Clear Sky Science · sv
Förbättrad visuell-inertial SLAM med SuperPoint och semantisk geometrisk detektion av dynamiska funktioner
Smartare navigation i en rörlig värld
Robotar, drönare och förstärkningsglasögon behöver veta exakt var de befinner sig samtidigt som världen runt dem rör sig. Traditionella kartläggningssystem kan förvirras av gående personer eller passerande bilar, vilket kan få digitala pilar att driva av vägen eller en robot att felbedöma sin färd. Denna studie introducerar SuperDynaSLAM, en navigationsmetod utformad för att hålla bättre koll på positionen i livliga, föränderliga scener genom att använda moderna artificiella intelligensverktyg och rörelsesensorer.
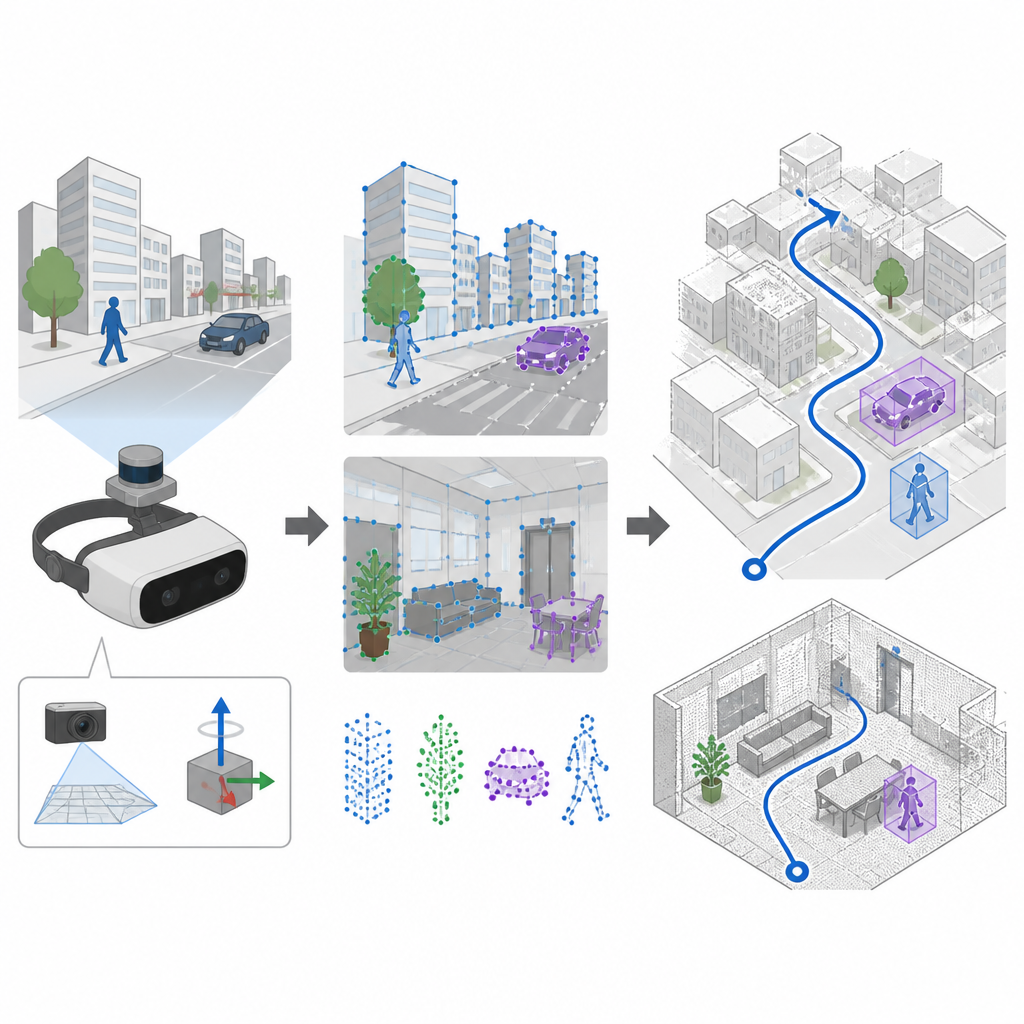
Samma tid se och känna rörelse
Många navigationssystem förlitar sig på kameror och en teknik som kallas SLAM för att samtidigt bygga en karta och följa sin bana. Äldre system hittar karakteristiska punkter i bilden med handgjorda regler, vilket fungerar bra i lugna, välbelysta scener men ofta misslyckas när kameran skakar eller ljuset ändras snabbt. SuperDynaSLAM uppgraderar detta front-end genom att använda en inlärd funktionsdetektor kallad SuperPoint, som har tränats på många vyer av verkliga scener så att den kan känna igen pålitliga visuella ankare även när kameran rör sig våldsamt eller vyn ändras mycket. Systemet använder också en inbyggd rörelsesensorenhet som mäter hur enheten roterar och accelererar mellan kamerabildrutorna.
