Clear Sky Science · ja
SuperPointとセマンティック幾何学的動的特徴検出を用いた視覚・慣性融合SLAMの強化
動く世界でのより賢いナビゲーション
ロボット、ドローン、拡張現実ヘッドセットは、周囲が常に動いている状況でも自分の正確な位置を把握する必要があります。従来のマッピングシステムは、歩行者や通過する車に惑わされやすく、その結果、デジタルの矢印が道路から外れたりロボットが経路を誤判断したりすることがあります。本研究は、最新の人工知能ツールとモーションセンサーを活用して、混雑し変化するシーンでより安定して位置を追跡するためのナビゲーション手法、SuperDynaSLAMを紹介します。
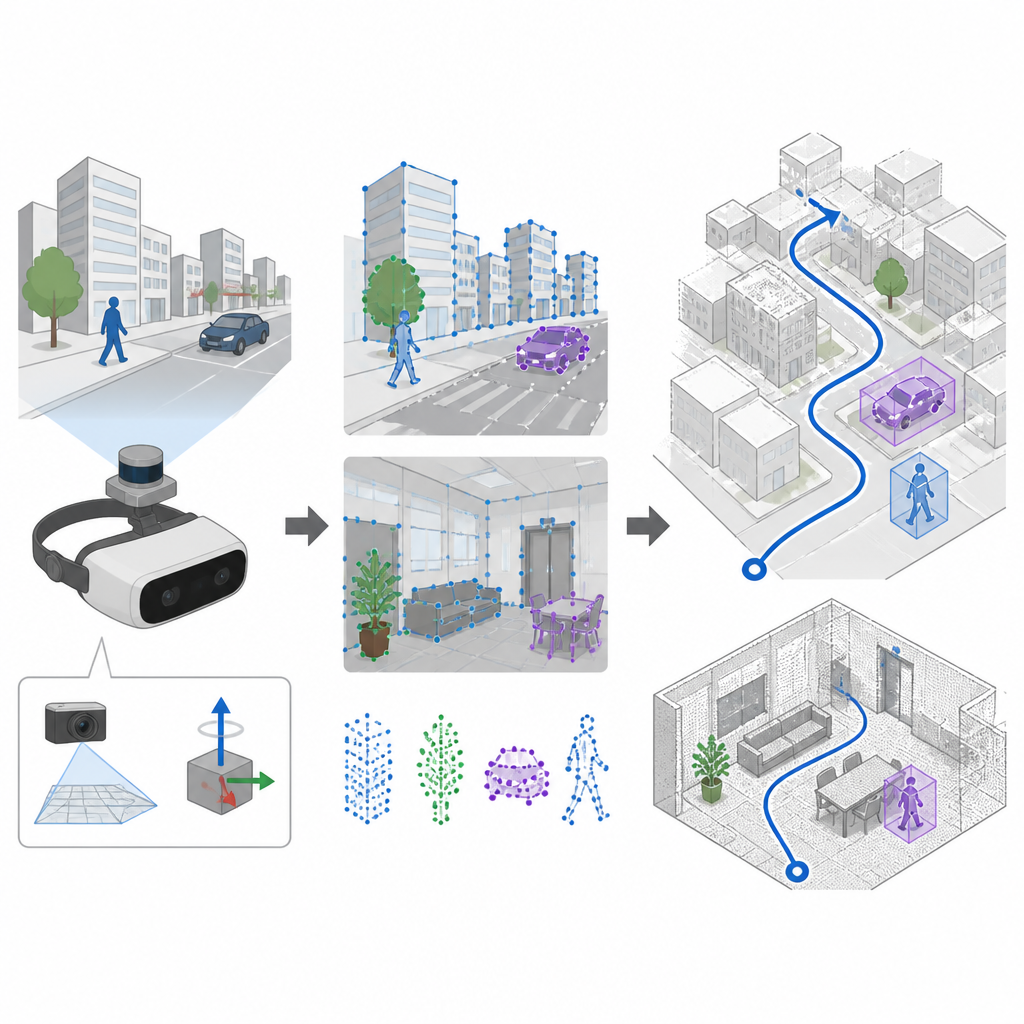
視覚と慣性で動きを同時にとらえる
多くのナビゲーションシステムはカメラとSLAMという手法に依存して、地図構築と同時に自己位置推定を行います。従来のシステムは手作りの規則で画像中の特徴的な点を選び出しますが、それは静かで十分に照明されたシーンではうまく機能する一方、カメラが激しく振動したり照明が急変したりすると失敗しがちです。SuperDynaSLAMは、学習された特徴検出器であるSuperPointを用いることでこの前処理を強化します。SuperPointは多様な実世界シーンで学習されており、カメラの激しい動きや大きな視点変化があっても信頼できる視覚的アンカーを認識できます。さらにシステムは、フレーム間の回転や加速度を測る搭載型慣性計測装置(IMU)のデータも利用します。
背景と動く物体の分離
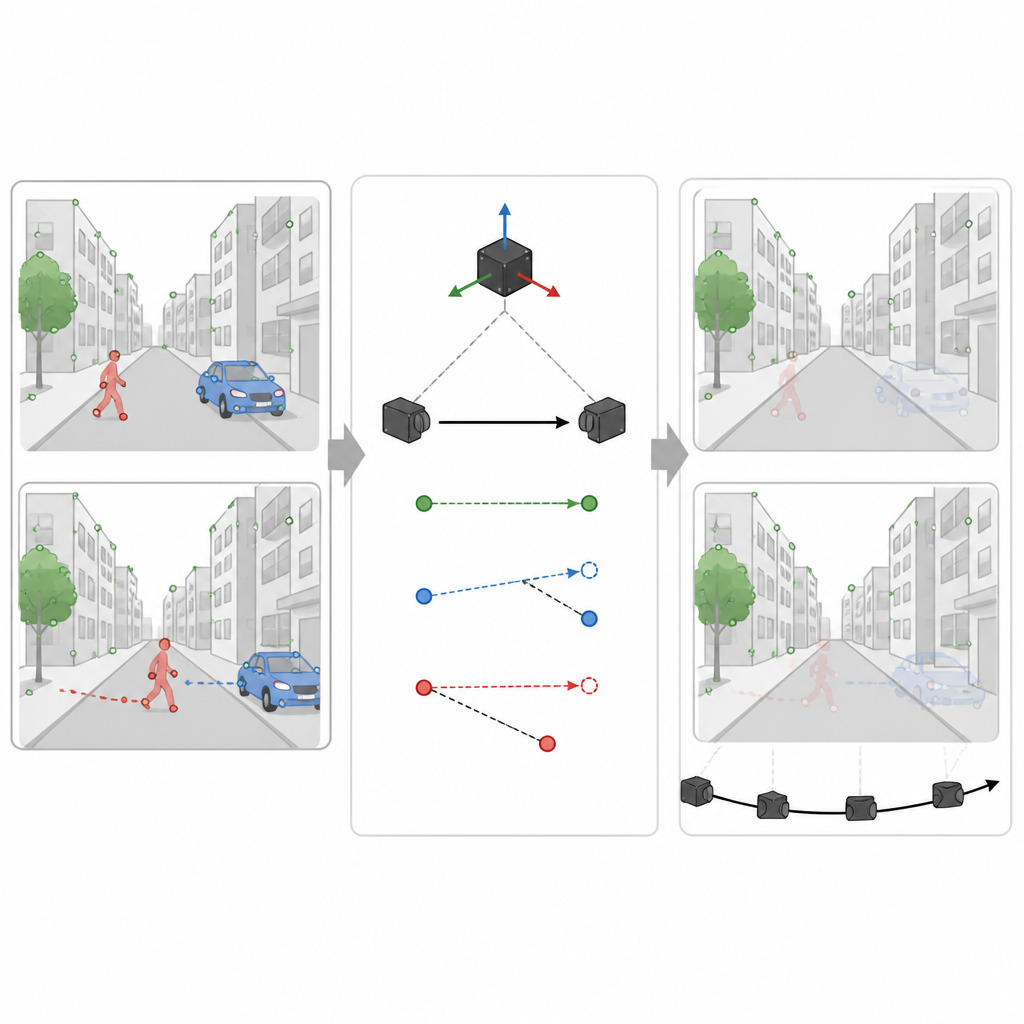
視覚ベースのナビゲータにとって大きな課題は、画面内のすべてが固定されているわけではないことです。人や車などの動く物体は誤誘導する視覚手がかりを生みます。SuperDynaSLAMは二段階のプロセスでこれに対処します。まず各画像に対してMask R-CNNという深層学習モデルを適用し、車両や歩行者など動き得る物体の大まかな輪郭を描きます。次にSuperPointが検出した特徴点を、背景、車両、歩行者の三つの単純なカテゴリに分類します。同一カテゴリ内でのみ点の対応付けを許可することで、建物の角を通り過ぎる車と誤って対応づけるといった明らかな混同を減らします。
本当に動いているものを動きの手がかりで見分ける
