Clear Sky Science · pt
SLAM visual-inercial aprimorado usando SuperPoint e detecção semântica geométrica de features dinâmicas
Navegação mais inteligente em um mundo em movimento
Robôs, drones e headsets de realidade aumentada precisam saber exatamente onde estão enquanto o mundo ao redor continua em movimento. Sistemas de mapeamento tradicionais podem se confundir com pessoas caminhando ou carros passando, o que pode fazer setas digitais desviarem da estrada ou um robô julgar mal seu percurso. Este estudo apresenta o SuperDynaSLAM, um método de navegação projetado para acompanhar a posição de forma mais confiável em cenas movimentadas e mutáveis, usando ferramentas modernas de inteligência artificial e sensores de movimento.
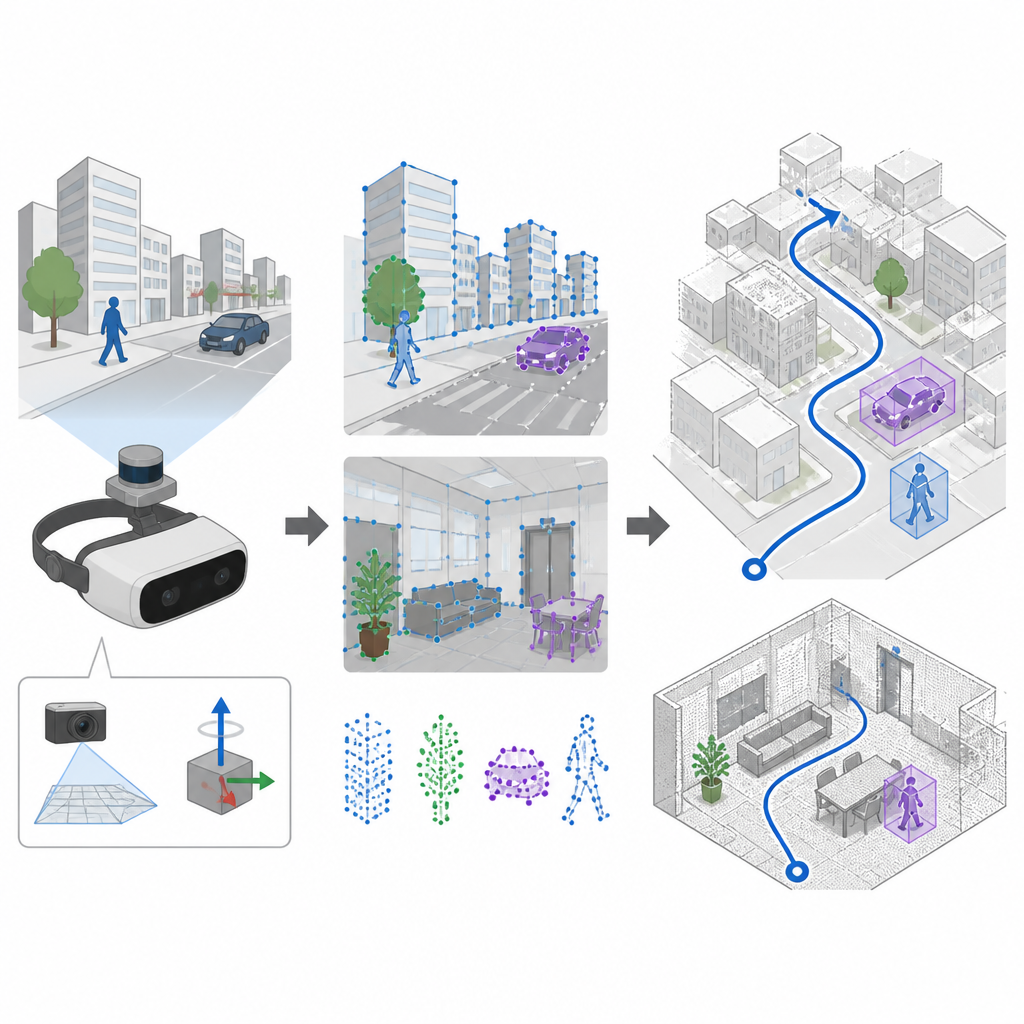
Vendo e sentindo o movimento juntos
Muitos sistemas de navegação dependem de câmeras e de uma técnica chamada SLAM para construir um mapa e seguir seu trajeto simultaneamente. Sistemas mais antigos selecionam pontos distintivos na imagem com regras feitas à mão, que funcionam bem em cenas calmas e bem iluminadas, mas frequentemente falham quando a câmera treme ou a iluminação muda rapidamente. O SuperDynaSLAM aprimora essa etapa inicial usando um detector de características aprendido chamado SuperPoint, treinado em muitas vistas de cenas reais para reconhecer âncoras visuais confiáveis mesmo quando a câmera se move violentamente ou a aparência muda bastante. O sistema também utiliza uma unidade de medição inercial a bordo, que mede como o dispositivo gira e acelera entre quadros de câmera.
