Clear Sky Science · ru
Слияние нетекстовых сигналов с классической НЛП для улучшенного обнаружения распространения фейковых новостей в мультимодальных данных
Почему распознавать фейковые новости становится сложнее
Наши ежедневные новости теперь приходят через телефоны и ленты социальных сетей, где правдивые и ложные истории распространяются бок о бок на высокой скорости. Многие фейковые посты выглядят и звучат так же, как настоящая журналистика, что затрудняет их обнаружение инструментами, которые читают только слова. В этом исследовании предложен новый подход, позволяющий компьютерам оценивать онлайн-истории не только по тексту, но и по тому, как их распространяют, а также по особенностям самого письма, с целью более точного и быстрого выявления дезинформации.
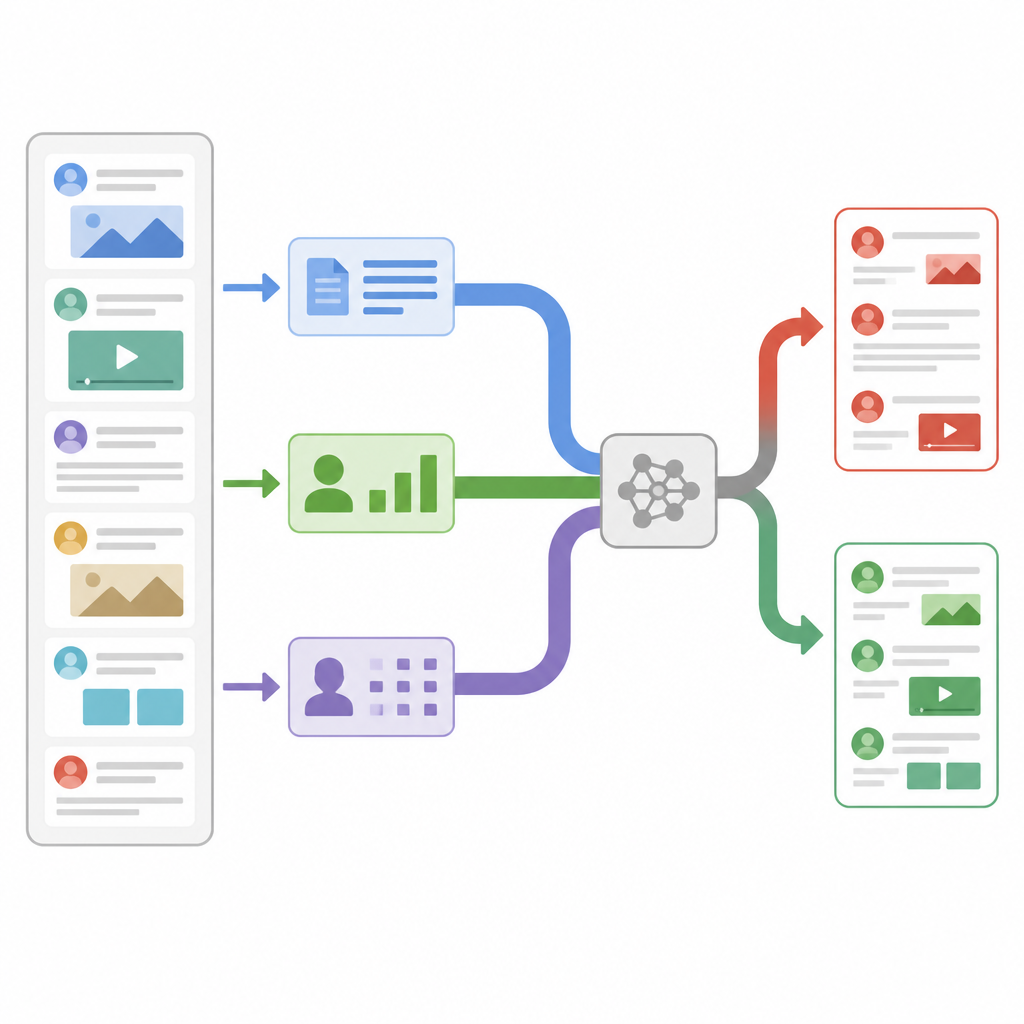
Смотреть дальше, чем слова на экране
Большинство ранних детекторов фейковых новостей сосредотачивались на одном источнике информации, обычно на тексте статьи. Они считали частоты слов, анализировали стиль письма или использовали современные языковые модели для извлечения смысла. Такие системы хорошо работают в простых случаях, но испытывают затруднения, когда фейковые истории внимательно подражают тону и словарю признанных изданий. Другие исследователи начали добавлять дополнительные сигналы из социальных сетей, такие как частота репостов или кто делится публикацией, но обычно просто объединяли все эти признаки, не выясняя, какие из них важнее для каждой конкретной истории. Новое исследование утверждает, что и содержание, и способ распространения несут подсказки, и что гибкая система должна в реальном времени решать, каким подсказкам доверять сильнее.
