Clear Sky Science · tr
PatchCLIP, yama gömme kaybı ile bölgeye özgü kontrastif sağlık kaydı ve görüntü ortak eğitimi sağlar
Göğüs Röntgenlerinden Daha Akıllı Yardım
Radyologlar her gün zatürre, akciğer etrafında sıvı veya akciğer sönmesi gibi durumları tespit etmek için göğüs röntgenlerini inceler. Yapay zekâ şimdiden bir görüntüde “bir şeyler yanlış” diyebiliyor, ancak sorunun tam olarak nerede olduğunu işaretlemekte çoğu zaman zorlanıyor. Bu çalışma, yalnızca bir anormallik olup olmadığını söylemekle kalmayıp aynı zamanda röntgende olası konumunu vurgulamayı amaçlayan ve geleneksel sistemlere kıyasla çok daha az uzman açıklaması gerektiren yeni bir yapay zekâ yöntemi olan Patch‑CLIP'i sunuyor.
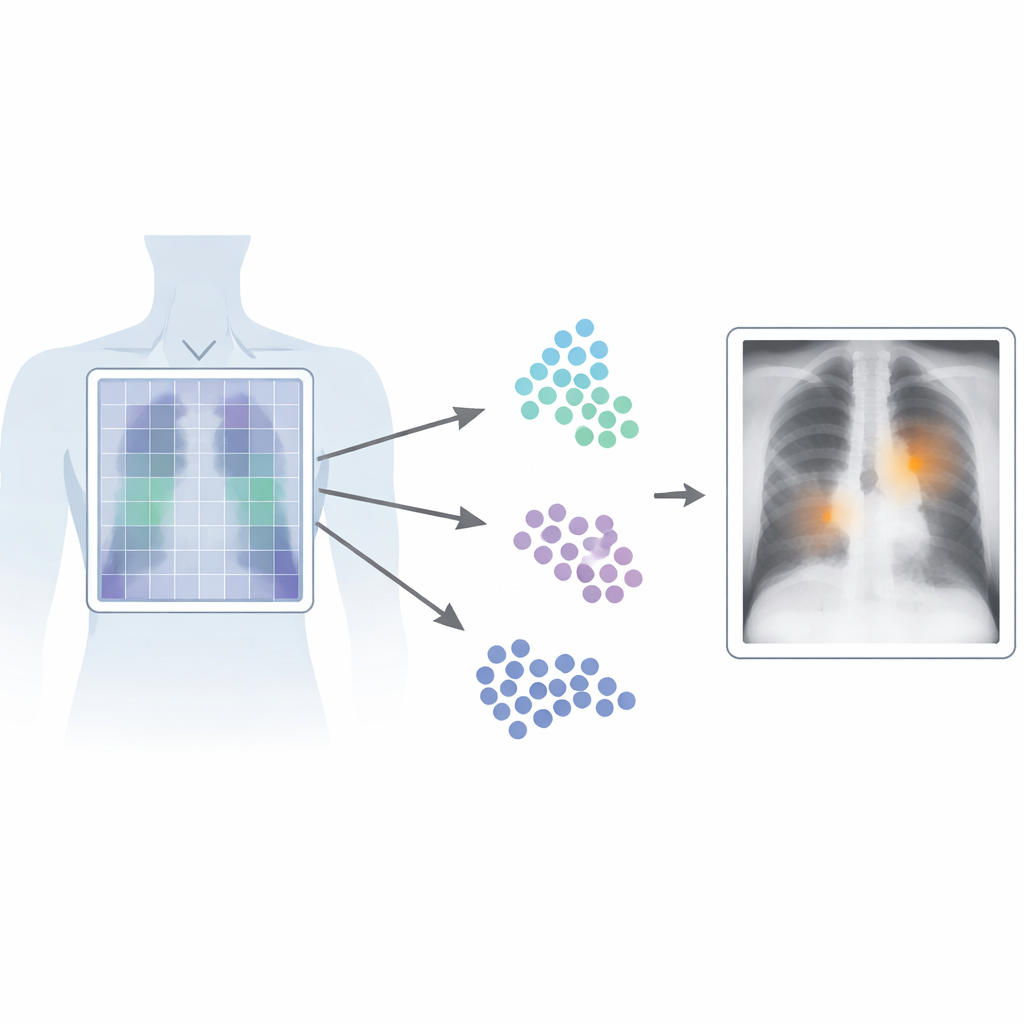
Doğru Noktayı Bulmanın Önemi
Tıbbi görüntülemede zaman ve hassasiyet kritik öneme sahiptir. Mevcut görsel‑dil sistemleri, görüntüler ile eşlik eden rapor çiftlerinden öğrenir; bu da uzmanların pikselseviyede etiketleme zahmetine girmeden kalıpları tanımalarını sağlar. Ancak bu sistemlerin çoğu görüntüyü bir bütün olarak ele alır, “genel izlenimi” yakalar fakat ince ayrıntıları kaçırır. Oysa göğüs röntgenlerinde ince bir çizgi ya da küçük bir gölge ciddi bir durumu işaret edebilir. Geleneksel yüksek performanslı algılayıcılar, anormalliklerin etrafına dikkatle çizilmiş çok sayıda kutu üzerinde eğitilerek bunu aşar, fakat bu tür etiketleme pahalı, yavaş ve radyologlar ile hastaneler arasında standartlaştırılması zordur.
