Clear Sky Science · de
PatchCLIP ermöglicht regionsspezifisches kontrastives gemeinsames Training von Gesundheitsberichten und Bildern mit Patch‑Einbettungsverlust
Intelligentere Hilfe bei Thorax‑Röntgenaufnahmen
Radiologinnen und Radiologen lesen täglich Thorax‑Röntgenaufnahmen, um Erkrankungen wie Pneumonie, Flüssigkeit um die Lunge oder einen Kollaps der Lunge zu erkennen. Künstliche Intelligenz kann bereits „irgendetwas stimmt nicht“ auf einem Bild markieren, hat aber oft Schwierigkeiten, genau auf den Ort des Problems hinzuweisen. Diese Studie stellt Patch‑CLIP vor, eine neue KI‑Methode, die nicht nur angibt, ob eine Auffälligkeit vorliegt, sondern auch die wahrscheinliche Lage auf dem Röntgenbild hervorhebt — und das mit deutlich weniger Expertenannotationen als herkömmliche Systeme.
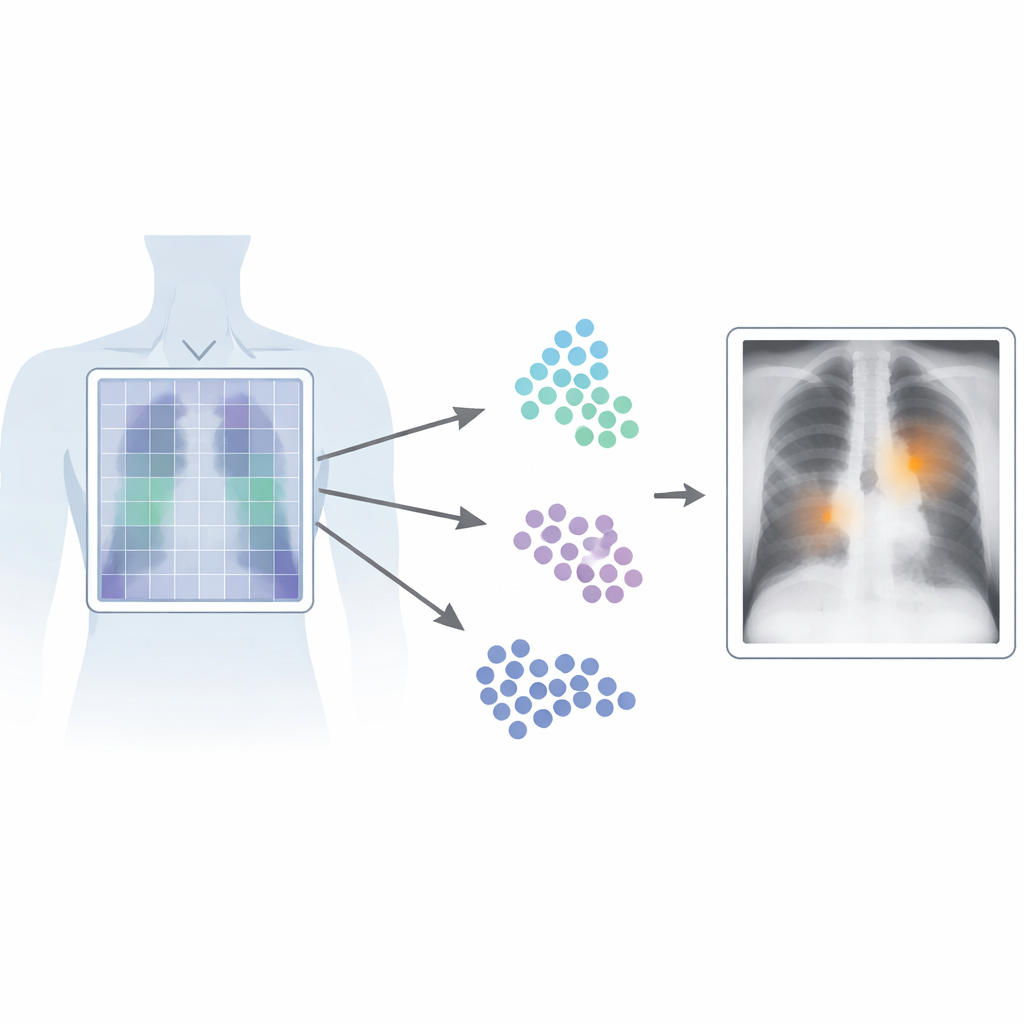
Warum es wichtig ist, die genaue Stelle zu finden
In der medizinischen Bildgebung sind Zeit und Präzision entscheidend. Aktuelle Vision‑Language‑Systeme lernen aus Bild‑Text‑Paaren und können so Muster erkennen, ohne mühsame Pixel‑genaue Labels von Expertinnen und Experten zu benötigen. Die meisten dieser Systeme behandeln das Bild jedoch als Ganzes, erfassen den allgemeinen Eindruck, verpassen aber feine Details. Das ist bei Thorax‑Röntgenaufnahmen problematisch, wo eine feine Linie oder ein kleiner Schatten auf eine ernsthafte Erkrankung hinweisen kann. Herkömmliche leistungsstarke Detektoren umgehen dieses Problem, indem sie an vielen sorgfältig gezeichneten Boxen um Auffälligkeiten trainieren, doch diese Art der Kennzeichnung ist teuer, zeitaufwändig und schwer zwischen Radiologinnen und Radiologen sowie Kliniken zu standardisieren.
