Clear Sky Science · fr
SLAM visuo-inertiel amélioré utilisant SuperPoint et détection sémantique de caractéristiques géométriques dynamiques
Une navigation plus intelligente dans un monde en mouvement
Les robots, drones et casques de réalité augmentée doivent connaître précisément leur position alors que le monde autour d’eux est en mouvement constant. Les systèmes de cartographie traditionnels peuvent être perturbés par des piétons ou des voitures qui passent, ce qui peut faire dériver des flèches numériques hors de la route ou amener un robot à mal estimer sa trajectoire. Cette étude présente SuperDynaSLAM, une méthode de navigation conçue pour mieux suivre la position dans des scènes encombrées et changeantes, en s’appuyant sur des outils modernes d’intelligence artificielle et des capteurs de mouvement.
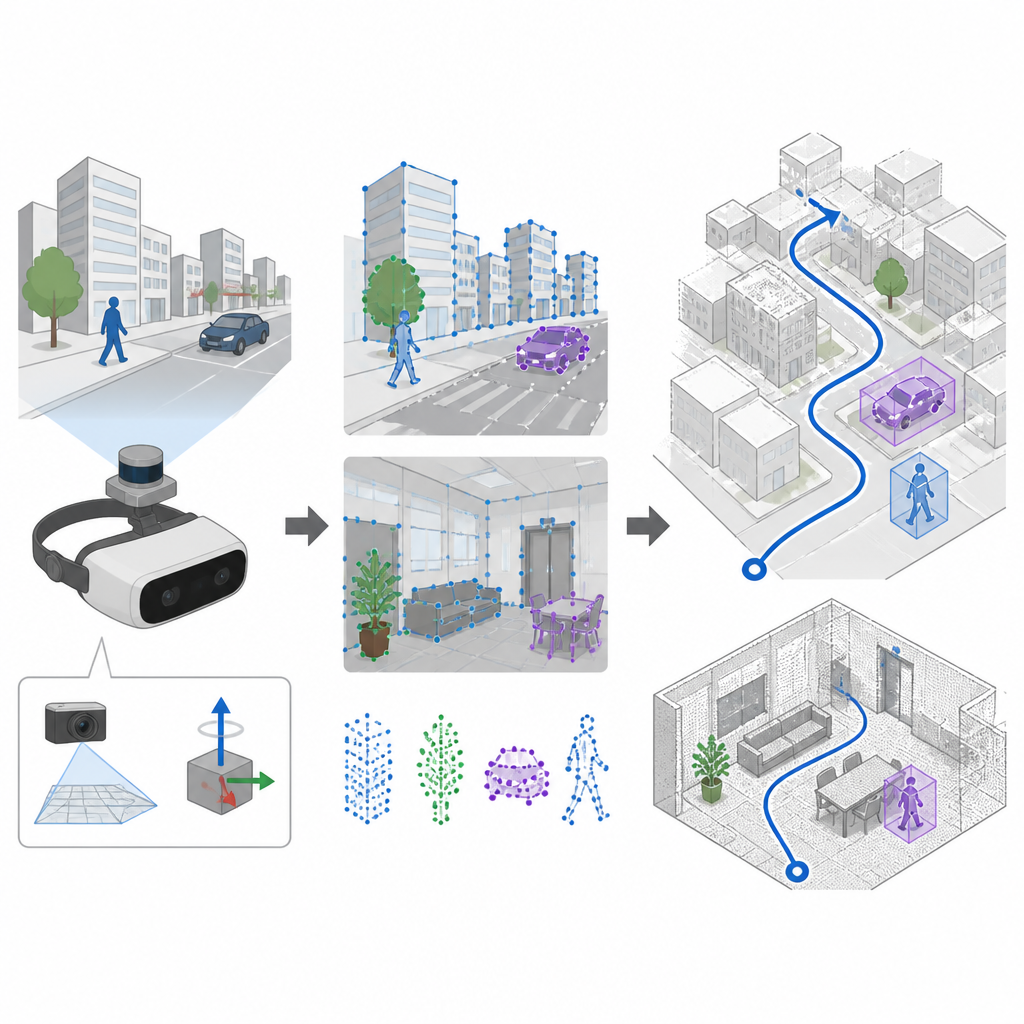
Voir et sentir le mouvement ensemble
De nombreux systèmes de navigation utilisent des caméras et une technique appelée SLAM pour construire une carte et se localiser simultanément. Les approches anciennes détectent des points distinctifs dans l’image à l’aide de règles fabriquées à la main, efficaces dans des scènes calmes et bien éclairées, mais souvent défaillantes lorsque la caméra bouge brusquement ou que l’éclairage change rapidement. SuperDynaSLAM améliore cette étape initiale en utilisant un détecteur de caractéristiques appris appelé SuperPoint, entraîné sur de nombreuses vues de scènes réelles pour reconnaître des ancres visuelles fiables même lors de forts mouvements de caméra ou de changements de point de vue importants. Le système exploite aussi une unité de mesures inertielles embarquée, qui mesure la rotation et l’accélération de l’appareil entre deux images.
