Clear Sky Science · it
SLAM visivo-inerziale migliorato usando SuperPoint e rilevamento semantico-geometrico delle caratteristiche dinamiche
Navigazione più intelligente in un mondo che si muove
Robot, droni e visori per realtà aumentata devono sapere esattamente dove si trovano mentre il mondo intorno a loro continua a muoversi. I sistemi di mappatura tradizionali possono essere confusi da persone che camminano o auto che passano, causando ad esempio frecce digitali che si spostano o un robot che valuta male il proprio percorso. Questo studio presenta SuperDynaSLAM, un metodo di navigazione progettato per mantenere una stima della posizione più affidabile in scene affollate e in cambiamento, usando strumenti di intelligenza artificiale moderni e sensori di movimento.
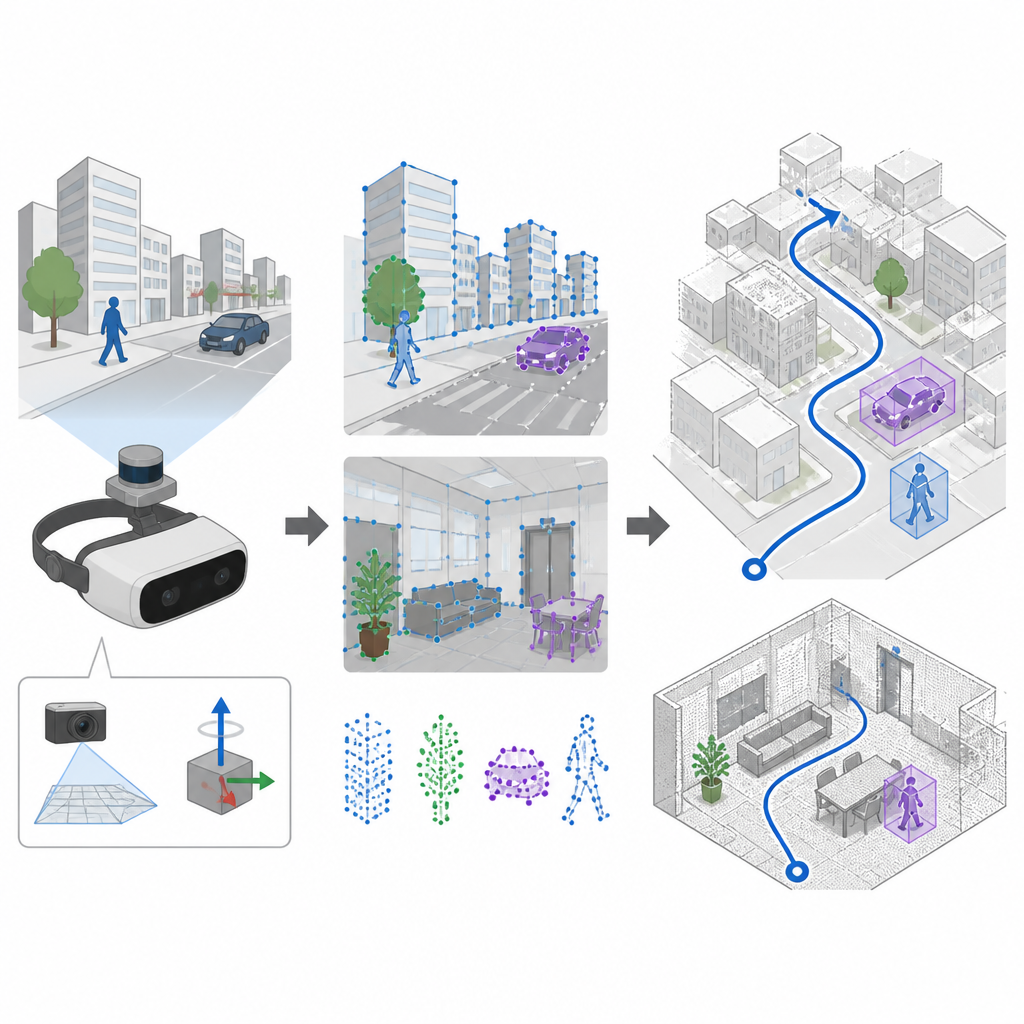
Vedere e percepire il movimento insieme
Molti sistemi di navigazione si basano su telecamere e su una tecnica chiamata SLAM per costruire una mappa e seguire la traiettoria simultaneamente. I sistemi più vecchi scelgono punti distintivi nell’immagine con regole artigianali, che funzionano bene in scene calme e ben illuminate ma spesso falliscono quando la fotocamera vibra o l’illuminazione cambia rapidamente. SuperDynaSLAM aggiorna questo front-end impiegando un estrattore di caratteristiche appreso chiamato SuperPoint, addestrato su molte viste di scene reali in modo da riconoscere ancora ancore visive affidabili anche quando la camera si muove violentemente o la visuale cambia molto. Il sistema sfrutta inoltre un’unità di sensori di movimento a bordo, che misura come il dispositivo ruota e accelera tra i fotogrammi della camera.
