Clear Sky Science · de
Verbessertes visuell-inertiales SLAM mit SuperPoint und semantisch-geometrischer Erkennung dynamischer Merkmale
Intelligenter navigieren in einer bewegten Welt
Roboter, Drohnen und Augmented-Reality-Headsets müssen genau wissen, wo sie sich befinden, während sich die Welt um sie herum weiterbewegt. Traditionelle Kartierungssysteme können durch vorbeigehende Personen oder fahrende Autos irritiert werden, was dazu führen kann, dass digitale Pfeile von der Straße abdriften oder ein Roboter seinen Weg falsch einschätzt. Diese Studie stellt SuperDynaSLAM vor, eine Navigationsmethode, die entwickelt wurde, um die Positionsbestimmung in belebten, sich verändernden Szenen zuverlässiger zu machen, indem moderne Werkzeuge der künstlichen Intelligenz und Bewegungssensoren genutzt werden.
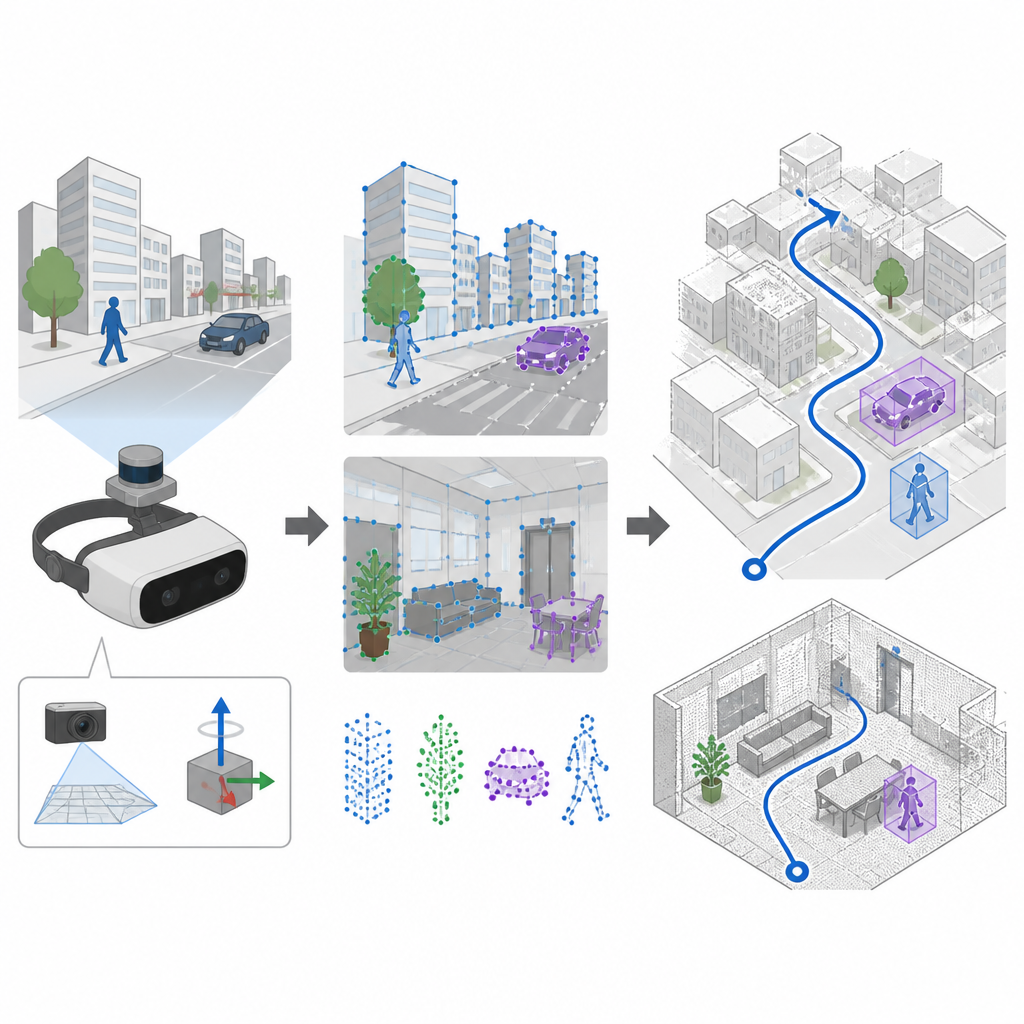
Sehen und Bewegungen fühlen zusammen
Viele Navigationssysteme verlassen sich auf Kameras und eine Technik namens SLAM, um gleichzeitig eine Karte zu erstellen und die Position zu verfolgen. Ältere Systeme wählen markante Stellen im Bild mit handgefertigten Regeln aus, die in ruhigen, gut beleuchteten Szenen gut funktionieren, aber oft versagen, wenn die Kamera wackelt oder sich die Beleuchtung schnell ändert. SuperDynaSLAM verbessert diese Front-End-Stufe, indem es einen gelernten Merkmal-Detektor namens SuperPoint einsetzt, der an vielen Ansichten realer Szenen trainiert wurde und so verlässliche visuelle Anker erkennt, selbst wenn die Kamera stark bewegt wird oder sich die Ansicht stark verändert. Das System nutzt außerdem eine an Bord befindliche Trägheitseinheit, die misst, wie sich das Gerät zwischen Kamerabildern dreht und beschleunigt.
