Clear Sky Science · ru
Улучшенный визуально-инерциальный SLAM с использованием SuperPoint и семантического геометрического обнаружения динамических признаков
Более умная навигация в движущемся мире
Роботам, дронам и гарнитурам дополненной реальности нужно точно знать своё положение, пока мир вокруг них меняется. Традиционные системы картографирования путаются из‑за проходящих людей или машин, что может привести к тому, что цифровые указатели соскользнут с дороги или робот неверно оценит маршрут. В этой работе представлен SuperDynaSLAM — метод навигации, разработанный для более надёжного отслеживания позиции в оживлённых, изменяющихся сценах с использованием современных инструментов искусственного интеллекта и датчиков движения.
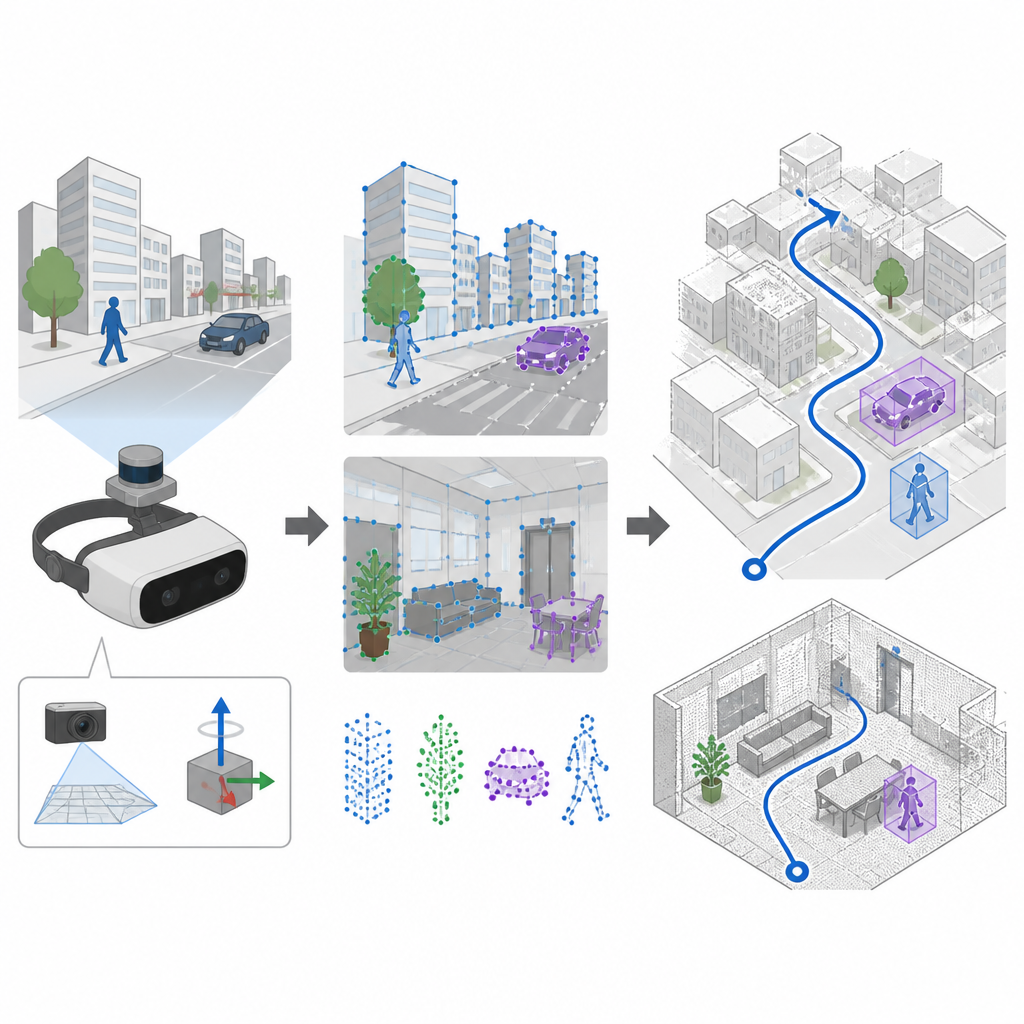
Видеть и ощущать движение вместе
Многие системы навигации опираются на камеры и метод SLAM, чтобы одновременно строить карту и определять своё положение. Старые подходы выбирали запоминающиеся точки в изображении по вручную заданным правилам — это хорошо работает в спокойных, хорошо освещённых сценах, но часто ломается при тряске камеры или резких изменениях освещения. SuperDynaSLAM улучшает этот фронтенд, применяя обученную модель поиска признаков SuperPoint, натренированную на многочисленных видах реальных сцен, чтобы узнавать надёжные визуальные опоры даже при сильных движениях камеры или значительных изменениях вида. Система также использует бортовой модуль инерциальных датчиков, который измеряет вращения и ускорения устройства между кадрами камеры.
