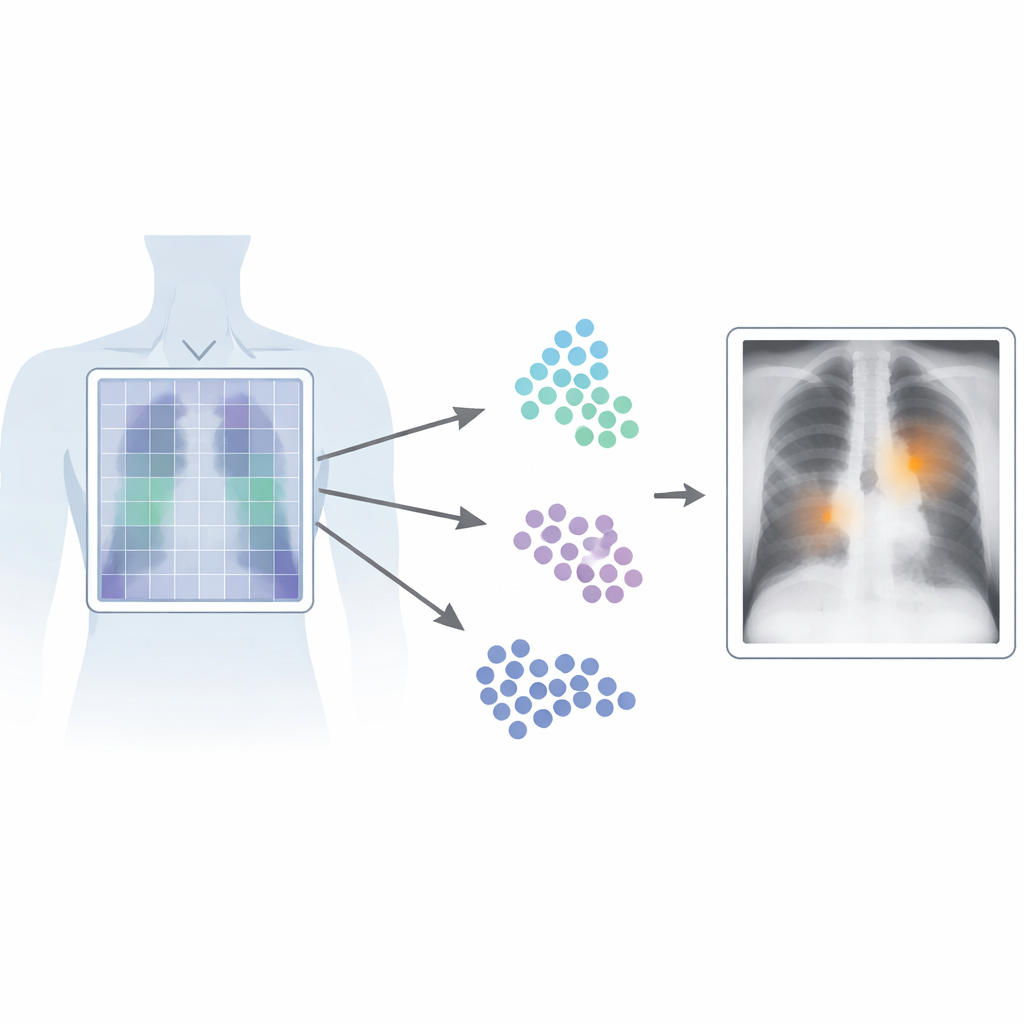
Varför det spelar roll att hitta exakt plats
I medicinsk bilddiagnostik är tid och precision avgörande. Nuvarande vision‑språkssystem lär sig från par av bilder och tillhörande rapporter, vilket gör att de kan känna igen mönster utan tidsödande pixel‑nivå‑etiketter från experter. Men de flesta av dessa system behandlar bilden som en helhet och fångar helhetsintrycket men missar finmaskiga detaljer. Det är ett problem för bröstkorgsröntgen, där en subtil linje eller liten skugga kan signalera ett allvarligt tillstånd. Konventionella högpresterande detektorer övervinner detta genom att träna på många noggrant ritade rutor runt avvikelser, men sådan märkning är kostsam, långsam och svår att standardisera mellan radiologer och sjukhus.
Tittar på röntgenruta för ruta
Patch‑CLIP bygger på den populära CLIP‑ramen, som gemensamt lär sig från bilder och text, och utvidgar den på ett sätt som bättre lämpar sig för medicinska behov. Istället för att bara producera en enda sammanfattning av hela röntgenbilden representerar den nya metoden även bilden som ett rutnät av små patchar. Varje patch mappas in i samma abstrakta rum som texten som beskriver ett medicinskt fynd, till exempel ”vätska i lungan” eller ”ingen vätska”. Författarna inför ytterligare träningsmål som uppmuntrar grupper av relevanta patchar att agera som lokala detektorer: patchar som överlappar en avvikande region dras närmare, i detta abstrakta rum, till texten som beskriver avvikelsen, medan patchar från friska regioner dras mot ”inget fynd”.
Lär systemet med färre etiketter
För att träna och testa Patch‑CLIP använde forskarna flera stora samlingar av bröstkorgsröntgenbilder i par med röntgenrapporter, inklusive mer än en halv miljon bilder. De flesta av dessa användes utan detaljerade manuella markeringar; endast en delmängd på ungefär 16 000 bilder hade expertritade rutor kring specifika fynd. Först lär sig ett ”downscaler”‑nätverk hur man bäst krymper de stora medicinska bilderna till en upplösning som matchar en standard vision‑språkmodell, samtidigt som viktiga detaljer bevaras. Sedan, under en finjusteringsfas på den mindre, expertannoterade uppsättningen, lär de nya patch‑baserade förlusterna modellen att koppla särskilda delar av bildrutnätet till specifika fraser i rapporterna. Denna uppställning låter systemet lära sig både globala beslut (”finns pneumothorax?”) och grov lokalisering (”var är det sannolikt beläget?”) samtidigt.
