Clear Sky Science · zh
将非文本线索与经典自然语言处理融合以增强多模态假新闻传播检测
为什么识别假新闻变得更难
我们的日常新闻现在通过手机和社交信息流到达,真实与虚假的故事并肩以很高的速度传播。许多虚假帖子在外观和语气上与真实新闻无异,这使得仅阅读文字的工具难以识别。本文提出了一种新方法,让计算机不仅阅读文本,还观察人们如何分享它以及写作本身的构成,旨在更准确、更迅速地标记错误信息。
超越屏幕上的文字
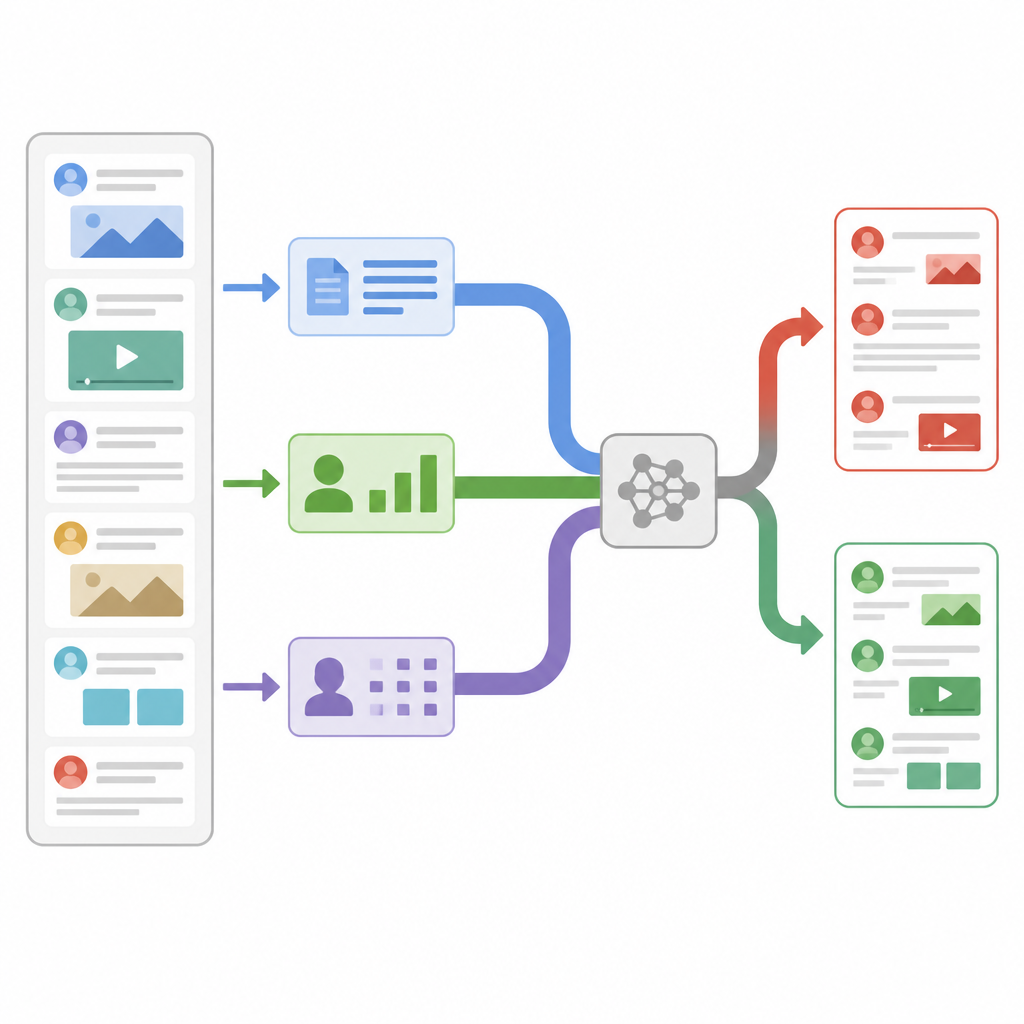
早期的大多数假新闻检测器侧重于单一信息源,通常是文章文本。它们统计词频、分析写作风格,或使用现代语言模型理解含义。这些系统在简单情况下表现良好,但在虚假故事刻意模仿受信任媒体的语调和词汇时就难以应对。其他研究者开始加入来自社交媒体的额外信号,例如帖子被分享的频率或是谁在分享,但他们通常只是把这些信号简单拼接在一起,而没有探究对每则故事而言哪些信号更重要。新研究认为,内容和传播方式都携带线索,灵活的系统必须根据具体情形即时决定信任哪些线索。
来自每则新闻的三类线索
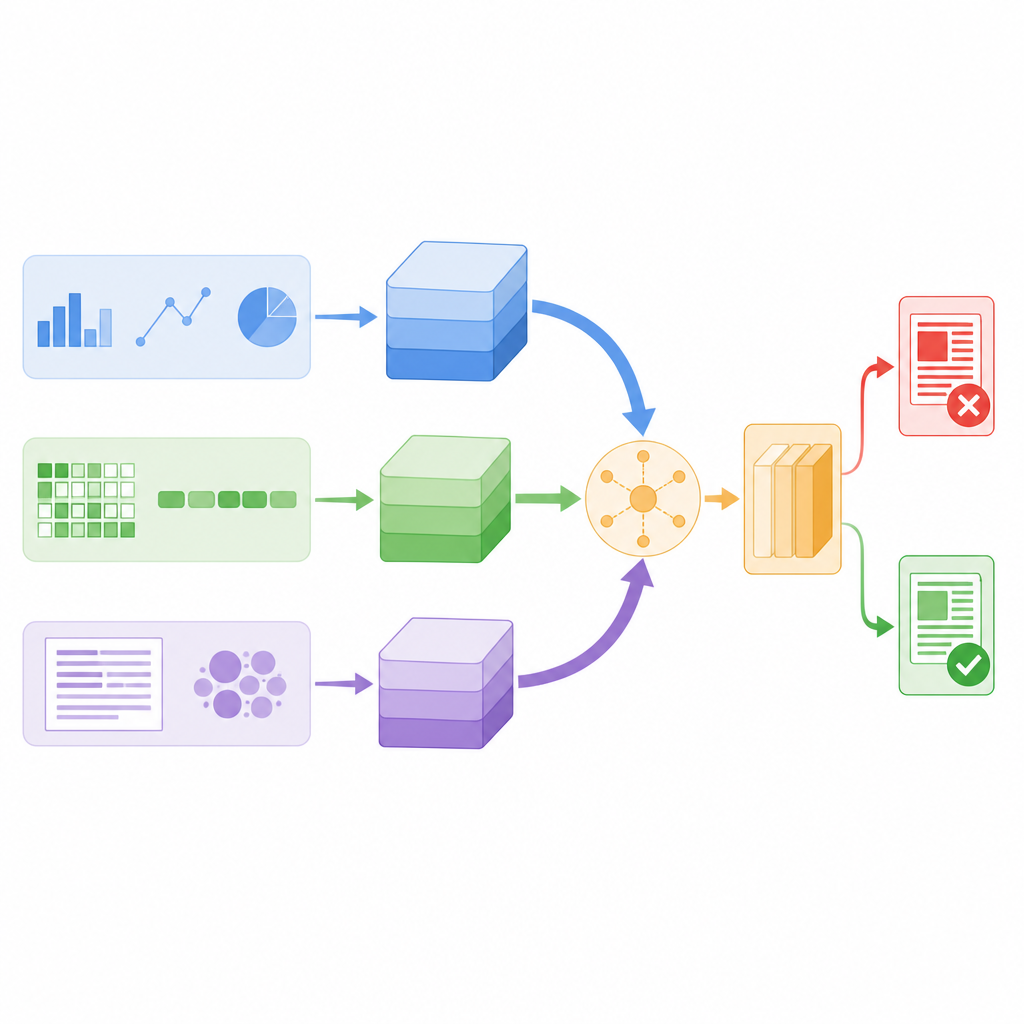
研究人员设计了一个同时通过三种不同视角审视每则新闻帖子的模型。首先,它计算有关文本和发布账户的工程统计量,例如粉丝转发或评论的频率、消息发送时间,以及标点或话题标签的使用强度。其次,它细化到字符级别,将单词分解为短的字符链,以便在遇到俚语、创造性拼写或故意错字时仍能识别模式。第三,它关注词义,将每个词转为数值向量,捕捉其在日常语言中的用法。每个视角用自身的小型神经网络将发现压缩为紧凑摘要,以滤除噪声细节,然后再将这些线索合并。
让系统自行选择信任什么