Separando fundo de objetos em movimento
Um grande desafio para qualquer navegador baseado em visão é que nem tudo no campo de visão está fixo. Pessoas, carros e outros objetos em movimento criam pistas visuais enganosas. O SuperDynaSLAM enfrenta isso com um processo em duas etapas. Primeiro, aplica um programa de deep learning chamado Mask R-CNN a cada imagem para traçar contornos aproximados de objetos que podem se mover, como veículos e pedestres. Os pontos de interesse que o SuperPoint encontra são então agrupados em três tipos simples com base onde se situam: fundo, veículos e pedestres. A correspondência de pontos só é permitida dentro do mesmo tipo, o que já reduz confusões óbvias, como associar a esquina de um prédio a um carro em passagem.
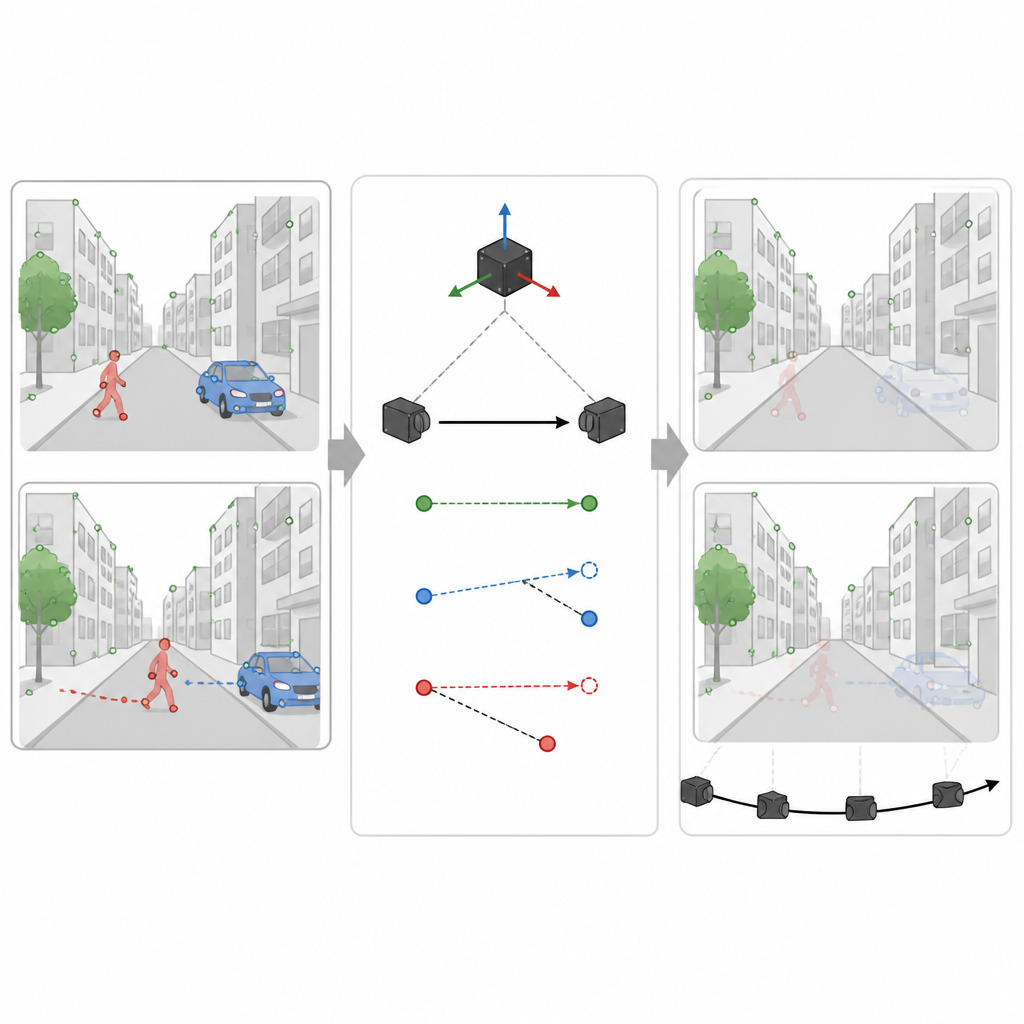
Usando pistas de movimento para detectar o que realmente está se movendo
No entanto, nem toda região com formato de carro ou pessoa está realmente em movimento em um dado momento. Um carro estacionado deve ajudar o mapa, não prejudicá-lo. Na segunda etapa, o SuperDynaSLAM usa as leituras do sensor de movimento para calcular como um ponto verdadeiramente fixo na cena deveria se deslocar entre duas imagens da câmera. Ele compara esse deslocamento esperado com o que a câmera realmente observa para alguns pontos de amostra em cada objeto potencialmente móvel. Se pontos em um objeto se afastam demais do caminho esperado, o sistema conclui que o objeto está se movendo e marca todos os seus pontos como não confiáveis. Se eles permanecem próximos, o objeto é tratado como parte da cena estável. Esse filtro seletivo permite ao sistema descartar informações enganosas enquanto preserva o maior número possível de detalhes úteis.