Separare lo sfondo dagli oggetti in movimento
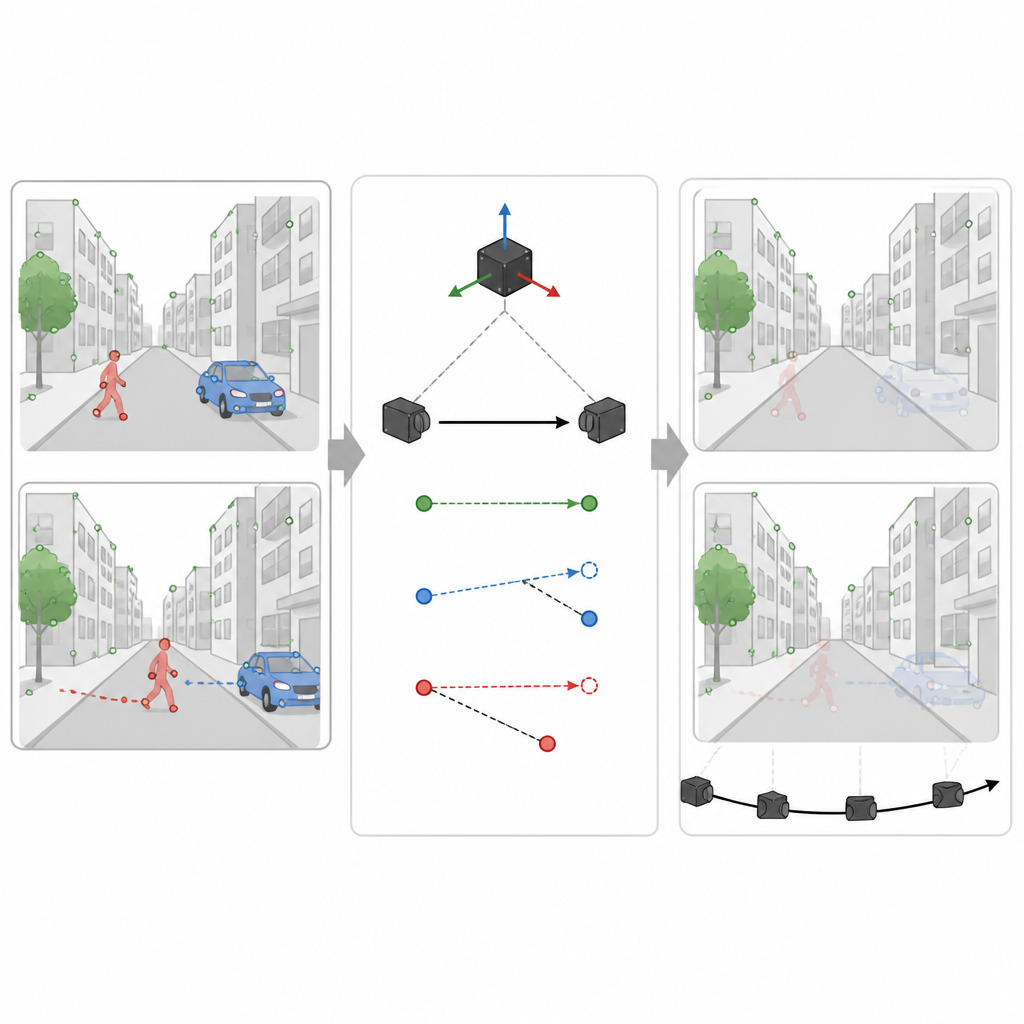
Una sfida importante per qualsiasi navigatore basato sulla visione è che non tutto ciò che si vede è fissato in posizione. Persone, auto e altri oggetti in movimento creano indizi visivi fuorvianti. SuperDynaSLAM affronta questo problema con un processo in due fasi. Prima applica a ogni immagine un modello di deep learning chiamato Mask R-CNN per tracciare contorni approssimativi degli oggetti che possono muoversi, come veicoli e pedoni. I punti caratteristici individuati da SuperPoint vengono poi raggruppati in tre tipi semplici in base alla loro posizione: sfondo, veicoli e pedoni. Il matching dei punti è permesso solo all’interno dello stesso tipo, il che riduce già errori evidenti, come associare l’angolo di un edificio a un’auto in transito.
Usare indizi di movimento per individuare ciò che si muove davvero
Tuttavia, non tutte le regioni a forma di auto o persona si stanno muovendo in un dato istante. Un’auto parcheggiata dovrebbe aiutare la mappa, non danneggiarla. Nella seconda fase, SuperDynaSLAM usa le letture del sensore di movimento per calcolare come un punto realmente fisso nella scena dovrebbe spostarsi tra due immagini della camera. Confronta questo spostamento atteso con ciò che la camera osserva effettivamente per alcuni punti campione su ciascun oggetto che potrebbe muoversi. Se i punti su un oggetto deviano troppo dal percorso atteso, il sistema conclude che l’oggetto è in movimento e marca tutti i suoi punti come inaffidabili. Se rimangono vicini, l’oggetto viene trattato come parte della scena stabile. Questo filtro selettivo permette al sistema di scartare informazioni fuorvianti mantenendo il maggior numero possibile di dettagli utili.