Три типа подсказок для каждого новостного элемента
Авторы разработали модель, которая одновременно рассматривает каждый новостной пост через три разных призмы. Во‑первых, она вычисляет инженерные статистики о тексте и об аккаунте, разместившем его, такие как как часто подписчики репостят или комментируют, когда было отправлено сообщение, и насколько активно используются пунктуация или хэштеги. Во‑вторых, она приближается до уровня отдельных символов, разбивая слова на короткие цепочки символов, чтобы распознавать паттерны при использовании сленга, творческой орфографии или намеренных опечаток. В‑третьих, она анализирует смысл слов, преобразуя каждое слово в числовой вектор, который отражает его употребление в языке. Каждая призма сводит свои результаты в компактное резюме с помощью собственной небольшой нейронной сети, так что шумные детали фильтруются до объединения подсказок.
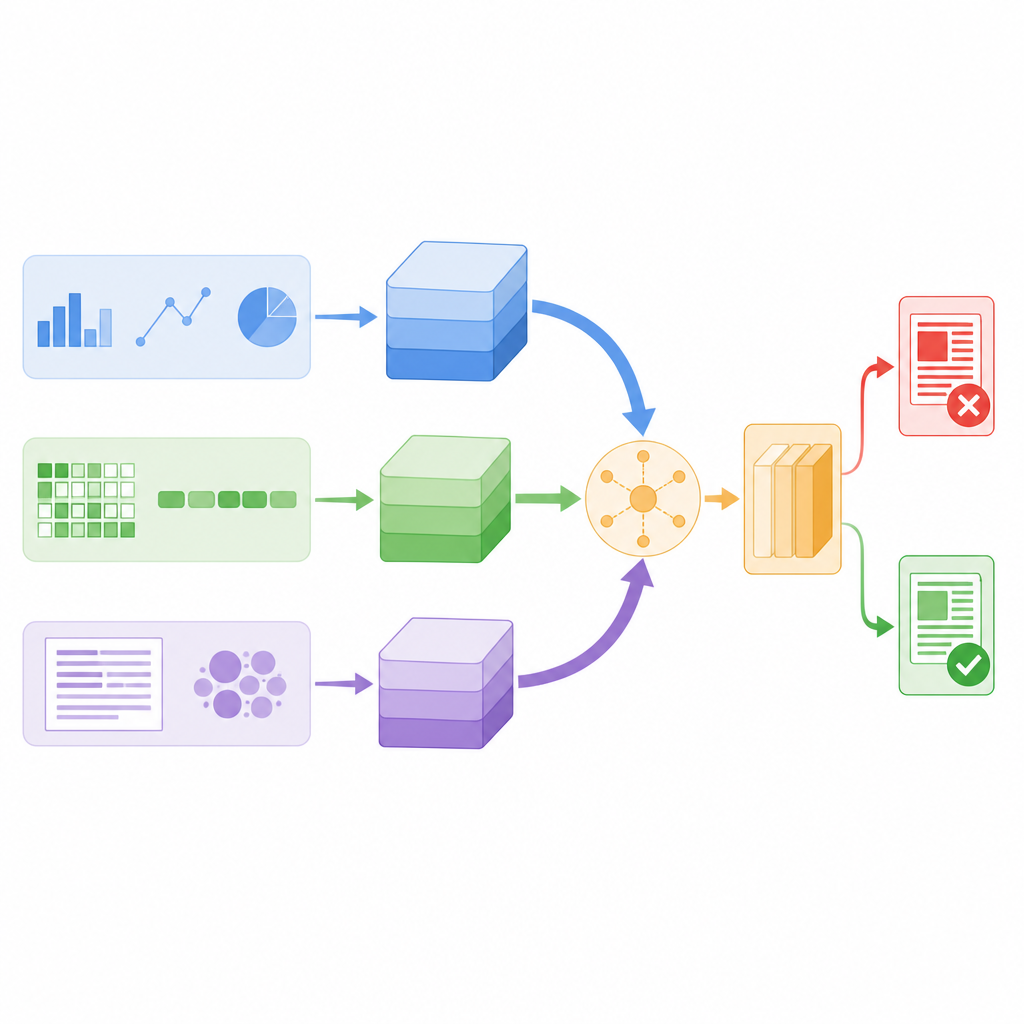
Позволяя системе выбирать, чему доверять
Вместо простого складирования всех этих резюме модель использует механизм, называемый self-attention, чтобы по‑разному взвешивать их для каждой истории. На практике это означает, что система учится, когда опираться больше на поведение пользователей, когда фокусироваться на значении слов и когда полагаться на паттерны на уровне символов. Например, если пост лингвистически выглядит нормально, но распространяется по подозрительной схеме, ветвь, анализирующая поведение, может получить больший вес. Все три ветви обмениваются информацией через оценки внимания и затем усредняются в единый вектор решения, который подаётся на финальный классификатор, помечающий новость как правдивую или фейковую. Такая конструкция сохраняет относительно небольшое количество параметров модели, делая её достаточно быстрой для мониторинга в реальном времени.