Röntgenbilder Patch für Patch betrachten
Patch‑CLIP baut auf dem verbreiteten CLIP‑Framework auf, das Bilder und Texte gemeinsam lernt, und erweitert es so, dass es besser zu medizinischen Anforderungen passt. Statt nur eine einzige Zusammenfassung des gesamten Röntgenbilds zu erzeugen, repräsentiert die neue Methode das Bild zusätzlich als Gitter kleiner Patches. Jeder Patch wird in denselben abstrakten Raum abgebildet wie der Text, der einen medizinischen Befund beschreibt, etwa „Flüssigkeit in der Lunge“ oder „keine Flüssigkeit“. Die Autorinnen und Autoren führen zusätzliche Trainingsziele ein, die Gruppen relevanter Patches dazu anregen, sich wie lokale Detektoren zu verhalten: Patches, die über einer Auffälligkeit liegen, werden in diesem abstrakten Raum näher an den Text, der diese Auffälligkeit beschreibt, herangezogen, während Patches aus gesunden Bereichen in Richtung „kein Befund“ gezogen werden.
Das System mit weniger Labels trainieren
Zum Trainieren und Testen von Patch‑CLIP nutzten die Forschenden mehrere große Sammlungen von Thorax‑Röntgenaufnahmen mit zugehörigen radiologischen Berichten, darunter mehr als eine halbe Million Bilder. Die meisten davon wurden ohne detaillierte manuelle Markierungen verwendet; nur ein Teil von etwa 16.000 Bildern verfügte über von Expertinnen und Experten gezeichnete Boxen zu spezifischen Befunden. Zuerst lernt ein „Downscaler“-Netzwerk, wie die großen medizinischen Bilder am besten auf eine Auflösung verkleinert werden, die zu einem Standard‑Vision‑Language‑Modell passt, ohne wichtige Details zu verlieren. Während einer Feinjustierungsphase auf dem kleineren, fachlich annotierten Datensatz lehren die neuen patch‑basierten Verluste das Modell, bestimmte Teile des Bildgitters mit bestimmten Formulierungen der Berichte zu verbinden. Dieses Setup erlaubt dem System, gleichzeitig globale Entscheidungen („liegt ein Pneumothorax vor?“) und grobe Lokalisierungen („wo befindet er sich wahrscheinlich?“) zu lernen.