Röntgeni Yama Yama İncelemek
Patch‑CLIP, görüntüler ve metinlerden ortak öğrenme yapan popüler CLIP çerçevesine dayanır ve bunu tıbbi ihtiyaçlara daha uygun şekilde genişletir. Yeni yöntem yalnızca tüm röntgenin tek bir özetini üretmek yerine görüntüyü küçük yamalardan oluşan bir ızgara olarak da temsil eder. Her yama, “akciğerde sıvı” veya “sıvı yok” gibi tıbbi bir bulguyu tanımlayan metin ile aynı soyut uzaya eşlenir. Yazarlar, ilgili yama gruplarının yerel algılayıcılar gibi davranmasını teşvik eden ek eğitim hedefleri getirir: bir anormal bölgeyle örtüşen yamalar, o anormalliği tanımlayan metne bu soyut uzayda daha yakınlaştırılırken, sağlıklı bölgelerden gelen yamalar “bulgu yok” ifadesine çekilir.
Sistemi Daha Az Etiketle Eğitmek
Patch‑CLIP'i eğitmek ve test etmek için araştırmacılar, radyoloji raporlarıyla eşleştirilmiş birkaç büyük göğüs röntgeni koleksiyonu kullandı; bunların arasında yarımdan fazla yarım milyon görüntü bulunuyordu. Bunların çoğu ayrıntılı manuel işaretleme olmadan kullanıldı; yalnızca yaklaşık 16.000 görüntüden oluşan bir alt kümede uzmanlar tarafından çizilmiş kutular mevcuttu. Önce, bir “küçültücü” ağ, büyük tıbbi görüntüleri standart bir görsel‑dil modeline uyan bir çözünürlüğe nasıl en iyi şekilde küçülteceğini öğrenirken önemli ayrıntıları korumayı öğrenir. Ardından, uzman tarafından açıklamalı daha küçük kümede ince ayar aşamasında, yeni yama‑tabanlı kayıplar modelin görüntü ızgarasının belirli parçalarını raporlardaki belirli ifadelerle ilişkilendirmesini öğretir. Bu yapı, sistemin hem küresel kararları (“pnömotoraks var mı?”) hem de kaba yerelleştirmeyi (“muhtemelen nerede yer alıyor?”) aynı anda öğrenmesine olanak tanır.
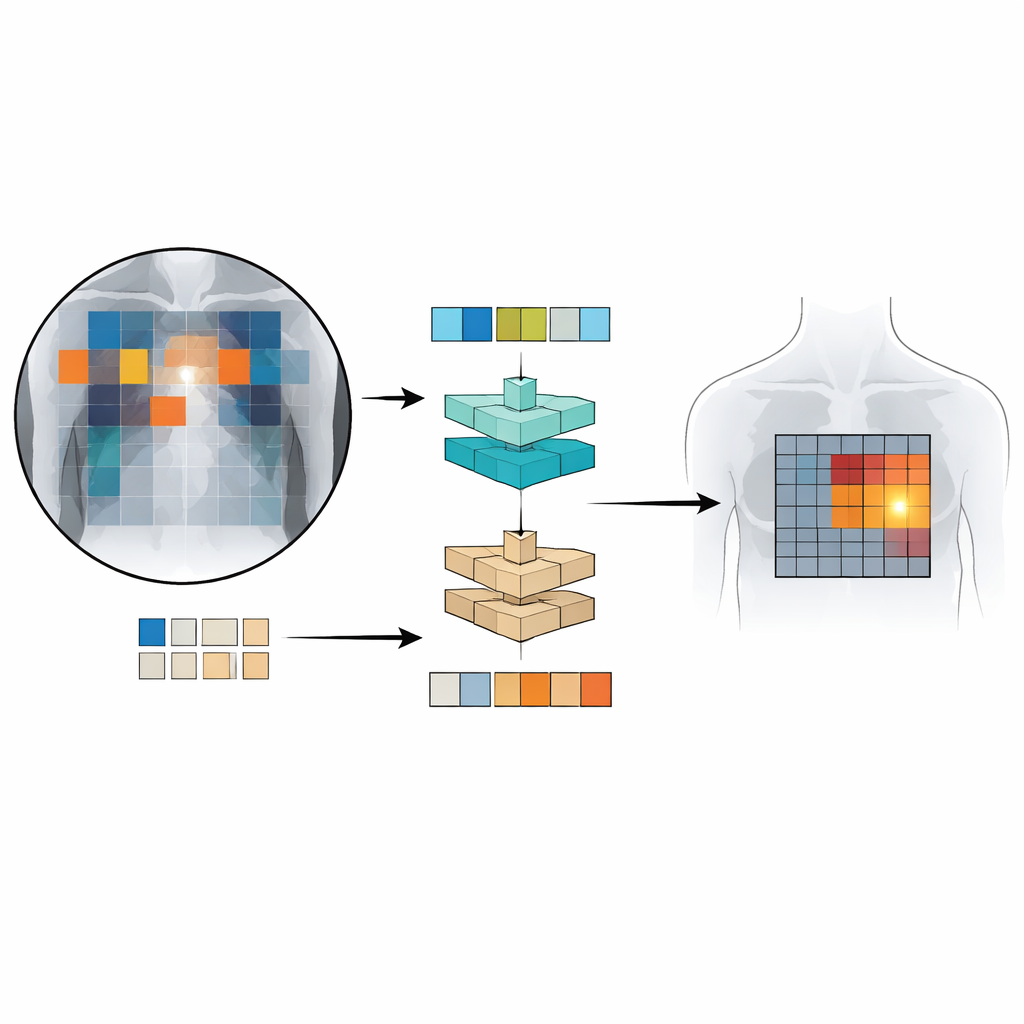
Patch‑CLIP Ne Kadar İyi Çalışıyor?
