Clear Sky Science · nl
PatchCLIP maakt regiogebaseerde contrastieve training van medische verslagen en beelden mogelijk met patch-embedding verlies
Slimmere hulp bij thoraxfoto's
Radiologen beoordelen elke dag thoraxfoto's om aandoeningen zoals longontsteking, pleuravocht of een klaplong te herkennen. Kunstmatige intelligentie kan al aangeven dat er “iets mis is” op een beeld, maar worstelt vaak met precies aanwijzen waar het probleem zich bevindt. Deze studie introduceert Patch‑CLIP, een nieuwe AI-methode die niet alleen zegt of er een afwijking is, maar ook de waarschijnlijke locatie op de röntgenfoto markeert, en dat met veel minder deskundige annotaties dan traditionele systemen.
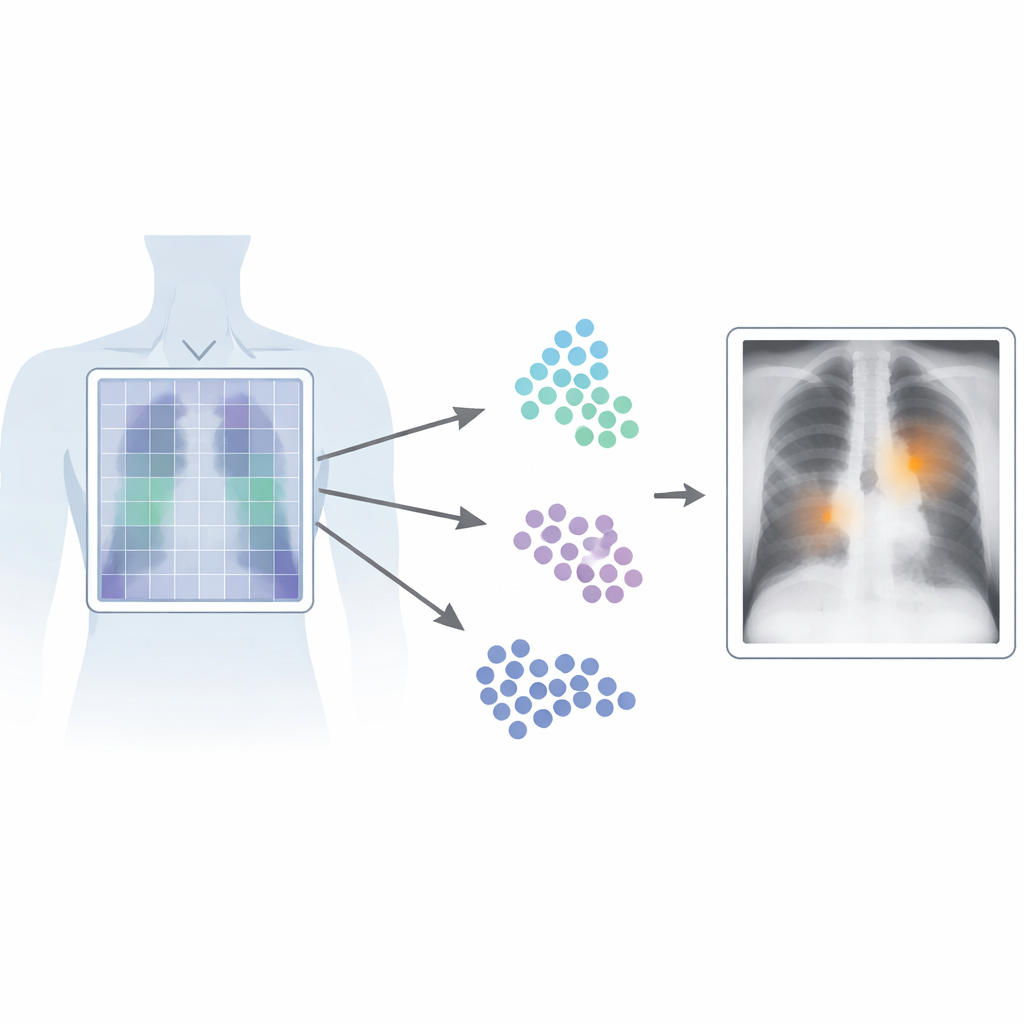
Waarom het exacte punt vinden belangrijk is
In medische beeldvorming zijn tijd en precisie cruciaal. Huidige vision‑language systemen leren uit paren van beelden en bijbehorende verslagen, waardoor ze patronen kunnen herkennen zonder moeizame pixel‑niveau labels van experts. De meeste van deze systemen behandelen het beeld echter als een geheel, waardoor ze de algemene strekking vastleggen maar fijnmazige details missen. Dat is problematisch bij thoraxfoto's, waar een subtiel lijntje of klein schaduwje op een ernstige aandoening kan wijzen. Conventionele hoogpresterende detectors lossen dit op door te trainen op veel zorgvuldig getekende kaders rond afwijkingen, maar dit soort labeling is duur, traag en moeilijk te standaardiseren tussen radiologen en ziekenhuizen.
