Clear Sky Science · es
SLAM visual-inercial mejorado usando SuperPoint y detección semántico-geométrica de características dinámicas
Navegación más inteligente en un mundo en movimiento
Los robots, drones y cascos de realidad aumentada necesitan saber con precisión dónde están mientras el entorno sigue cambiando. Los sistemas de mapeo tradicionales pueden confundirse con personas que caminan o coches que pasan, lo que puede provocar que flechas digitales se desvíen de la carretera o que un robot calcule mal su trayectoria. Este estudio presenta SuperDynaSLAM, un método de navegación diseñado para mantener un seguimiento de la posición más fiable en escenas concurridas y cambiantes, usando herramientas modernas de inteligencia artificial y sensores de movimiento.
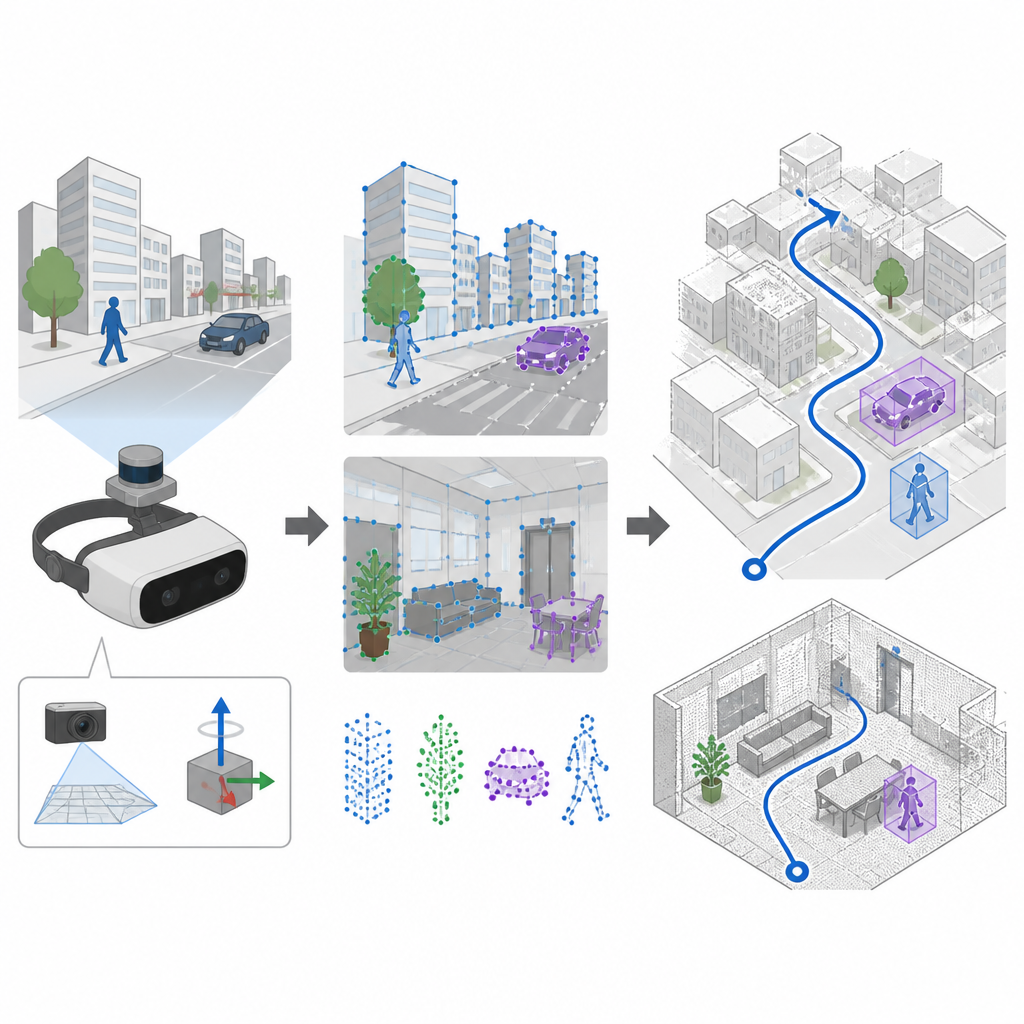
Ver y sentir el movimiento juntos
Muchos sistemas de navegación se apoyan en cámaras y en una técnica llamada SLAM para construir un mapa y seguir la trayectoria al mismo tiempo. Los sistemas más antiguos seleccionan puntos distintivos en la imagen mediante reglas hechas a mano, que funcionan bien en escenas tranquilas y bien iluminadas pero a menudo fallan cuando la cámara tiembla o la iluminación cambia rápidamente. SuperDynaSLAM mejora este front-end usando un detector de características aprendido llamado SuperPoint, que se ha entrenado con muchas vistas de escenas reales para reconocer anclas visuales fiables incluso cuando la cámara se mueve de forma violenta o la vista varía mucho. El sistema también aprovecha una unidad de sensores de movimiento a bordo, que mide cómo rota y acelera el dispositivo entre fotogramas de la cámara.