Testado em ruas virtuais, escritórios e mercados
Os pesquisadores testaram o SuperDynaSLAM em três conjuntos de dados exigentes. Um conjunto veio de voos reais em ambientes internos com movimento rápido e iluminação variável. Outro foi uma cidade e estacionamento simulados onde o nível de tráfego podia ser ajustado de ruas vazias a fluxo intenso. O terceiro foi um robô percorrendo escritórios reais, residências, mercados e cafés cheios de compradores em movimento e desordem. Na maioria desses testes, especialmente quando havia muitos objetos em movimento ou movimento brusco da câmera, o SuperDynaSLAM seguiu o trajeto verdadeiro mais de perto e com menos tremulação do que os sistemas líderes que dependem de features visuais mais antigas ou de apenas um tipo de pista.
O que isso significa para a navegação do dia a dia
Para um público leigo, a mensagem principal é que o SuperDynaSLAM ajuda as máquinas a focarem no que é sólido e confiável em uma cena e a ignorarem movimentos distrativos. Ao combinar features visuais aprendidas, consciência de objetos e sensoriamento de movimento, constrói mapas mais precisos e rastreia sua posição de forma mais estável, mesmo em ambientes lotados ou rapidamente mutáveis. Embora isso envolva um custo computacional maior e o sistema ainda possa deixar passar objetos móveis incomuns, a abordagem representa um passo prático rumo a uma navegação mais confiável para carros autônomos, robôs de entrega e dispositivos de realidade virtual ou mista imersiva.
Citação: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Palavras-chave: SLAM visual inercial, ambientes dinâmicos, extração de características, navegação de robôs, visão computacional