Clear Sky Science · nl
Verbeterde visueel-inertiële SLAM met SuperPoint en semantische, geometrische dynamische detectie van features
Slimmere navigatie in een bewegende wereld
Robots, drones en augmented-realityheadsets moeten precies weten waar ze zijn terwijl de wereld om hen heen in beweging blijft. Traditionele kaartvormingssystemen raken in de war door voorbijlopende mensen of rijdende auto’s, wat ertoe kan leiden dat digitale pijlen van de weg afdrijven of een robot zijn route verkeerd inschat. Deze studie introduceert SuperDynaSLAM, een navigatiemethode die positie betrouwbaarder bijhoudt in drukke, veranderlijke scènes door moderne AI-technieken en bewegingssensoren te combineren.
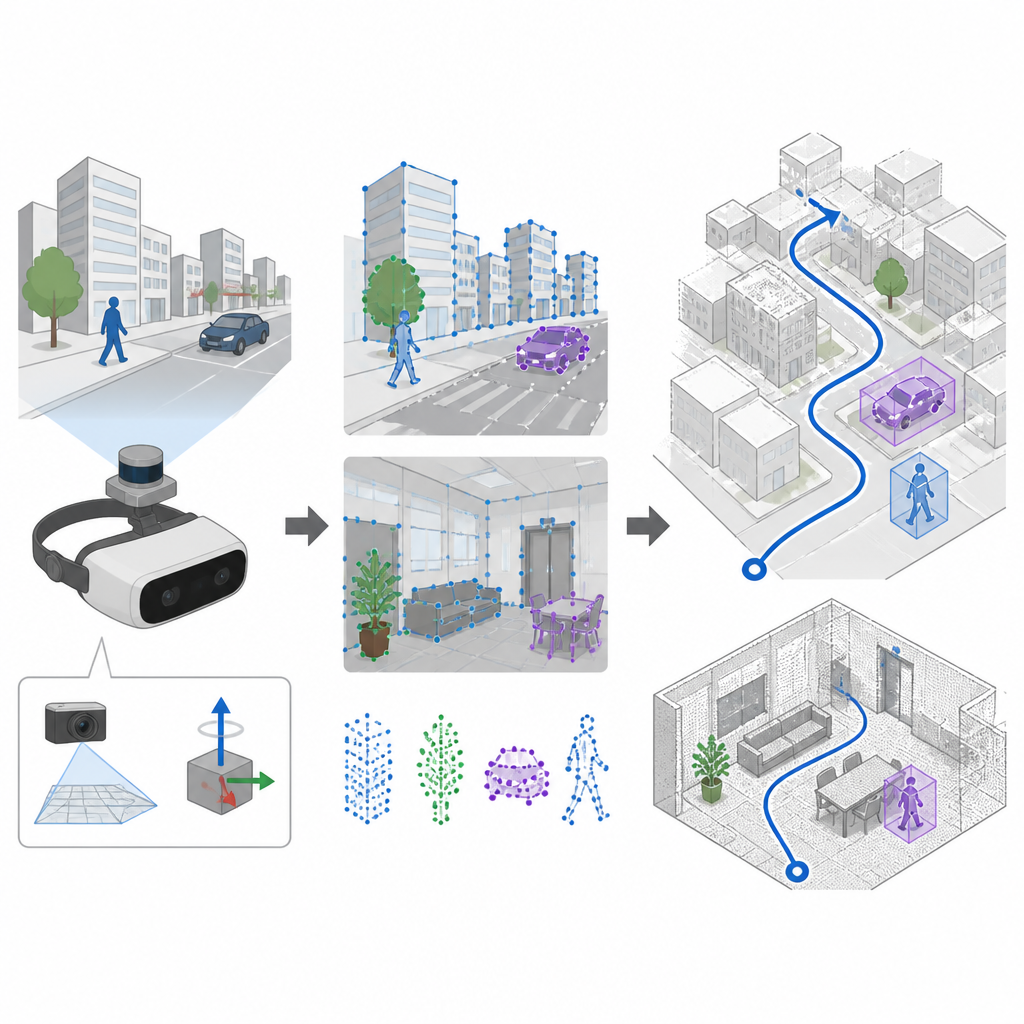
Beweging zien en voelen samen
Veel navigatiesystemen vertrouwen op camera’s en een techniek genaamd SLAM om gelijktijdig een kaart te bouwen en hun traject te volgen. Oudere systemen kiezen onderscheidende punten in het beeld met handgemaakte regels, wat goed werkt in rustige, goed verlichte scènes maar vaak faalt wanneer de camera schudt of het licht snel verandert. SuperDynaSLAM verbetert deze voorkant door een geleerd feature-zoeker te gebruiken die SuperPoint heet; die is getraind op veel verschillende aanzichten van echte scènes en kan betrouwbare visuele ankerpunten herkennen, zelfs bij heftige camerabewegingen of sterke veranderingen in het beeld. Het systeem gebruikt ook een ingebouwde inertiële meeteenheid die draait en versnelling tussen cameraframes meet.