Separar el fondo de los objetos en movimiento
Un desafío importante para cualquier navegador basado en visión es que no todo lo que aparece en la imagen está fijo. Personas, coches y otros objetos en movimiento generan señales visuales engañosas. SuperDynaSLAM afronta esto con un proceso en dos etapas. Primero, aplica un programa de aprendizaje profundo llamado Mask R-CNN a cada imagen para dibujar contornos aproximados alrededor de objetos que pueden moverse, como vehículos y peatones. Los puntos de interés que encuentra SuperPoint se agrupan luego en tres tipos sencillos según dónde caen: fondo, vehículos y peatones. Solo se permiten coincidencias de puntos dentro del mismo tipo, lo que ya reduce errores evidentes, como emparejar la esquina de un edificio con un coche que pasa.
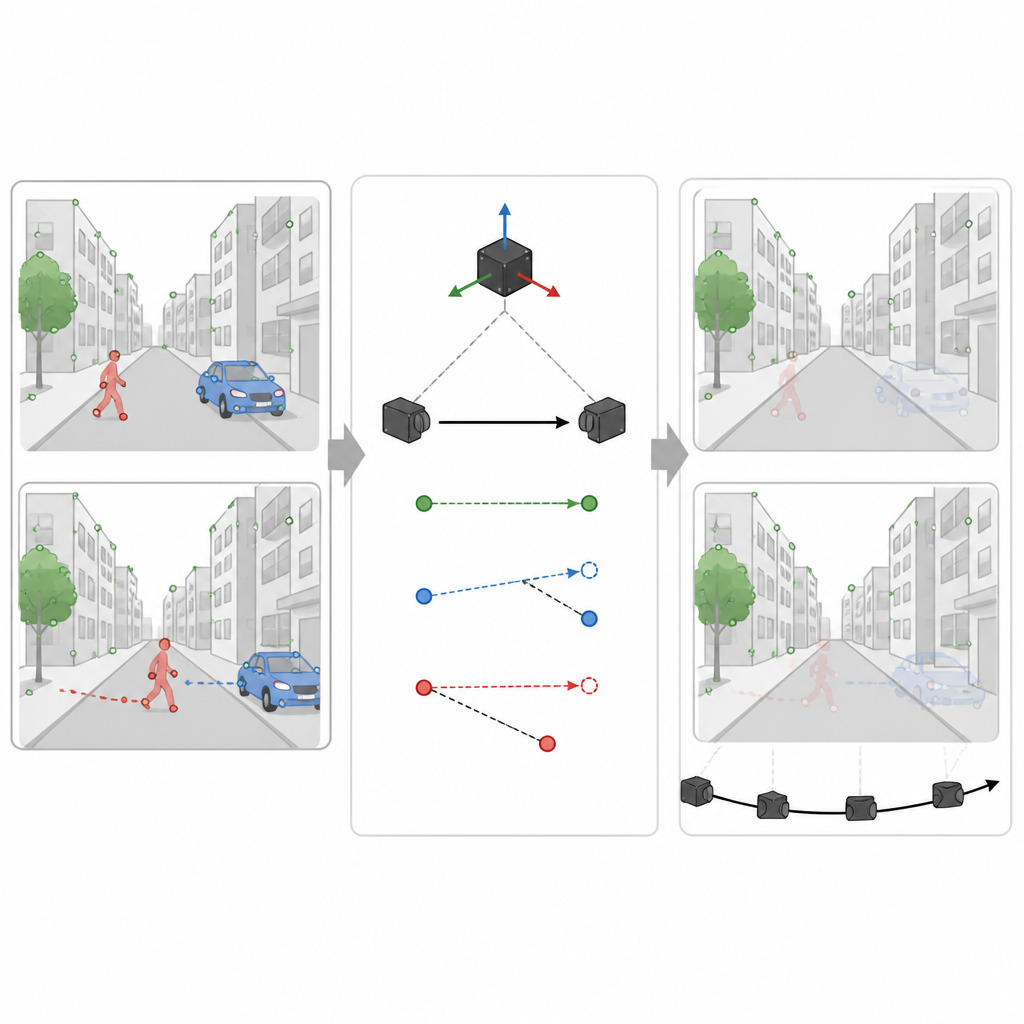
Usar pistas de movimiento para detectar lo que realmente se mueve
Sin embargo, no toda región con forma de coche o persona se está moviendo en un momento dado. Un coche aparcado debe ayudar al mapa, no perjudicarlo. En la segunda etapa, SuperDynaSLAM utiliza las lecturas del sensor de movimiento para calcular cómo debería desplazarse un punto realmente fijo de la escena entre dos imágenes de la cámara. Compara este desplazamiento esperado con lo que la cámara muestra realmente para algunos puntos de muestra en cada objeto que podría moverse. Si los puntos de un objeto se desvían demasiado de la trayectoria esperada, el sistema concluye que el objeto está en movimiento y marca todos sus puntos como poco fiables. Si permanecen cercanos, el objeto se trata como parte de la escena estable. Este filtrado selectivo permite al sistema desechar información engañosa mientras conserva la mayor cantidad posible de detalles útiles.