Séparer l’arrière-plan des objets en mouvement
Un défi majeur pour tout système de navigation visuelle est que tout ce qui est dans le champ de vision n’est pas forcément fixé. Les personnes, les voitures et d’autres objets mobiles créent des indices visuels trompeurs. SuperDynaSLAM s’attaque à ce problème avec un processus en deux étapes. D’abord, il applique à chaque image un modèle de deep learning appelé Mask R-CNN pour tracer des contours approximatifs autour des objets susceptibles de se déplacer, comme les véhicules et les piétons. Les points de caractéristiques trouvés par SuperPoint sont ensuite regroupés en trois types simples selon leur position : arrière-plan, véhicules et piétons. L’appariement des points n’est autorisé qu’à l’intérieur d’un même type, ce qui réduit déjà les confusions évidentes, par exemple associer un coin de bâtiment à une voiture qui passe.
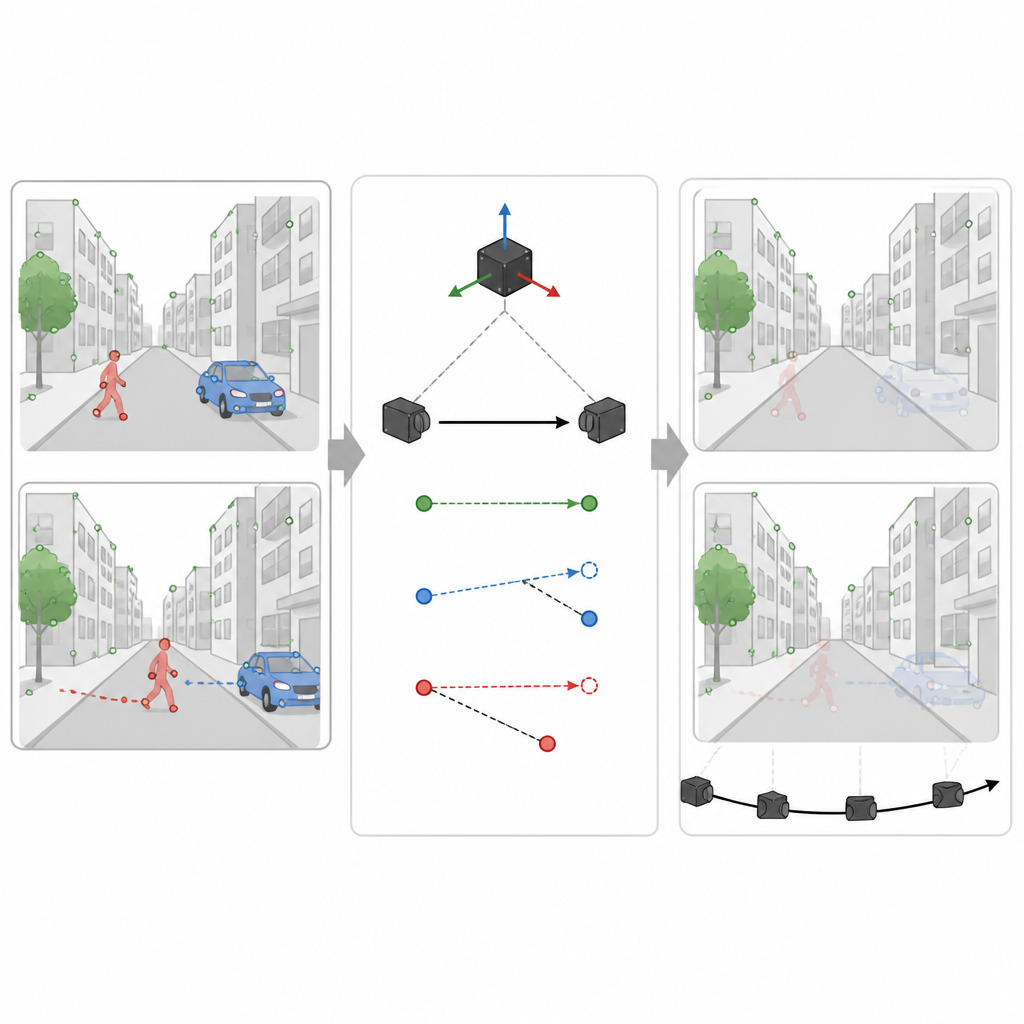
Utiliser les indices de mouvement pour repérer ce qui bouge vraiment
Cependant, toute région ayant la forme d’une voiture ou d’une personne n’est pas nécessairement en mouvement à un instant donné. Une voiture garée doit aider la carte, pas la dégrader. Dans la seconde étape, SuperDynaSLAM utilise les relevés du capteur de mouvement pour calculer comment un point réellement fixe de la scène devrait se déplacer entre deux images. Il compare ce déplacement attendu à ce que la caméra observe pour quelques points d’échantillonnage sur chaque objet potentiellement mobile. Si les points d’un objet s’écartent trop du trajet attendu, le système conclut que l’objet est en mouvement et marque tous ses points comme non fiables. S’ils restent proches, l’objet est considéré comme faisant partie de la scène stable. Ce filtrage sélectif permet d’éliminer les informations trompeuses tout en conservant le plus possible de détails utiles.