Насколько хорошо это работает на реальных данных социальных сетей
Команда протестировала подход на двух широко используемых наборах данных на основе Twitter. Один, называемый GossipCop, охватывает слухи об развлечениях; другой, PolitiFact, содержит политические утверждения. В обоих наборах модель значительно превзошла предыдущие методы, использующие только текст, только поведение или простые их комбинации. На GossipCop она правильно пометила около 99 процентов элементов, а на более сложном наборе PolitiFact достигла примерно 96 процентов точности. Модель также выдержала более строгие испытания, такие как добавление опечаток в стиле клавиатуры к тексту или использование модели, обученной на новостях о знаменитостях, для оценки политических публикаций. В этих случаях подсказки на уровне символов и поведенческие признаки помогли сохранить большую часть производительности там, где модели, основанные только на словах, давали сбои.
Что это значит для обычных читателей новостей
Исследование показывает, что надёжное обнаружение фейковых новостей должно обращать внимание не только на то, что говорит история, но и на то, как она написана и как перемещается по социальной сети. Смешивая эти представления и позволяя системе адаптировать их важность в каждом конкретном случае, предложенная модель может с высокой уверенностью помечать подозрительные посты, оставаясь при этом лёгкой для развертывания на живых платформах. Для обычных пользователей это не заменяет внимательное чтение или человеческую проверку фактов, но может выступать как слой раннего предупреждения, замедляющий распространение вводящих в заблуждение историй до того, как они охватят широкую аудиторию.
Цитирование: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Ключевые слова: фейковые новости, социальные сети, дезинформация, глубокое обучение, мультимодальный анализ