Отделение фона от движущихся объектов
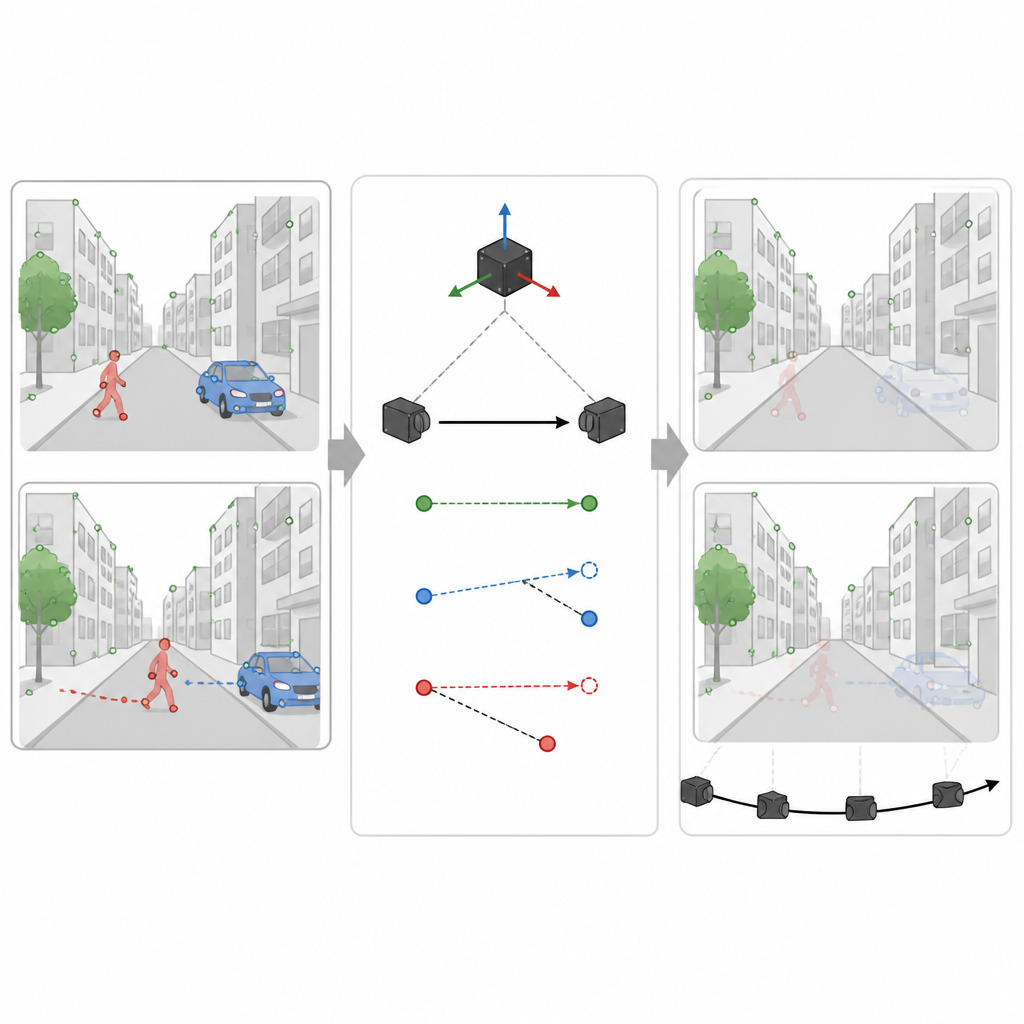
Главная сложность для любой системы, основанной на зрении, в том, что не всё в поле зрения фиксировано. Люди, автомобили и другие движущиеся объекты создают вводящие в заблуждение визуальные подсказки. SuperDynaSLAM решает эту проблему в два этапа. Сначала к каждому изображению применяют глубокую модель Mask R-CNN, которая предварительно обводит объекты, способные двигаться, такие как автомобили и пешеходы. Точки признаков, найденные SuperPoint, затем группируются по трём простым типам в зависимости от их расположения: фон, автомобили и пешеходы. Сопоставление точек разрешается лишь в пределах одного типа, что сразу уменьшает очевидные ошибки — например, связывание угла здания с проезжающей машиной.
Использование сигналов движения, чтобы заметить действительно движущееся
Однако не каждый участок, имеющий форму человека или машины, действительно движется в данный момент. Припаркованный автомобиль должен помогать карте, а не мешать ей. На втором этапе SuperDynaSLAM использует показания инерциальных датчиков, чтобы вычислить, как неподвижная точка сцены должна сместиться между двумя кадрами камеры. Полученное ожидаемое смещение сравнивают с тем, что фактически видит камера для нескольких образцовых точек на каждом потенциально подвижном объекте. Если точки на объекте отклоняются слишком далеко от ожидаемого пути, система делает вывод, что объект движется, и помечает все его точки как ненадёжные. Если они остаются близки к ожиданию, объект считается частью стабильной сцены. Такая селективная фильтрация позволяет отбросить вводящую в заблуждение информацию, сохранив при этом как можно больше полезных деталей.
Проверено в виртуальных улицах, офисах и на рынках
Исследователи протестировали SuperDynaSLAM на трёх требовательных наборах данных. Один набор получен из реальных полётов в помещениях с резкими движениями и меняющимся освещением. Другой — смоделированный город и парковка, где уровень трафика можно было изменять от пустых улиц до интенсивного потока. Третий — робот, который проезжал через реальные офисы, дома, рынки и кафе, заполненные движущимися покупателями и хаосом. В большинстве испытаний, особенно при большом количестве движущихся объектов или резких движениях камеры, SuperDynaSLAM точнее следовал истинному пути и допускал меньше дрожания по сравнению с передовыми системами, опирающимися на устаревшие визуальные признаки или только один тип сигналов.
Что это значит для повседневной навигации
Для непрофессионала главный вывод таков: SuperDynaSLAM помогает машинам сосредоточиться на том, что в сцене надёжно и устойчиво, и отфильтровать отвлекающее движение. Сочетая обученные визуальные признаки, осознание объектов и датчики движения, система строит более точные карты и стабильнее отслеживает положение даже в людных или быстро меняющихся средах. Хотя это требует больших вычислительных ресурсов и система по‑прежнему может пропустить необычные движущиеся объекты, подход представляет собой практический шаг к более надёжной навигации для беспилотных автомобилей, доставочных роботов и иммерсивных виртуальных или смешанных реальностей.
Цитирование: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Ключевые слова: визуально-инерциальный SLAM, динамичные среды, извлечение признаков, навигация робота, компьютерное зрение