Clear Sky Science · zh
使用 SuperPoint 与语义几何动态特征检测的增强视觉惯性 SLAM
在移动世界中更智能的导航
机器人、无人机与增强现实头显在周围环境持续移动的情况下,仍需准确知道自身位置。传统的建图系统容易被来往的行人或车辆干扰,可能导致虚拟指示偏离道路或机器人误判路径。本研究提出了 SuperDynaSLAM,一种旨在在繁忙且变化的场景中更可靠地跟踪位置的导航方法,它利用现代人工智能工具与运动传感器来实现这一目标。
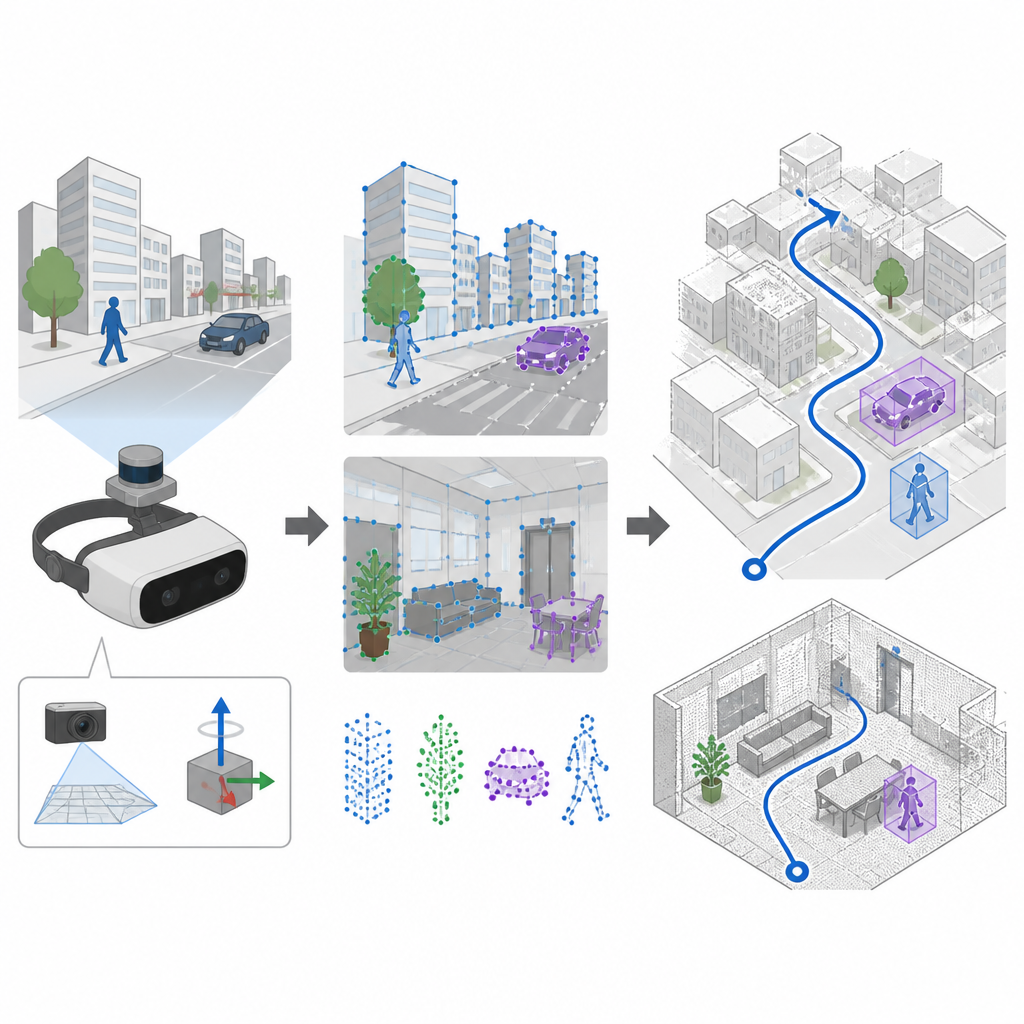
视觉与惯性共同感知运动
许多导航系统依赖摄像头和一种名为 SLAM 的技术,同时构建地图并估计自身位姿。较早的系统用人工设计的规则在图像中挑出显著点,这些方法在平静、光照良好的场景中表现不错,但在相机抖动或光照快速变化时常常失效。SuperDynaSLAM 用一种名为 SuperPoint 的学习型特征检测器升级了这一前端;SuperPoint 在大量真实场景视图上训练,因而能在相机剧烈移动或视角变化较大时识别出可靠的视觉锚点。该系统还利用机载惯性测量单元来测量相邻相机帧之间设备的旋转与加速度变化。
将背景与移动物体分离
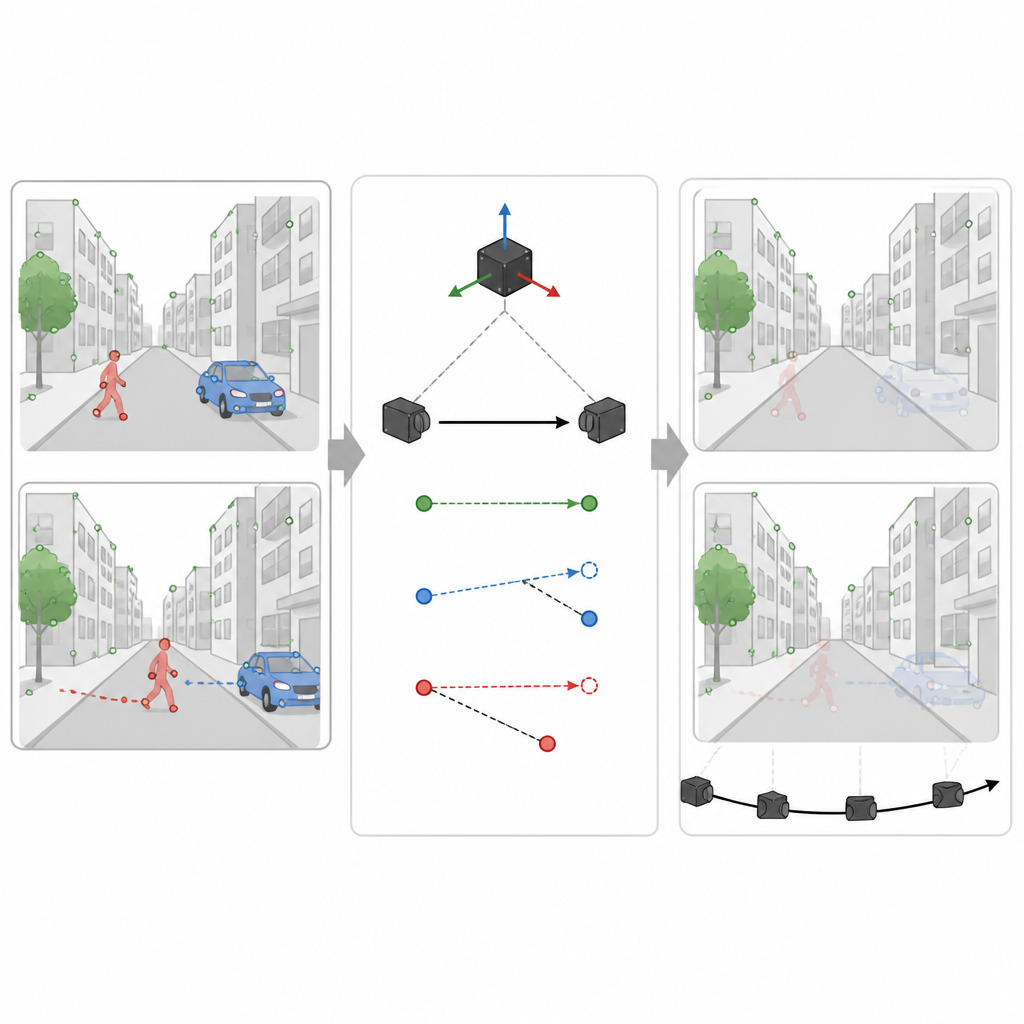
对任何基于视觉的导航器来说,一个主要挑战是并非视野中的所有物体都固定不动。行人、车辆及其他移动物体会产生误导性的视觉线索。SuperDynaSLAM 通过两阶段流程来应对这一问题。首先,它对每帧图像应用一种称为 Mask R-CNN 的深度学习程序,为可能移动的物体(如车辆与行人)绘制粗略轮廓。随后 SuperPoint 检测到的特征点根据其所在区域被分为三类:背景、车辆与行人。仅允许在同一类别内进行特征匹配,这一策略已经减少了明显的混淆,例如将建筑角点匹配到一辆经过的汽车上。