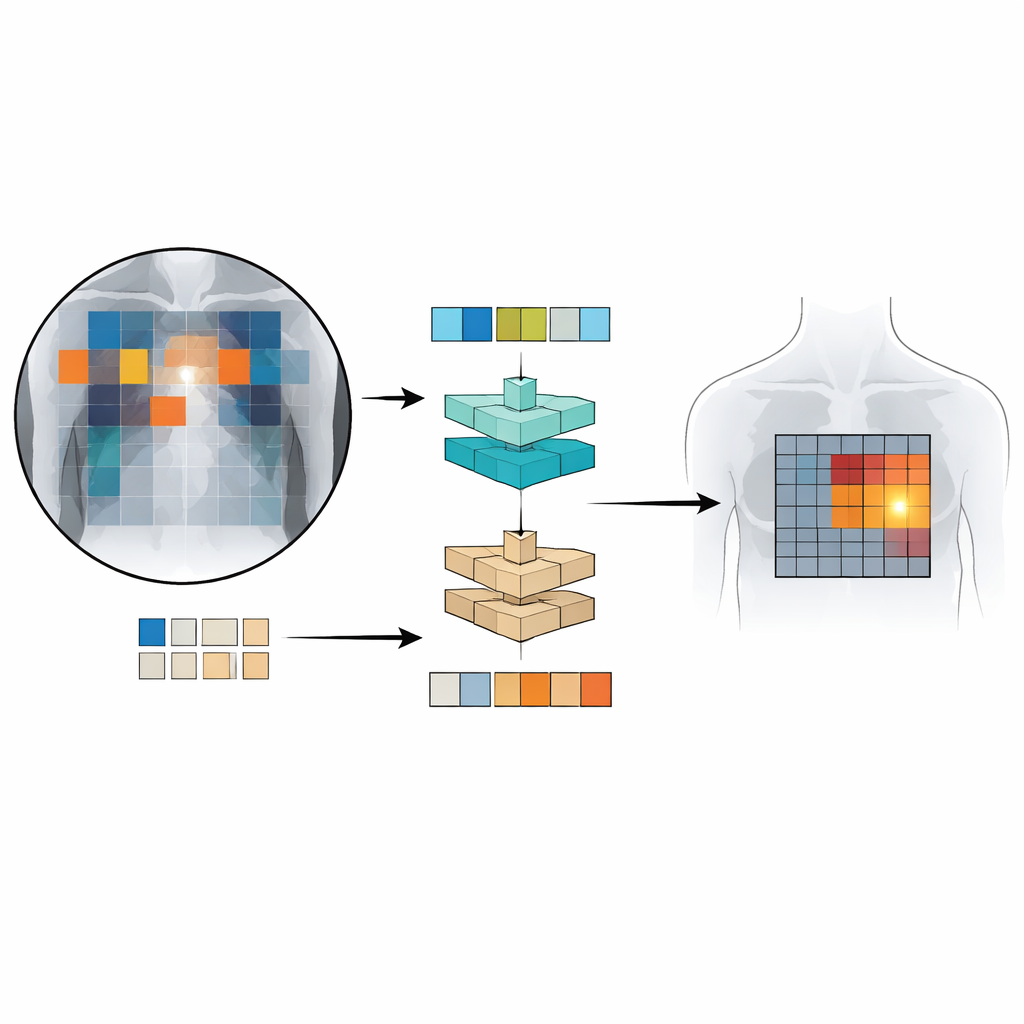
Wie gut funktioniert Patch‑CLIP?
Das Team verglich Patch‑CLIP mit starken kommerziellen Thorax‑Röntgen‑Detektoren und mit einem fortgeschrittenen Vision‑Language‑Detektionssystem, das ursprünglich für Alltagsfotografien entwickelt wurde. Anhand einer klinischen Bewertungsmetrik, die Sensitivität gegen die Zahl der Fehlalarme pro Bild abwägt, erzielte Patch‑CLIP bei mehreren Lungen‑ und Herzbefunden eine Spitzen‑ oder nahe Spitzenleistung. Wichtig ist, dass die patch‑basierten Karten von Patch‑CLIP weniger zufällig hervorgehobene Regionen erzeugten als Standard‑Attention, die häufig große, irrelevante Bereiche beleuchtet. Bei Erkrankungen, die tendenziell größere Bereiche des Thorax einnehmen, wie Flüssigkeitsansammlungen oder vergrößerte Herzgröße, lokalisierte die Methode Auffälligkeiten besonders gut. Für extrem kleine Befunde war sie weniger effektiv, da solche Befunde innerhalb eines einzelnen Patches liegen können — ein Hinweis darauf, dass noch feinere Bildgitter oder verbesserte Architekturen die Leistung weiter steigern könnten.
Was das für die zukünftige Versorgung bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft, dass Patch‑CLIP geschriebene Berichte, die bereits im klinischen Alltag entstehen, besser nutzt, um KI‑Systeme anzuleiten, wo auf einem Röntgenbild hingeschaut werden sollte. Durch das Abgleichen von Textbeschreibungen mit kleinen Bildregionen hilft es Computern, wichtige Befunde sowohl zu erkennen als auch grob zu lokalisieren — und das mit weniger detaillierten Expertenlabels. Es wird Radiologinnen und Radiologen nicht ersetzen, könnte aber als verlässlicheres „zweites Augenpaar“ dienen, das auf verdächtige Bereiche hinweist und gleichzeitig die Zahl der Fehlalarme gering hält. Wenn die Methode auf mehr Erkrankungen, höher aufgelöste Bilder und andere Bildgebungsarten ausgeweitet wird, könnte sie zu einem wichtigen Baustein für skalierbare, erklärbare medizinische KI werden.
Zitation: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Schlüsselwörter: KI für Thorax‑Röntgen, Lokalisierung medizinischer Bilder, Vision‑Language‑Modelle, schwach überwachte Lernverfahren, radiologische Computerunterstützung