Clear Sky Science · es
PatchCLIP permite un entrenamiento conjunto contrastivo específico por región de historias clínicas e imágenes con pérdida de incrustación por parches
Ayuda más inteligente a partir de radiografías de tórax
Los radiólogos leen radiografías de tórax todos los días para detectar afecciones como neumonía, líquido alrededor de los pulmones o un pulmón colapsado. La inteligencia artificial ya puede señalar que “algo anda mal” en una imagen, pero a menudo le cuesta indicar con precisión dónde está el problema. Este estudio presenta Patch‑CLIP, un nuevo método de IA diseñado no solo para decir si existe una anomalía, sino también para resaltar su ubicación probable en la radiografía, usando muchas menos anotaciones de expertos que los sistemas tradicionales.
Por qué importa encontrar el punto exacto
En imagen médica, el tiempo y la precisión son críticos. Los sistemas visión‑lenguaje actuales aprenden a partir de pares de imágenes e informes asociados, lo que les permite reconocer patrones sin etiquetas laboriosas a nivel de píxel por parte de expertos. Sin embargo, la mayoría de estos sistemas tratan la imagen como un todo, captando la “idea general” pero perdiendo detalles finos. Eso es un problema en radiografías de tórax, donde una línea sutil o una pequeña sombra pueden señalar una condición grave. Los detectores convencionales de alto rendimiento superan esto entrenando con muchas cajas dibujadas cuidadosamente alrededor de las anomalías, pero ese tipo de etiquetado es costoso, lento y difícil de estandarizar entre radiólogos y hospitales.
Analizar radiografías parche a parche
Patch‑CLIP se basa en el popular marco CLIP, que aprende conjuntamente de imágenes y texto, y lo amplía de una manera mejor adaptada a las necesidades médicas. En lugar de producir solo un resumen único de toda la radiografía, el nuevo método también representa la imagen como una cuadrícula de pequeños parches. Cada parche se mapea al mismo espacio abstracto que el texto que describe un hallazgo médico, como “líquido en el pulmón” o “sin líquido”. Los autores introducen objetivos de entrenamiento adicionales que animan a grupos de parches relevantes a comportarse como detectores locales: los parches que se solapan con una región anómala se acercan, en ese espacio abstracto, al texto que describe esa anomalía, mientras que los parches de regiones sanas se atraen hacia “sin hallazgo”.
Enseñar al sistema con menos etiquetas
Para entrenar y probar Patch‑CLIP, los investigadores usaron varias colecciones grandes de radiografías de tórax emparejadas con informes de radiología, incluidos más de medio millón de imágenes. La mayoría se usó sin marcaciones manuales detalladas; solo un subconjunto de aproximadamente 16.000 imágenes tenía cajas dibujadas por expertos alrededor de hallazgos específicos. Primero, una red “reductora” aprende cómo reducir mejor las imágenes médicas grandes a una resolución que coincida con un modelo visión‑lenguaje estándar, preservando los detalles importantes. Luego, durante una fase de ajuste fino con el conjunto más pequeño y anotado por expertos, las nuevas pérdidas basadas en parches enseñan al modelo a conectar partes particulares de la cuadrícula de la imagen con frases concretas de los informes. Esta configuración permite que el sistema aprenda tanto decisiones globales (“¿está presente el neumotórax?”) como localización aproximada (“¿dónde se encuentra probablemente?”) al mismo tiempo.