Achtergrond scheiden van bewegende objecten
Een grote uitdaging voor elke visiegebaseerde navigator is dat niet alles in beeld vaststaat. Mensen, auto’s en andere bewegende objecten geven misleidende visuele signalen. SuperDynaSLAM pakt dit aan met een proces in twee fasen. Eerst past het een deep-learningprogramma genaamd Mask R-CNN toe op elk beeld om grove omtrekken van objecten die kunnen bewegen, zoals voertuigen en voetgangers, af te bakenen. De featurepunten die SuperPoint vindt worden vervolgens in drie eenvoudige typen gegroepeerd op basis van waar ze vallen: achtergrond, voertuigen en voetgangers. Het matchen van punten is alleen toegestaan binnen hetzelfde type, wat al duidelijke verwisselingen vermindert, zoals het matchen van een gebouwshoek met een voorbijrijdende auto.
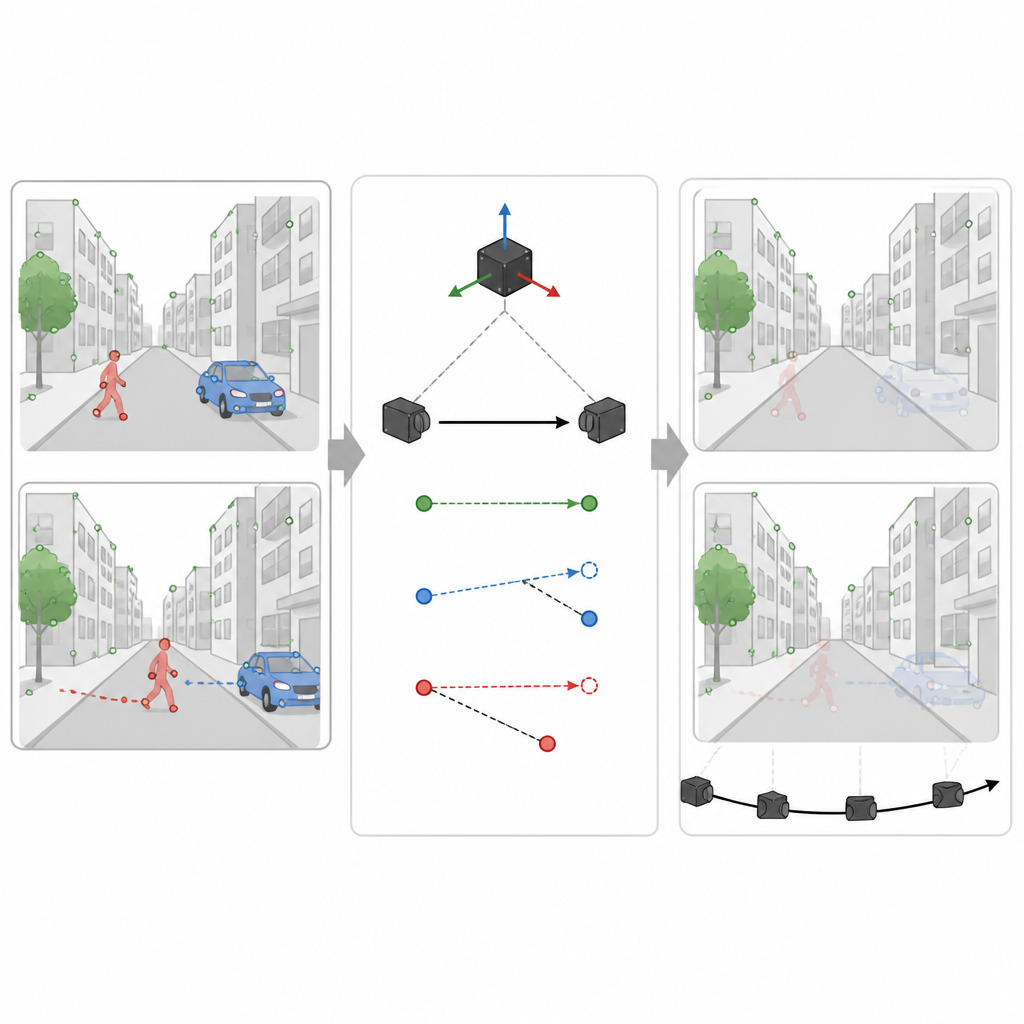
Bewegingssignalen gebruiken om echte beweging te herkennen
Niet elk auto- of mensvormig gebied beweegt op een gegeven moment echter daadwerkelijk. Een geparkeerde auto zou de kaart moeten helpen, niet schaden. In de tweede fase gebruikt SuperDynaSLAM de bewegingssensorwaarden om te berekenen hoe een werkelijk vast punt in de scène tussen twee camerabeelden zou moeten verschuiven. Het vergelijkt deze verwachte verschuiving met wat de camera daadwerkelijk ziet voor een aantal steekproefpunten op elk mogelijk bewegend object. Als punten op een object te ver afwijken van het verwachte pad, concludeert het systeem dat het object beweegt en markeert het al zijn punten als onbetrouwbaar. Blijven ze dicht bij de verwachting, dan wordt het object behandeld als deel van de stabiele scène. Deze selectieve filtering stelt het systeem in staat misleidende informatie weg te gooien terwijl zoveel mogelijk nuttige details behouden blijven.