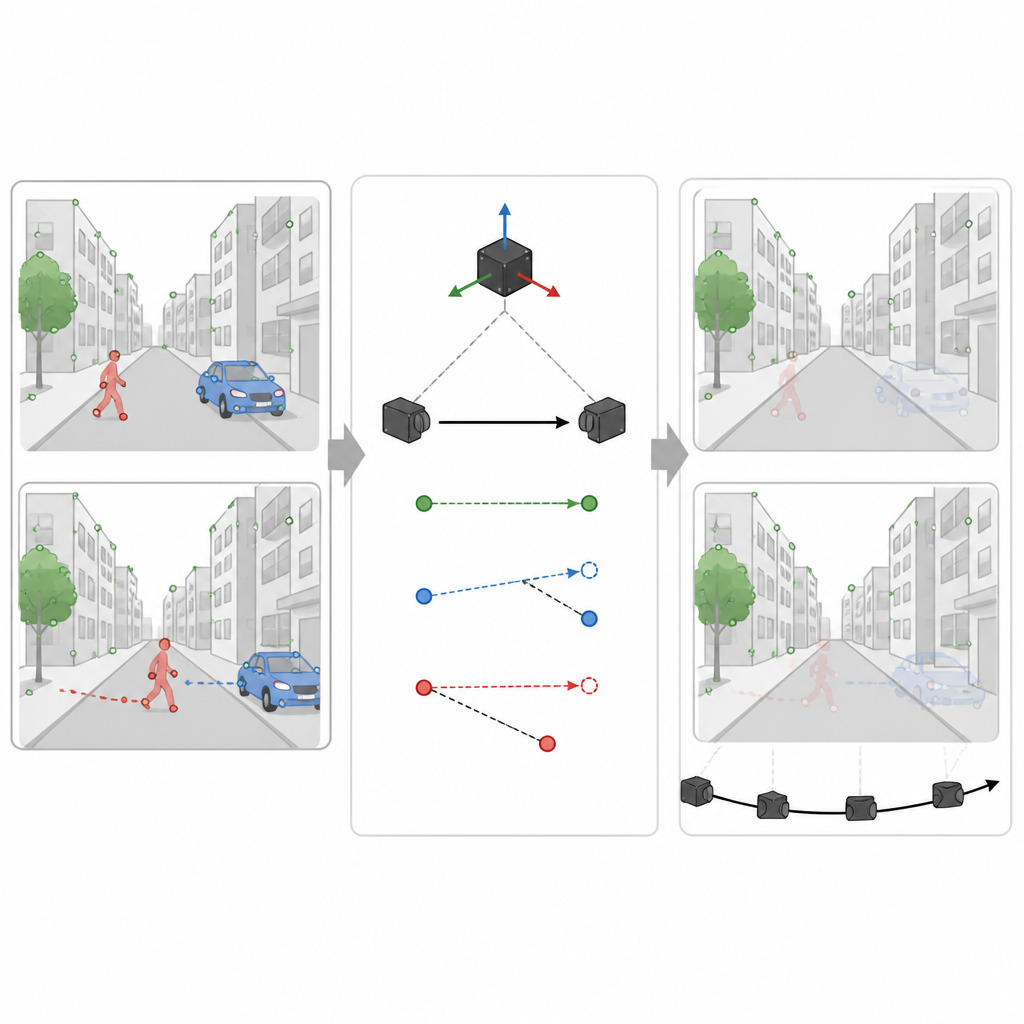
Hintergrund von bewegten Objekten trennen
Eine große Herausforderung für jeden visuell basierten Navigator ist, dass nicht alles im Sichtfeld fest an seinem Platz ist. Personen, Autos und andere bewegte Objekte erzeugen irreführende visuelle Hinweise. SuperDynaSLAM geht dieses Problem mit einem zweistufigen Verfahren an. Zuerst wendet es ein tiefes Lernmodell namens Mask R-CNN auf jedes Bild an, um grobe Umrisse um potenziell bewegliche Objekte wie Fahrzeuge und Fußgänger zu zeichnen. Die von SuperPoint gefundenen Merkmale werden dann in drei einfache Typen gruppiert, je nachdem, wo sie liegen: Hintergrund, Fahrzeuge und Fußgänger. Übereinstimmungen von Punkten sind nur innerhalb desselben Typs erlaubt, was offensichtliche Verwechslungen reduziert, etwa wenn eine Gebäudeecke mit einem vorbeifahrenden Auto abgeglichen würde.