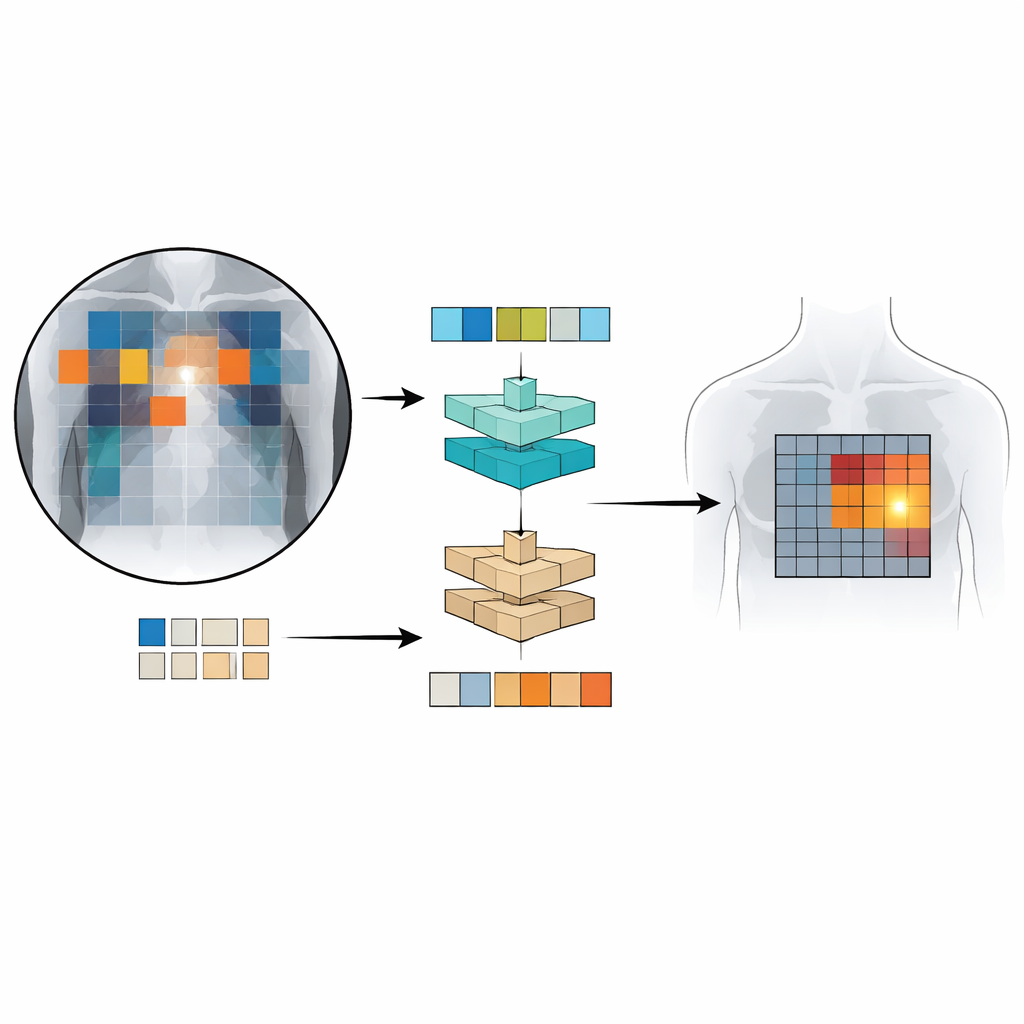
Hur bra presterar Patch‑CLIP?
Teamet jämförde Patch‑CLIP med starka kommersiella bröstkorgsdetektorer och med ett avancerat vision‑språk‑detekteringssystem ursprungligen utvecklat för vardagliga fotografier. Med en klinisk utvärderingsmetod som väger känslighet mot antalet falsklarm per bild uppnådde Patch‑CLIP topp‑ eller nära topprestanda för flera lung‑ och hjärt‑fynd. Viktigt är att de patch‑baserade kartorna som Patch‑CLIP producerade genererade färre spuriösa markerade områden än standardattention, som ofta lyser upp stora, irrelevanta områden. För tillstånd som tenderar att omfatta större regioner i bröstkorgen, som vätskeansamling eller förstorad hjärtstorlek, lokaliserade metoden avvikelser särskilt väl. Den var mindre effektiv för extremt små fynd, som kan hamna inom en enda patch, vilket antyder att ännu finare bildrutnät eller förbättrade arkitekturer kan ge ytterligare förbättringar.
Vad detta betyder för framtida vård
För icke‑specialister är huvudbudskapet att Patch‑CLIP utnyttjar de textbeskrivningar som redan skapas i daglig klinisk praxis bättre för att lära AI‑system var de ska titta på en röntgenbild. Genom att alignera textbeskrivningar med små bildregioner hjälper det datorer att både känna igen och grovt lokalisera viktiga fynd med färre detaljerade etiketter från experter. Det kommer inte att ersätta radiologer, men tillvägagångssättet kan fungera som ett mer pålitligt ”andra öga” som pekar ut misstänkta områden samtidigt som antalet falsklarm hålls lågt. När metoden utvidgas till fler sjukdomar, högre upplösning och även andra bildtyper kan den bli en viktig byggsten för skalbar, förklarbar medicinsk AI.
Citering: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Nyckelord: bröstkorgsröntgen AI, lokalisering i medicinska bilder, vision‑språk‑modeller, svagt övervakad inlärning, radiologiskt datorstöd