Clear Sky Science · en
Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection
Smarter navigation in a moving world
Robots, drones, and augmented reality headsets need to know exactly where they are while the world around them keeps moving. Traditional mapping systems can get confused by walking people or passing cars, which may cause digital arrows to drift off the road or a robot to misjudge its path. This study introduces SuperDynaSLAM, a navigation method designed to keep track of position more reliably in busy, changing scenes, using modern artificial intelligence tools and motion sensors.
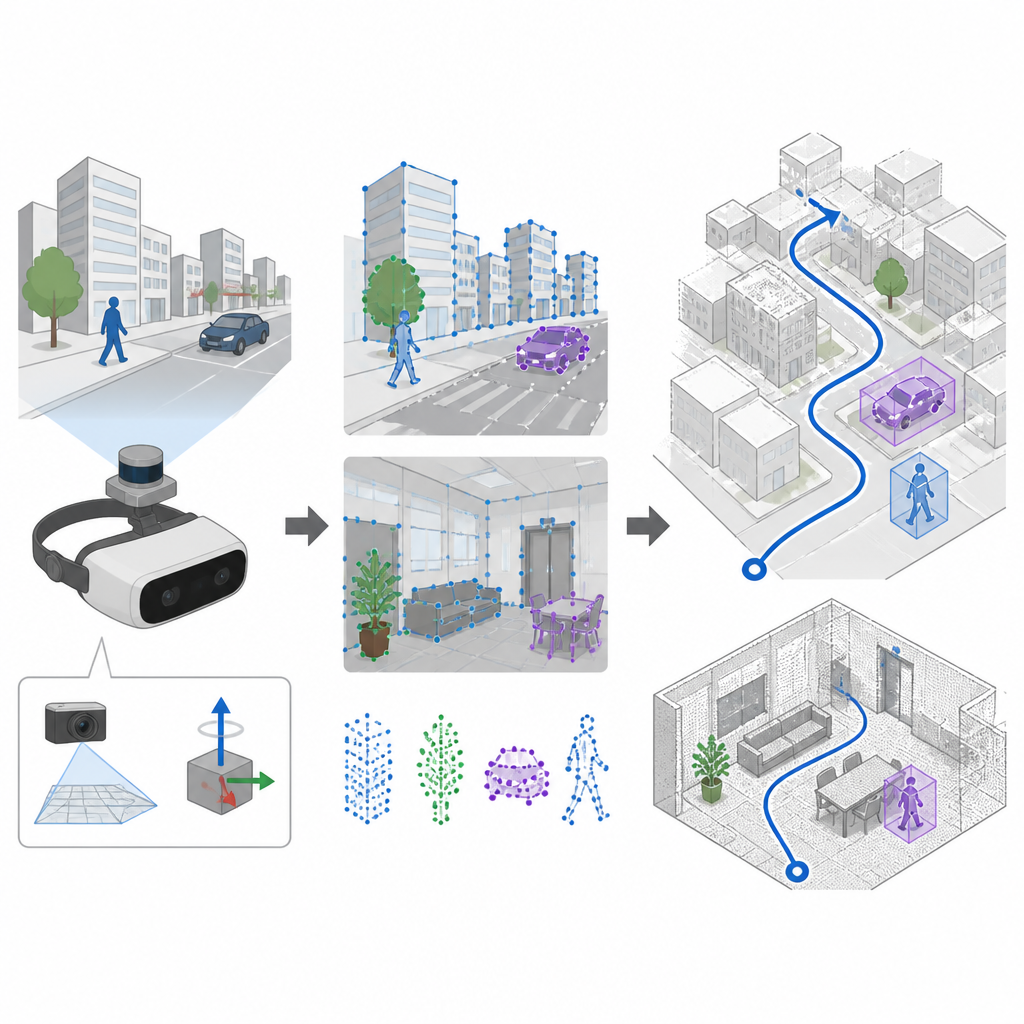
Seeing and feeling motion together
Many navigation systems rely on cameras and a technique called SLAM to build a map and follow their path at the same time. Older systems pick distinctive spots in the image with hand-crafted rules, which work well in calm, well lit scenes but often fail when the camera shakes or the lighting changes quickly. SuperDynaSLAM upgrades this front end by using a learned feature finder called SuperPoint, which has been trained on many views of real scenes so it can recognize reliable visual anchors even when the camera moves violently or the view changes a lot. The system also makes use of an onboard motion sensor unit, which measures how the device rotates and accelerates between camera frames.
Separating background from moving objects
A major challenge for any vision based navigator is that not everything in view is fixed in place. People, cars, and other moving objects create misleading visual cues. SuperDynaSLAM tackles this with a two stage process. First, it applies a deep learning program called Mask R-CNN to each image to draw rough outlines around objects that can move, such as vehicles and pedestrians. The feature points that SuperPoint finds are then grouped into three simple types based on where they fall: background, vehicles, and pedestrians. Matching points is only allowed within the same type, which already reduces obvious mix ups, like matching a building corner to a passing car.