Testé dans des rues virtuelles, bureaux et marchés
Les chercheurs ont évalué SuperDynaSLAM sur trois ensembles de données exigeants. Le premier provient de vols intérieurs réels avec des mouvements rapides et des variations d’éclairage. Le second est une ville et un parking simulés où le trafic peut être réglé de rues vides à un flux dense. Le troisième correspond à un robot se déplaçant dans des bureaux, des maisons, des marchés et des cafés réels remplis de clients en mouvement et d’encombrements. Dans la plupart de ces essais, en particulier lorsque le nombre d’objets en mouvement était élevé ou que le mouvement de la caméra était prononcé, SuperDynaSLAM a suivi le trajet réel plus fidèlement et avec moins de secousses que les systèmes de pointe reposant sur des descripteurs visuels plus anciens ou sur un seul type d’indice.
Ce que cela signifie pour la navigation quotidienne
Pour un non-spécialiste, le message essentiel est que SuperDynaSLAM aide les machines à se concentrer sur ce qui est solide et fiable dans une scène et à ignorer les mouvements distrayants. En combinant des descripteurs visuels appris, une conscience des objets et la mesure du mouvement, il construit des cartes plus exactes et suit sa position de façon plus stable, même dans des environnements bondés ou rapidement changeants. Bien que cela entraîne un coût de calcul plus élevé et que le système puisse encore manquer des objets mobiles atypiques, l’approche représente une avancée pratique vers une navigation plus fiable pour les voitures sans conducteur, les robots de livraison et les dispositifs de réalité virtuelle ou mixte immersifs.
Citation: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Mots-clés: SLAM visuo-inertiel, environnements dynamiques, extraction de caractéristiques, navigation robotique, vision par ordinateur