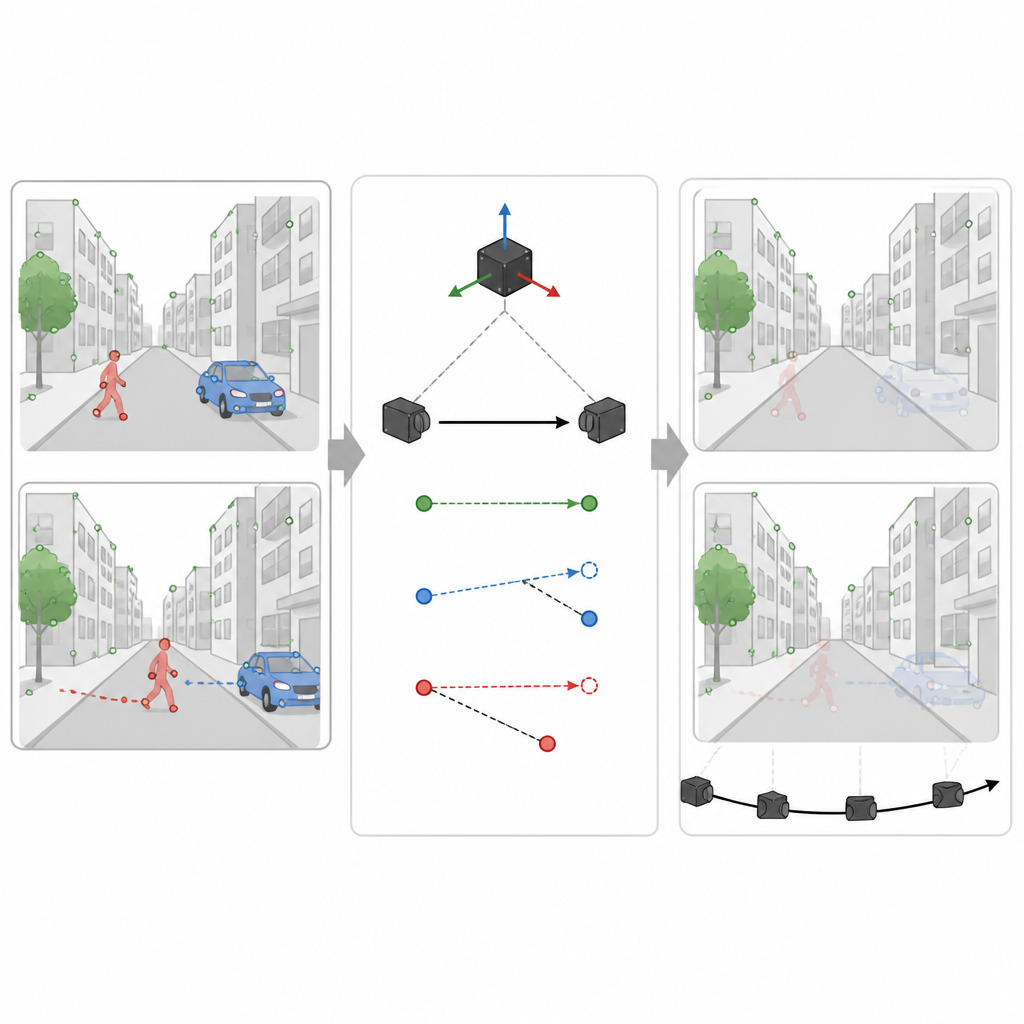
Separera bakgrund från rörliga objekt
En stor utmaning för alla visionsbaserade navigatörer är att inte allt i synfältet sitter fast. Människor, bilar och andra rörliga objekt skapar vilseledande visuella ledtrådar. SuperDynaSLAM hanterar detta med en tvåstegsprocess. Först applicerar den ett djupinlärningsprogram kallat Mask R-CNN på varje bild för att dra grova konturer kring objekt som kan röra sig, såsom fordon och fotgängare. De funktionspunkter som SuperPoint hittar grupperas sedan i tre enkla typer beroende på var de faller: bakgrund, fordon och fotgängare. Matchning av punkter tillåts endast inom samma typ, vilket redan minskar uppenbara förväxlingar, som att para ihop ett byggnadshörn med en passerande bil.
Använda rörelsesignaler för att upptäcka vad som verkligen rör sig
Men inte varje bil- eller personformad region rör sig vid ett givet tillfälle. En parkerad bil borde hjälpa kartan, inte skada den. I det andra steget använder SuperDynaSLAM rörelsesensorns avläsningar för att räkna ut hur en verkligt fixerad punkt i scenen bör förskjutas mellan två kamerabilder. Den jämför denna förväntade förskjutning med vad kameran faktiskt ser för några provpunkter på varje objekt som kan röra sig. Om punkter på ett objekt avviker för mycket från den förväntade banan drar systemet slutsatsen att objektet rör sig och markerar alla dess punkter som opålitliga. Om de håller sig nära behandlas objektet som en del av den stabila scenen. Denna selektiva filtrering gör att systemet kan kasta bort vilseledande information samtidigt som så många användbara detaljer som möjligt behålls.