Thoraxfoto's patch voor patch bekijken
Patch‑CLIP bouwt voort op het populaire CLIP‑framework, dat gelijktijdig van beelden en tekst leert, en breidt dit uit op een manier die beter aansluit bij medische behoeften. In plaats van alleen een enkele samenvatting van de hele röntgenfoto te produceren, representeert de nieuwe methode het beeld ook als een raster van kleine patches. Elke patch wordt afgebeeld in dezelfde abstracte ruimte als de tekst die een medische bevinding beschrijft, zoals “vocht in de long” of “geen vocht.” De auteurs introduceren extra trainingsdoelen die groepen relevante patches aanmoedigen te functioneren als lokale detectors: patches die overlappen met een afwijkend gebied worden in deze abstracte ruimte dichter bij de tekst die die afwijking beschrijft gebracht, terwijl patches uit gezonde gebieden naar “geen bevinding” worden getrokken.
Het systeem onderwijzen met minder labels
Om Patch‑CLIP te trainen en te testen gebruikten de onderzoekers meerdere grote verzamelingen thoraxfoto's gekoppeld aan radiologierapporten, in totaal meer dan een half miljoen beelden. Het merendeel daarvan werd gebruikt zonder gedetailleerde handmatige markeringen; slechts een subset van ongeveer 16.000 beelden had door experts getekende kaders rond specifieke bevindingen. Eerst leert een “downscaler”-netwerk hoe de grote medische beelden het beste kunnen worden verkleind naar een resolutie die past bij een standaard vision‑language model, terwijl belangrijke details behouden blijven. Vervolgens, tijdens een fijnslijpfase op de kleinere, deskundig geannoteerde set, leren de nieuwe patch‑gebaseerde verliesfuncties het model om bepaalde delen van het beeldraster met specifieke zinnen uit de rapporten te verbinden. Deze opzet laat het systeem tegelijk globale beslissingen (“is er een pneumothorax?”) én grove lokalisatie (“waar bevindt het zich waarschijnlijk?”) leren.
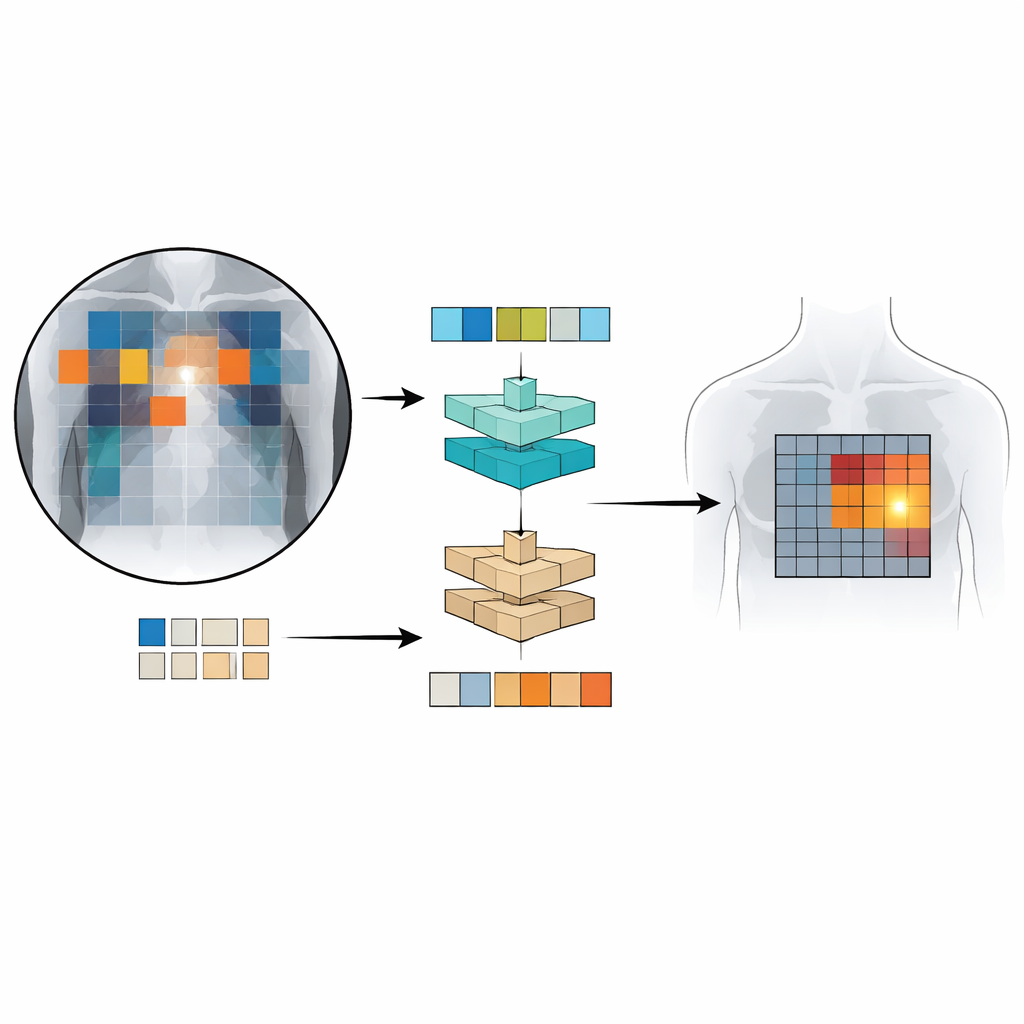
Hoe goed presteert Patch‑CLIP?