Probado en calles virtuales, oficinas y mercados
Los investigadores probaron SuperDynaSLAM en tres conjuntos exigentes de datos. Uno procedía de vuelos reales en interiores con movimientos rápidos y luz cambiante. Otro era una ciudad y un aparcamiento simulados donde el nivel de tráfico podía ajustarse desde calles vacías hasta flujo intenso. El tercero fue un robot que recorría oficinas reales, viviendas, mercados y cafeterías llenas de compradores en movimiento y desorden. En la mayoría de estas pruebas, especialmente cuando había muchos objetos móviles o movimientos bruscos de la cámara, SuperDynaSLAM siguió la trayectoria real más de cerca y con menos oscilación que los sistemas punteros que se basan en características visuales más antiguas o en un único tipo de señal.
Qué implica esto para la navegación diaria
Para un público general, el mensaje clave es que SuperDynaSLAM ayuda a las máquinas a centrarse en lo sólido y fiable de una escena y a ignorar el movimiento distrayente. Al combinar características visuales aprendidas, conciencia de objetos y detección de movimiento, construye mapas más precisos y rastrea su posición con mayor estabilidad, incluso en entornos concurridos o de cambios rápidos. Aunque esto conlleva un mayor coste computacional y el sistema aún puede pasar por alto objetos móviles inusuales, el enfoque representa un paso práctico hacia una navegación más fiable para coches autónomos, robots de reparto y dispositivos de realidad virtual o mixta inmersivos.
Cita: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Palabras clave: SLAM visual inercial, entornos dinámicos, extracción de características, navegación robótica, visión por computador