Clear Sky Science · pl
Ulepszony wizualno-inercyjny SLAM z wykorzystaniem SuperPoint i semantyczno‑geometrycznego wykrywania cech dynamicznych
Mądrzejsza nawigacja w świecie w ruchu
Roboty, drony i zestawy rozszerzonej rzeczywistości muszą dokładnie wiedzieć, gdzie się znajdują, podczas gdy otaczający je świat cały czas się zmienia. Tradycyjne systemy mapujące mogą być zdezorientowane przez przechodzących ludzi czy mijające samochody, co może powodować, że cyfrowe wskazówki zboczają z trasy lub robot błędnie oceni drogę. W tym badaniu przedstawiono SuperDynaSLAM — metodę nawigacji zaprojektowaną tak, by bardziej niezawodnie śledzić pozycję w zatłoczonych, zmieniających się scenach, wykorzystując nowoczesne narzędzia sztucznej inteligencji i czujniki ruchu.
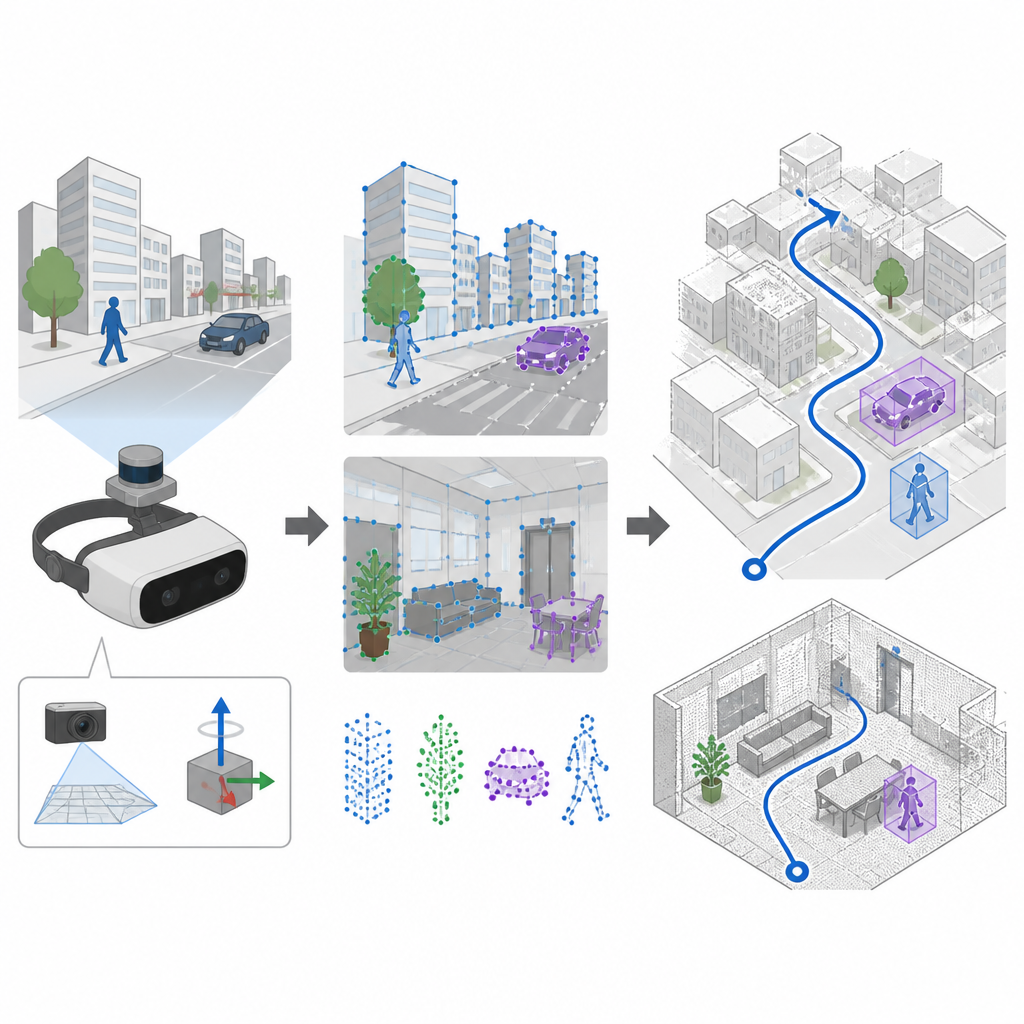
Wspólne widzenie i wykrywanie ruchu
Wiele systemów nawigacyjnych polega na kamerach i technice zwanej SLAM do jednoczesnego budowania mapy i śledzenia pozycji. Starsze systemy wybierają charakterystyczne punkty obrazu za pomocą ręcznie zaprojektowanych reguł, które sprawdzają się w spokojnych, dobrze oświetlonych scenach, lecz często zawodzą przy silnych drganiach kamery lub gwałtownych zmianach oświetlenia. SuperDynaSLAM upraszcza tę warstwę wejściową, wykorzystując uczony detektor cech o nazwie SuperPoint, wytrenowany na wielu widokach rzeczywistych scen, dzięki czemu potrafi rozpoznawać niezawodne kotwice wizualne nawet przy gwałtownym ruchu kamery lub dużych zmianach perspektywy. System korzysta również z pokładowego modułu inercyjnego, który mierzy, jak urządzenie się obraca i przyspiesza między klatkami kamery.