Testato in strade virtuali, uffici e mercati
I ricercatori hanno testato SuperDynaSLAM su tre collezioni di dati impegnative. Un set proveniva da voli indoor reali con rapido movimento e illuminazione variabile. Un altro era una città e un parcheggio simulati dove il livello di traffico poteva essere aumentato da strade vuote a flusso intenso. Il terzo era un robot che percorreva uffici, abitazioni, mercati e caffè reali pieni di clienti in movimento e ingombri. Nella maggior parte di queste prove, specialmente quando c’erano molti oggetti in movimento o movimenti bruschi della camera, SuperDynaSLAM ha seguito la traiettoria reale più da vicino e con meno jitter rispetto ai sistemi di punta che si basano su caratteristiche visive più datate o su un solo tipo di indizio.
Cosa significa per la navigazione di tutti i giorni
Per un lettore non tecnico, il messaggio chiave è che SuperDynaSLAM aiuta le macchine a concentrarsi su ciò che è solido e affidabile in una scena ed eliminare il movimento distraente. Combinando caratteristiche visive apprese, consapevolezza degli oggetti e sensori di movimento, costruisce mappe più accurate e tiene traccia della posizione in modo più stabile, anche in ambienti affollati o che cambiano rapidamente. Sebbene ciò comporti un costo computazionale maggiore e il sistema possa ancora non rilevare oggetti in movimento insoliti, l’approccio rappresenta un passo pratico verso una navigazione più affidabile per auto a guida autonoma, robot per le consegne e dispositivi per realtà virtuale o mista immersiva.
Citazione: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Parole chiave: SLAM visivo inerziale, ambienti dinamici, estrazione di caratteristiche, navigazione robotica, computer vision