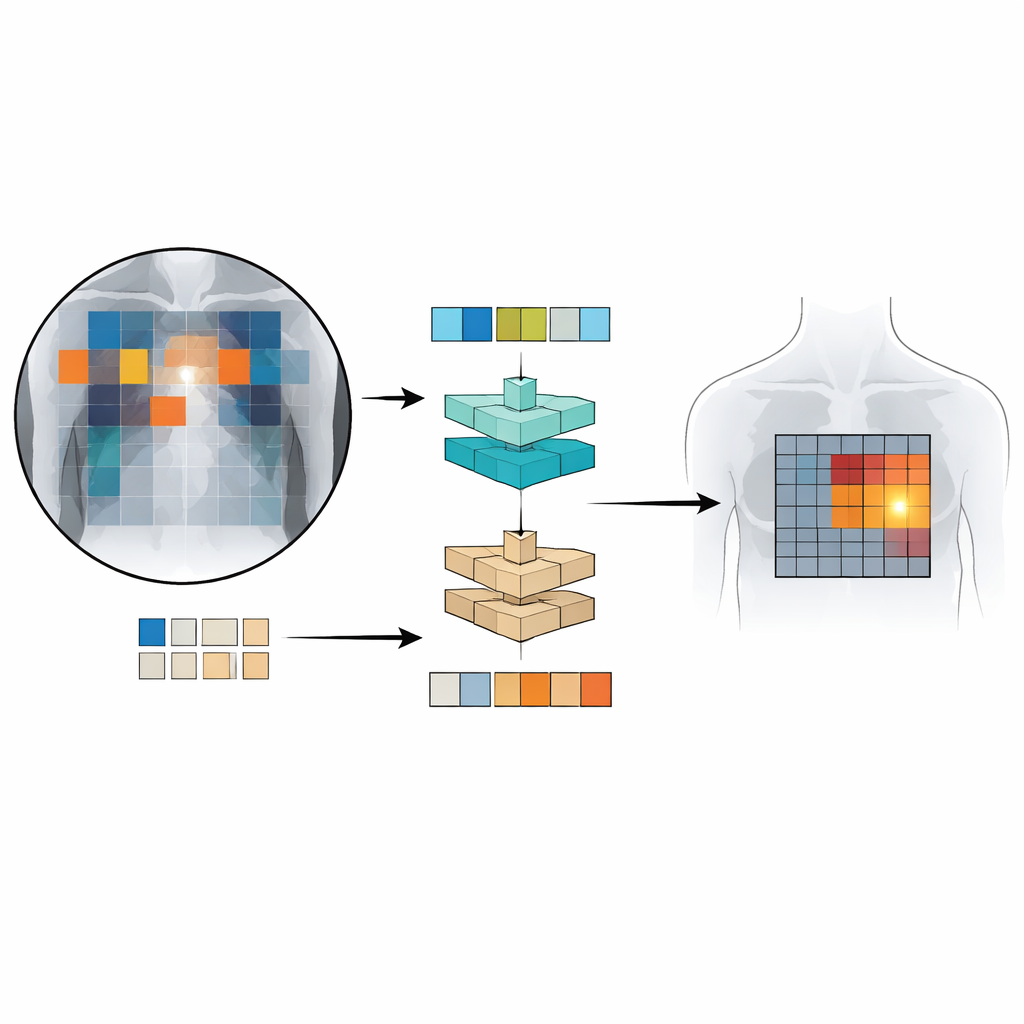
¿Qué tan bien funciona Patch‑CLIP?
El equipo comparó Patch‑CLIP con detectores comerciales fuertes para radiografías de tórax y con un avanzado sistema de detección visión‑lenguaje desarrollado originalmente para fotografías cotidianas. Usando una medida de evaluación clínica que equilibra la sensibilidad frente al número de falsas alarmas por imagen, Patch‑CLIP alcanzó un rendimiento de última generación o cercano a la última generación en múltiples hallazgos pulmonares y cardíacos. Es importante que los mapas basados en parches producidos por Patch‑CLIP generaran menos regiones resaltadas espurias que la atención estándar, que a menudo ilumina áreas grandes e irrelevantes. Para condiciones que tienden a ocupar regiones más amplias del tórax, como la acumulación de líquido o el agrandamiento del corazón, el método localizó las anomalías especialmente bien. Fue menos eficaz para hallazgos extremadamente pequeños, que pueden caer dentro de un solo parche, lo que sugiere que cuadriculas de imagen aún más finas o arquitecturas mejoradas podrían aumentar aún más el rendimiento.
Qué significa esto para la atención futura
Para no especialistas, el mensaje clave es que Patch‑CLIP aprovecha mejor los informes escritos que ya se crean en la práctica clínica diaria para enseñar a los sistemas de IA dónde mirar en una radiografía. Al alinear descripciones de texto con pequeñas regiones de la imagen, ayuda a las máquinas tanto a reconocer como a localizar de forma aproximada hallazgos importantes con menos etiquetas detalladas de los expertos. Aunque no reemplazará a los radiólogos, este enfoque podría actuar como un “segundo par de ojos” más fiable, señalando áreas sospechosas mientras mantiene bajo el número de falsas alarmas. A medida que el método se extienda a más enfermedades, imágenes de mayor resolución e incluso otros tipos de imagen, podría convertirse en un bloque de construcción importante para una IA médica escalable y explicable.
Cita: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Palabras clave: IA para radiografías de tórax, localización en imágenes médicas, modelos visión‑lenguaje, aprendizaje débilmente supervisado, asistencia informática en radiología