Oddzielanie tła od poruszających się obiektów
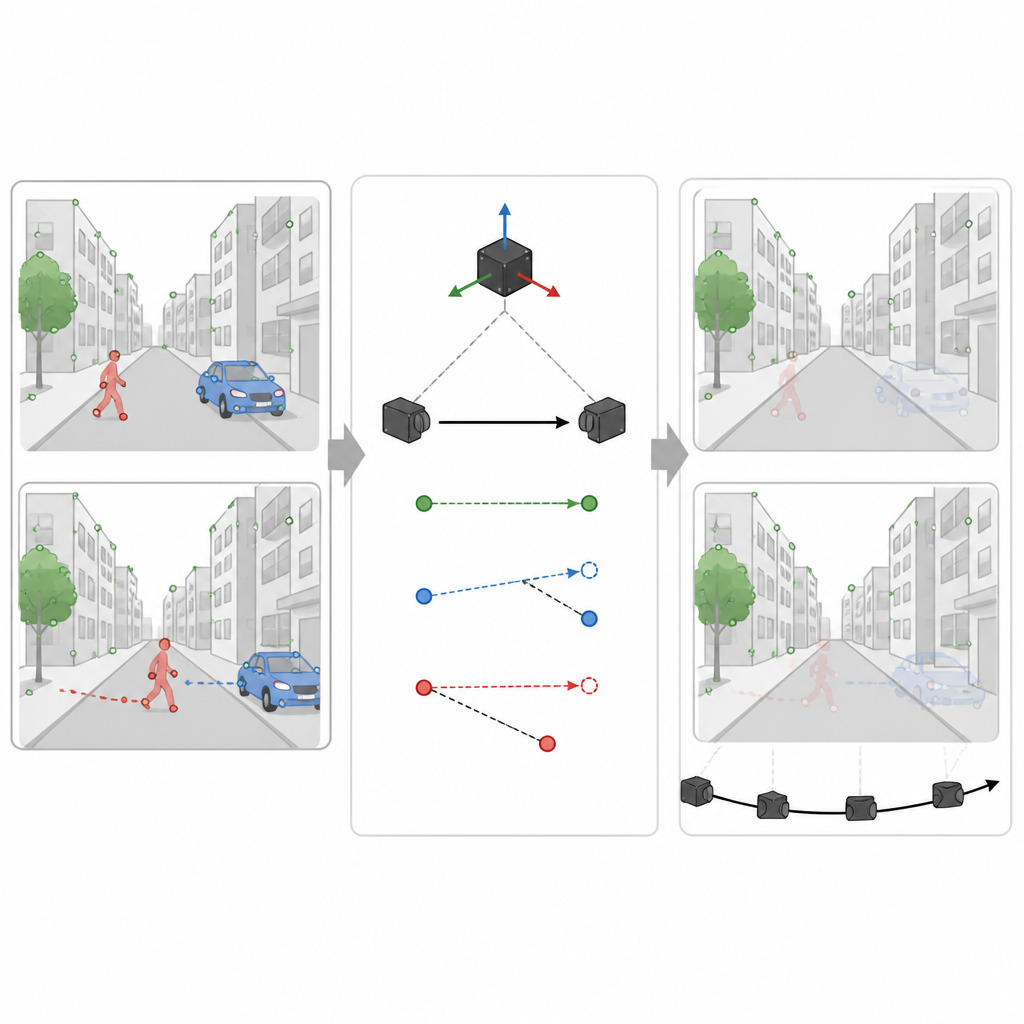
Głównym wyzwaniem dla każdego nawigatora opartego na widzeniu jest to, że nie wszystko w polu widzenia jest nieruchome. Ludzie, samochody i inne poruszające się obiekty generują mylące wskazówki wizualne. SuperDynaSLAM rozwiązuje to dwuetapowym procesem. Najpierw do każdego obrazu stosuje program uczenia głębokiego o nazwie Mask R-CNN, aby wyznaczyć przybliżone kontury obiektów, które mogą się poruszać, takich jak pojazdy i piesi. Punkty cech wykryte przez SuperPoint są następnie grupowane w trzy proste typy w zależności od tego, gdzie się znajdują: tło, pojazdy i piesi. Dopasowywanie punktów jest dozwolone tylko w obrębie tego samego typu, co już redukuje oczywiste pomyłki, na przykład dopasowanie narożnika budynku do przejeżdżającego samochodu.