Ekip, Patch‑CLIP'i güçlü ticari göğüs röntgeni algılayıcıları ve günlük fotoğraflar için geliştirilmiş ileri bir görsel‑dil algılama sistemiyle karşılaştırdı. Hassasiyeti görüntü başına düşen yanlış alarmların sayısıyla dengeleyen klinik bir değerlendirme ölçütü kullanıldığında, Patch‑CLIP birçok akciğer ve kalp bulgusunda en iyi veya en iyiye yakın performans gösterdi. Önemli olarak, Patch‑CLIP tarafından üretilen yama‑tabanlı haritalar, genellikle büyük alakasız bölgeleri aydınlatan standart dikkat mekanizmalarından daha az yanlış vurgulanmış bölge üretti. Sıvı birikimi veya büyümüş kalp boyutu gibi göğsün daha geniş bölgelerini kaplama eğiliminde olan koşullar için yöntem anormallikleri özellikle iyi yerelleştirdi. Çok küçük bulgular için ise, tek bir yama içinde kalabilecekleri durumlarda daha az etkili oldu; bu da daha ince görüntü ızgaraları veya geliştirilmiş mimarilerin performansı daha da artırabileceğini işaret ediyor.
Gelecekteki Bakım İçin Anlamı
Uzman olmayanlar için temel mesaj şudur: Patch‑CLIP, günlük klinik uygulamada hâlihazırda oluşturulan yazılı raporlardan yapay zekâ sistemlerini nereye bakacakları konusunda öğretmek için daha iyi şekilde yararlanır. Metin açıklamalarını küçük görüntü bölgeleri ile hizalayarak, bilgisayarların önemli bulguları tanımasına ve daha az uzman etiketine ihtiyaç duyarak kabaca yerelleştirmesine yardımcı olur. Radyologların yerini almayacak olsa da bu yaklaşım, şüpheli bölgeleri işaret ederken yanlış alarmların sayısını düşük tutan daha güvenilir bir “ikinci göz” görevi görebilir. Yöntem daha fazla hastalığa, daha yüksek çözünürlüklü görüntülere ve hatta diğer görüntüleme türlerine genişledikçe, ölçeklenebilir ve açıklanabilir tıbbi yapay zekâ için önemli bir yapı taşı haline gelebilir.
Atıf: Bhat, S., Mansoor, A., Georgescu, B. et al. PatchCLIP enables region specific contrastive health record and image joint training with patch embedding loss. Sci Rep 16, 14688 (2026). https://doi.org/10.1038/s41598-026-52235-x
Anahtar kelimeler: göğüs röntgeni yapay zekâsı, tıbbi görüntü yerelleştirme, görsel-dil modelleri, zayıf denetimli öğrenme, radyoloji bilgisayar destekliği