Het team vergeleek Patch‑CLIP met sterke commerciële thoraxdetectors en met een geavanceerd vision‑language detectiesysteem dat oorspronkelijk voor alledaagse foto’s is ontwikkeld. Met een klinische evaluatiemaat die sensitiviteit afweegt tegen het aantal valse alarmen per beeld, behaalde Patch‑CLIP state‑of‑the‑art of bijna state‑of‑the‑art prestaties op meerdere long‑ en hartbevindingen. Belangrijk is dat de patch‑gebaseerde kaarten van Patch‑CLIP minder spuriueze gemarkeerde gebieden produceerden dan standaard attention, dat vaak grote, irrelevante zones activeert. Voor aandoeningen die neigen grotere delen van de borstkas in te nemen, zoals vochtophoping of vergrote hartomvang, lokaliseerde de methode afwijkingen bijzonder goed. Het was minder effectief voor extreem kleine bevindingen die binnen één enkele patch kunnen vallen, wat suggereert dat nog fijnere beeldrasters of verbeterde architecturen de prestatie verder kunnen verhogen.
Wat dit betekent voor toekomstige zorg
Voor niet‑specialisten is de kernboodschap dat Patch‑CLIP beter gebruikmaakt van de geschreven rapporten die al in de dagelijkse klinische praktijk worden gemaakt om AI‑systemen te leren waar ze op een röntgenfoto moeten kijken. Door tekstbeschrijvingen te aligneren met kleine beeldregio's helpt het computers zowel belangrijke bevindingen te herkennen als globaal te lokaliseren met minder gedetailleerde labels van experts. Hoewel het radiologen niet zal vervangen, kan deze aanpak fungeren als een betrouwbaardere “tweede paar ogen” dat verdachte gebieden aanwijst terwijl het aantal valse alarmen laag blijft. Naarmate de methode wordt uitgebreid naar meer ziekten, hogere resolutie beelden en zelfs andere beeldvormingsmodaliteiten, kan het een belangrijk bouwsteen worden voor schaalbare, uitlegbare medische AI.
Bronvermelding: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Trefwoorden: AI voor thoraxfoto's, lokalisatie van medische beelden, vision-language modellen, zwak-gesuperviseerd leren, computerondersteuning in radiologie