Bewegungshinweise nutzen, um wirklich Bewegtes zu erkennen
Allerdings ist nicht jede auto- oder menschenförmige Region zu einem gegebenen Zeitpunkt tatsächlich in Bewegung. Ein geparktes Auto sollte der Karte helfen, nicht schaden. In der zweiten Stufe verwendet SuperDynaSLAM die Messungen des Bewegungssensors, um zu berechnen, wie sich ein tatsächlich fester Punkt in der Szene zwischen zwei Kamerabildern verschieben müsste. Es vergleicht diese erwartete Verschiebung mit dem, was die Kamera für einige Stichprobenpunkte auf jedem potenziell beweglichen Objekt tatsächlich sieht. Wenn Punkte eines Objekts zu weit von der erwarteten Bahn abweichen, kommt das System zu dem Schluss, dass das Objekt sich bewegt, und markiert alle seine Punkte als unzuverlässig. Bleiben sie nahe beieinander, wird das Objekt als Teil der stabilen Szene behandelt. Dieses selektive Filtern ermöglicht es dem System, irreführende Informationen zu verwerfen und gleichzeitig so viele nützliche Details wie möglich zu behalten.
Getestet in virtuellen Straßen, Büros und Märkten
Die Forschenden testeten SuperDynaSLAM an drei anspruchsvollen Datensätzen. Ein Satz stammt aus realen Innenraumflügen mit schnellen Bewegungen und wechselnder Beleuchtung. Ein weiterer war eine simulierte Stadt und ein Parkplatz, bei dem das Verkehrsaufkommen von leeren Straßen bis zu starkem Verkehr variiert werden konnte. Der dritte bestand aus einem Roboter, der durch reale Büros, Wohnungen, Märkte und Cafés fuhr, gefüllt mit bewegten Einkäufern und Unordnung. In den meisten dieser Versuche—insbesondere wenn viele bewegte Objekte oder starke Kamerabewegungen vorhanden waren—folgte SuperDynaSLAM dem tatsächlichen Pfad näher und mit weniger Zittern als führende Systeme, die auf älteren visuellen Merkmalen oder nur einer Art von Hinweis basieren.
Was das für die alltägliche Navigation bedeutet
Für Laien lautet die Kernbotschaft: SuperDynaSLAM hilft Maschinen, sich auf das zu konzentrieren, was in einer Szene solide und verlässlich ist, und ablenkende Bewegungen auszublenden. Durch die Kombination gelernter visueller Merkmale, Objektbewusstheit und Bewegungssensorik erstellt es genauere Karten und verfolgt seine Position stabiler, selbst in überfüllten oder sich schnell verändernden Umgebungen. Zwar geht das mit höheren Rechenkosten einher und das System kann ungewöhnliche bewegte Objekte übersehen, doch stellt dieser Ansatz einen praktischen Schritt zu zuverlässigerer Navigation für fahrerlose Autos, Lieferroboter und immersive virtuelle oder Mixed-Reality-Geräte dar.
Zitation: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Schlüsselwörter: visuell-inertiales SLAM, dynamische Umgebungen, Merkmalextraktion, Roboter-Navigation, Computer Vision