しかし、すべての車や人のような領域が常に動いているわけではありません。駐車中の車は地図構築に役立つはずで、妨げになるべきではありません。第二段階では、SuperDynaSLAMは慣性センサーの読み取り値を用いて、真に固定された点が2つのカメラ画像間でどのように移動するはずかを推定します。次に、動き得る各物体上のいくつかのサンプル点について、その期待される移動と実際のカメラ観測を比較します。もし物体上の点が期待される経路から大きく外れるなら、その物体は動いていると判断してその物体に属するすべての点を信用できないものとしてマークします。逆に近くにとどまるなら、その物体は安定したシーンの一部として扱われます。この選択的フィルタリングにより、誤誘導する情報を捨てつつ、有用な詳細はできるだけ残すことができます。
仮想の通りやオフィス、市場での検証
研究者たちは、三つの負荷の高いデータセットでSuperDynaSLAMを検証しました。ひとつは急激な動きと変化する照明を伴う実際の屋内飛行のデータです。もうひとつは、交通量を空の通りから激しい流れまで調整できるシミュレーションの都市と駐車場です。三つ目は、動く買い物客や雑多な物にあふれた実際のオフィス、住宅、マーケット、カフェをロボットが走行した記録です。これらの試験の多く、特に多くの動く物体や急激なカメラ動作がある場面では、SuperDynaSLAMは従来の視覚特徴や単一手がかりに依存する先行手法よりも真の軌跡により近く、振幅も小さく追跡しました。
日常的なナビゲーションにとっての意義
一般向けの要点は、SuperDynaSLAMがシーン内の堅実で頼れる要素に機械の注目を向け、気を散らす動きを除外するのに役立つということです。学習された視覚特徴、物体認識、動き検出を組み合わせることで、より正確な地図を構築し、混雑したあるいは急速に変化する環境でも位置をより安定して追跡します。計算コストが高くなる点や珍しい動く物体を見逃す可能性が依然あるものの、このアプローチは自動運転車、配送ロボット、没入型の仮想・複合現実機器向けの、より信頼性の高いナビゲーションに向けた実践的な前進を示しています。
引用: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
キーワード: 視覚・慣性SLAM, 動的環境, 特徴抽出, ロボットナビゲーション, コンピュータビジョン