Testat i virtuella gator, kontor och marknader
Forskarna testade SuperDynaSLAM på tre krävande datainsamlingar. Ett set kom från verkliga inomhusflygningar med snabba rörelser och skiftande ljus. Ett annat var en simulerad stad och parkeringsplats där trafiknivåerna kunde justeras från tomma gator till tät trafik. Det tredje var en robot som körde genom verkliga kontor, hem, marknader och kaféer fyllda med rörliga kunder och röra. I de flesta av dessa tester, särskilt när det fanns många rörliga objekt eller kraftig kamerarörelse, följde SuperDynaSLAM den verkliga banan närmare och med mindre jitter än ledande system som förlitar sig på äldre visuella drag eller endast en typ av ledtråd.
Vad detta betyder för vardaglig navigation
För en lekmannabetraktare är huvudbudskapet att SuperDynaSLAM hjälper maskiner att fokusera på vad som är solidt och pålitligt i en scen och stänga av störande rörelser. Genom att kombinera inlärda visuella drag, objektmedvetenhet och rörelsesensorik bygger det mer precisa kartor och spårar sin position mer stabilt, även i trånga eller snabbt föränderliga miljöer. Även om detta medför högre beräkningskostnader och systemet fortfarande kan missa ovanliga rörliga objekt, markerar angreppssättet ett praktiskt steg mot mer pålitlig navigation för självkörande bilar, leveransrobotar och immersiva virtuella eller mixed reality-enheter.
Citering: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Nyckelord: visuell inertial SLAM, dynamiska miljöer, funktionsutvinning, robotnavigering, datorseende