Wykorzystanie wskazówek ruchu do rozpoznania rzeczywiście poruszających się obiektów
Jednak nie każdy obszar o kształcie samochodu czy osoby faktycznie się porusza w danym momencie. Zaparkowany samochód powinien pomagać w mapie, a nie jej szkodzić. W drugim etapie SuperDynaSLAM używa odczytów czujnika ruchu, aby określić, jak punkt naprawdę nieruchomy w scenie powinien przesunąć się między dwiema klatkami kamery. Porównuje to oczekiwane przesunięcie z tym, co kamera faktycznie widzi dla kilku przykładowych punktów na każdym obiekcie potencjalnie ruchomym. Jeśli punkty na obiekcie odbiegają zbyt daleko od oczekiwanej trajektorii, system wnioskuje, że obiekt się porusza i oznacza wszystkie jego punkty jako niewiarygodne. Jeśli pozostają blisko, obiekt traktowany jest jako część stabilnej sceny. To selektywne filtrowanie pozwala systemowi odrzucić mylące informacje, jednocześnie zachowując jak najwięcej przydatnych szczegółów.
Testy na wirtualnych ulicach, w biurach i na targach
Badacze przetestowali SuperDynaSLAM na trzech wymagających zbiorach danych. Jeden zestaw pochodził z rzeczywistych lotów wewnątrz pomieszczeń przy szybkim ruchu i zmieniającym się świetle. Inny to symulowane miasto i parking, gdzie poziom ruchu można było zwiększać od pustych ulic do intensywnego natężenia. Trzeci obejmował robota przemierzającego prawdziwe biura, domy, targi i kawiarnie pełne poruszających się klientów i zagracenia. W większości tych testów, szczególnie gdy występowało wiele poruszających się obiektów lub gwałtowne ruchy kamery, SuperDynaSLAM dokładniej śledził rzeczywistą trasę i z mniejszymi drganiami niż czołowe systemy opierające się na starszych cechach wizualnych lub tylko jednym rodzaju wskazówek.
Co to oznacza dla codziennej nawigacji
Dla przeciętnego odbiorcy kluczowa wiadomość jest taka, że SuperDynaSLAM pomaga maszynom skupić się na elementach sceny, które są stałe i wiarygodne, i odfiltrować rozpraszający ruch. Poprzez łączenie uczonych cech wizualnych, świadomości obiektów i pomiarów ruchu, buduje dokładniejsze mapy i stabilniej śledzi swoją pozycję, nawet w zatłoczonych lub szybko zmieniających się środowiskach. Chociaż wiąże się to z większym kosztem obliczeniowym i system wciąż może przeoczyć nietypowe poruszające się obiekty, podejście to stanowi praktyczny krok w kierunku bardziej niezawodnej nawigacji dla samochodów autonomicznych, robotów dostawczych oraz immersyjnych urządzeń wirtualnej lub mieszanej rzeczywistości.
Cytowanie: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Słowa kluczowe: wizualno-inercyjny SLAM, środowiska dynamiczne, ekstrakcja cech, nawigacja robotów, widzenie komputerowe