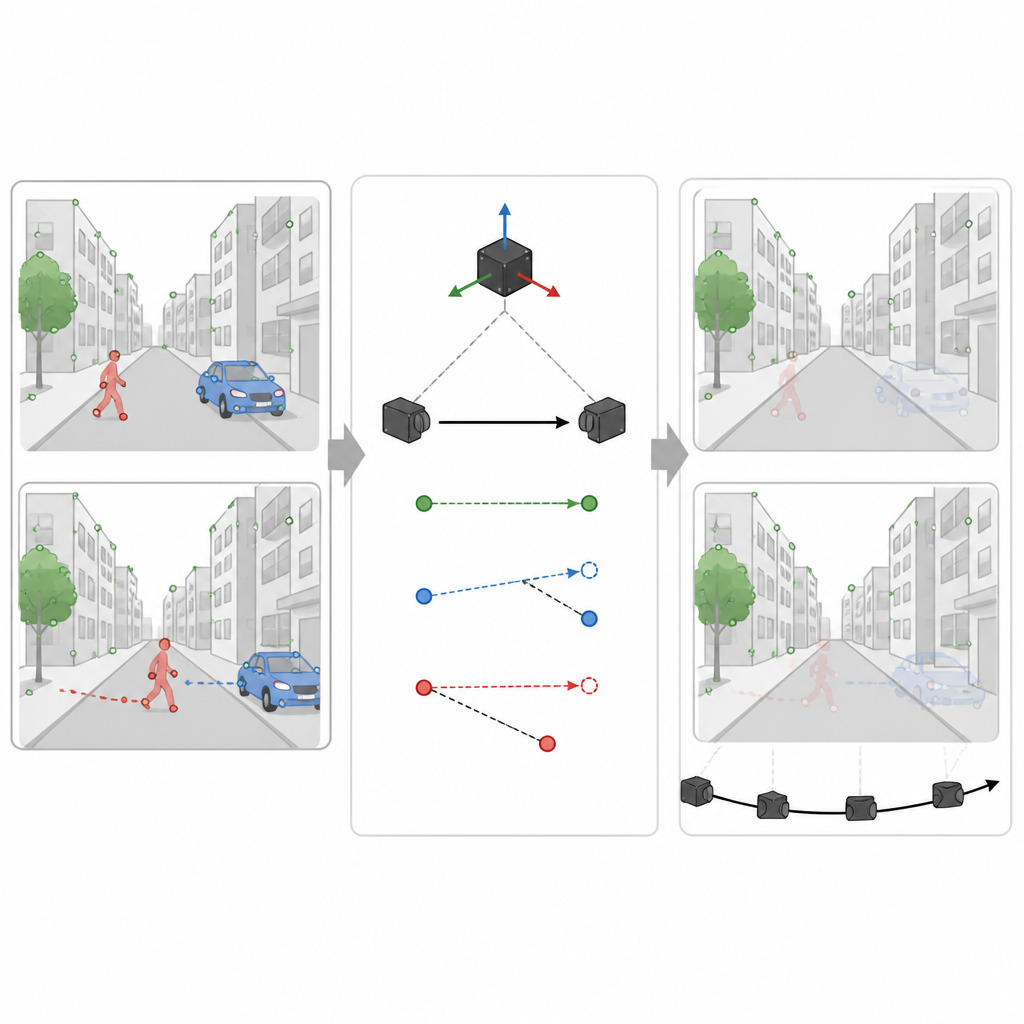
Using motion cues to spot what is really moving
However, not every car or person shaped region is actually moving at a given moment. A parked car should help the map, not hurt it. In the second stage, SuperDynaSLAM uses the motion sensor readings to work out how a truly fixed point in the scene ought to shift between two camera images. It compares this expected shift with what the camera actually sees for a few sample points on each object that might move. If points on an object stray too far from the expected path, the system concludes that the object is moving and marks all of its points as untrustworthy. If they stay close, the object is treated as part of the stable scene. This selective filtering lets the system throw away misleading information while keeping as many helpful details as possible.
Tested in virtual streets, offices, and markets
The researchers tested SuperDynaSLAM on three demanding collections of data. One set came from real indoor flights with rapid motion and changing light. Another was a simulated city and parking lot where traffic levels could be turned up from empty streets to heavy flow. The third was a robot driving through real offices, homes, markets, and cafes filled with moving shoppers and clutter. Across most of these trials, especially when there were many moving objects or sharp camera motion, SuperDynaSLAM followed the true path more closely and with less jitter than leading systems that rely on older visual features or only one type of cue.
What this means for everyday navigation
For a layperson, the key message is that SuperDynaSLAM helps machines focus on what is solid and dependable in a scene and tune out distracting motion. By combining learned visual features, object awareness, and motion sensing, it builds more accurate maps and tracks its position more steadily, even in crowded or fast changing environments. Although this comes with a higher computing cost and the system can still miss unusual moving objects, the approach marks a practical step toward more reliable navigation for driverless cars, delivery robots, and immersive virtual or mixed reality devices.
Citation: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Keywords: visual inertial SLAM, dynamic environments, feature extraction, robot navigation, computer vision