利用运动线索识别真实移动
然而,并非所有呈车或人形的区域在任意时刻都在移动。停放的车辆应当有助于建图,而非妨碍。在第二阶段,SuperDynaSLAM 使用惯性传感器读数来推算场景中一个真正固定点在两帧之间应有的位移。它将此预期位移与相机实际观测到的位移进行比较,针对每个可能移动的物体采样若干点。如果物体上的点偏离预期路径过远,系统判断该物体在移动,并将其所有点标记为不可信;若它们保持接近,则将该物体视为稳定场景的一部分。这种选择性过滤使系统能够丢弃误导信息,同时尽可能保留有用细节。
在虚拟街道、办公区与市场中的测试
研究人员在三组具有挑战性的数据集上测试了 SuperDynaSLAM。一组来自真实的室内飞行,伴有快速运动与光照变化;另一组是可调节交通密度的模拟城市与停车场,从空旷街道到车流密集均可设置;第三组是机器人穿行于真实的办公区、住宅、市场与咖啡馆,环境中充满移动的顾客与杂乱物品。在大多数试验中,尤其是在移动物体众多或相机剧烈运动时,SuperDynaSLAM 比依赖旧式视觉特征或仅使用单一线索的领先系统更贴近真实轨迹且抖动更小。
对日常导航的意义
对普通读者而言,关键点是 SuperDynaSLAM 帮助机器关注场景中坚实可靠的部分,并过滤掉干扰性的运动。通过结合学习到的视觉特征、目标感知与运动感应,它能构建更精确的地图并更稳定地追踪自身位置,即便在拥挤或快速变化的环境中也是如此。尽管这会带来更高的计算开销,且系统仍可能漏检罕见的移动物体,但该方法代表了朝向更可靠导航(如无人驾驶汽车、配送机器人以及沉浸式虚拟或混合现实设备)的一步实用进展。
引用: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
关键词: 视觉惯性 SLAM, 动态环境, 特征提取, 机器人导航, 计算机视觉