该模型没有简单地将所有这些摘要堆叠在一起,而是使用一种称为自注意力的机制为每则故事赋予不同权重。实际上,这意味着系统学会何时更多依赖用户行为、何时侧重词义、以及何时信赖字符模式。例如,如果一则帖子在语言上看起来正常但通过可疑的转发模式传播,行为分支就可以拥有更高权重。所有三条分支通过注意力分数交换信息,然后平均为单一决策向量,供最终分类器判断新闻为真还是假。该设计使模型参数总量相对较低,从而足够快速以用于实时监测。
在真实社交媒体数据上表现如何
团队在两个广泛使用的基于 Twitter 的数据集上测试了该方法。一个名为 GossipCop,覆盖娱乐类谣言;另一个为 PolitiFact,包含政治性声明。在两组数据上,该模型显著优于仅用文本、仅用行为或简单结合二者的早期方法。在 GossipCop 上其正确标注了约 99% 的条目,而在更具挑战性的 PolitiFact 数据集上则达到了约 96% 的准确率。它在更严苛的测试中也保持了稳定,例如向文本添加键盘风格的错别字,或将仅在名人新闻上训练的模型用于判断政治帖子。在这些情况下,当仅基于词的模型崩溃时,字符级和行为线索有助于保留大量性能。
对普通新闻读者意味着什么
这项研究表明,可靠的假新闻检测必须关注的不仅是故事的内容,还包括写作方式和其在社交网络中的传播方式。通过融合这些视角并让系统根据具体情况调整其重要性,所提出的模型能够以高置信度标记可疑帖子,同时保持足够轻量以部署在实时平台上。对于普通用户而言,这并不能取代细致阅读或人工事实核查,但可以作为一种早期预警层,在误导性故事扩散到大范围受众之前减缓其传播。
引用: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
关键词: 假新闻, 社交媒体, 错误信息, 深度学习, 多模态分析