Getest in virtuele straten, kantoren en markten
De onderzoekers hebben SuperDynaSLAM getest op drie veeleisende datasets. Een set kwam van echte indoorvluchten met snelle bewegingen en veranderende belichting. Een andere was een gesimuleerde stad en parkeerterrein waar het verkeer kon worden opgevoerd van lege straten tot zware doorstroming. De derde bestond uit een robot die door echte kantoren, huizen, markten en cafés reed, gevuld met bewegende shoppers en rommel. In de meeste van deze proeven, vooral wanneer er veel bewegende objecten waren of de camera sterke bewegingen maakte, volgde SuperDynaSLAM het werkelijke pad nauwkeuriger en met minder jitter dan toonaangevende systemen die vertrouwen op oudere visuele features of slechts één type signaal.
Wat dit betekent voor alledaagse navigatie
Voor een leek is de kernboodschap dat SuperDynaSLAM machines helpt zich te concentreren op wat solide en betrouwbaar is in een scène en afleidende bewegingen te negeren. Door geleerde visuele features, objectbewustzijn en bewegingsmeting te combineren, bouwt het nauwkeurigere kaarten en houdt het zijn positie stabieler bij, zelfs in drukke of snel veranderende omgevingen. Hoewel dit gepaard gaat met hogere rekenkosten en het systeem nog steeds ongebruikelijke bewegende objecten kan missen, markeert de aanpak een praktische stap naar betrouwbaardere navigatie voor zelfrijdende auto’s, bezorrobots en meeslepende virtuele of mixed-realityapparaten.
Bronvermelding: Cui, J., Huang, Y. & Wang, L. Enhanced visual-inertial SLAM Using SuperPoint and semantic geometric dynamic feature detection. Sci Rep 16, 15538 (2026). https://doi.org/10.1038/s41598-026-46629-0
Trefwoorden: visueel inertiële SLAM, dynamische omgevingen, feature-extractie, robotnavigatie, computer vision