Clear Sky Science · de
Kombination nicht-textlicher Signale mit klassischer NLP zur verbesserten Erkennung der Verbreitung multimodaler Falschmeldungen
Warum das Aufspüren von Falschmeldungen schwieriger wird
Unsere täglichen Nachrichten erreichen uns heute über Smartphones und soziale Feeds, wo wahre und falsche Geschichten mit hoher Geschwindigkeit nebeneinander gelangen. Viele gefälschte Beiträge sehen aus und klingen wie echte journalistische Inhalte, weshalb sie mit Werkzeugen, die nur den Text lesen, schwer zu erkennen sind. Diese Studie stellt einen neuen Ansatz vor, mit dem Computer Online-Beiträge nicht nur lesen, sondern auch beobachten, wie sie geteilt werden und wie die Sprache selbst aufgebaut ist, mit dem Ziel, Desinformation genauer und schneller zu kennzeichnen.
Über die Worte auf dem Bildschirm hinausblicken
Die meisten früheren Falschmeldungserkenner konzentrierten sich auf eine einzige Informationsquelle, meist den Artikelttext. Sie zählten Wortfrequenzen, analysierten Schreibstile oder nutzten moderne Sprachmodelle, um Bedeutungen zu erfassen. Diese Systeme funktionieren bei einfachen Fällen gut, haben aber Schwierigkeiten, wenn gefälschte Geschichten bewusst den Ton und das Vokabular vertrauenswürdiger Quellen nachahmen. Andere Forscher begannen, zusätzliche Signale aus sozialen Medien hinzuzufügen, etwa wie oft ein Beitrag geteilt wird oder wer ihn teilt, doch meist wurden all diese Signale einfach zusammengefügt, ohne zu prüfen, welche für jeden Beitrag am wichtigsten sind. Die neue Studie argumentiert, dass sowohl der Inhalt als auch die Art der Verbreitung Hinweise liefern und dass ein flexibles System dynamisch entscheiden muss, welchen Hinweisen es mehr vertraut.
Drei Arten von Hinweisen zu jedem Beitrag
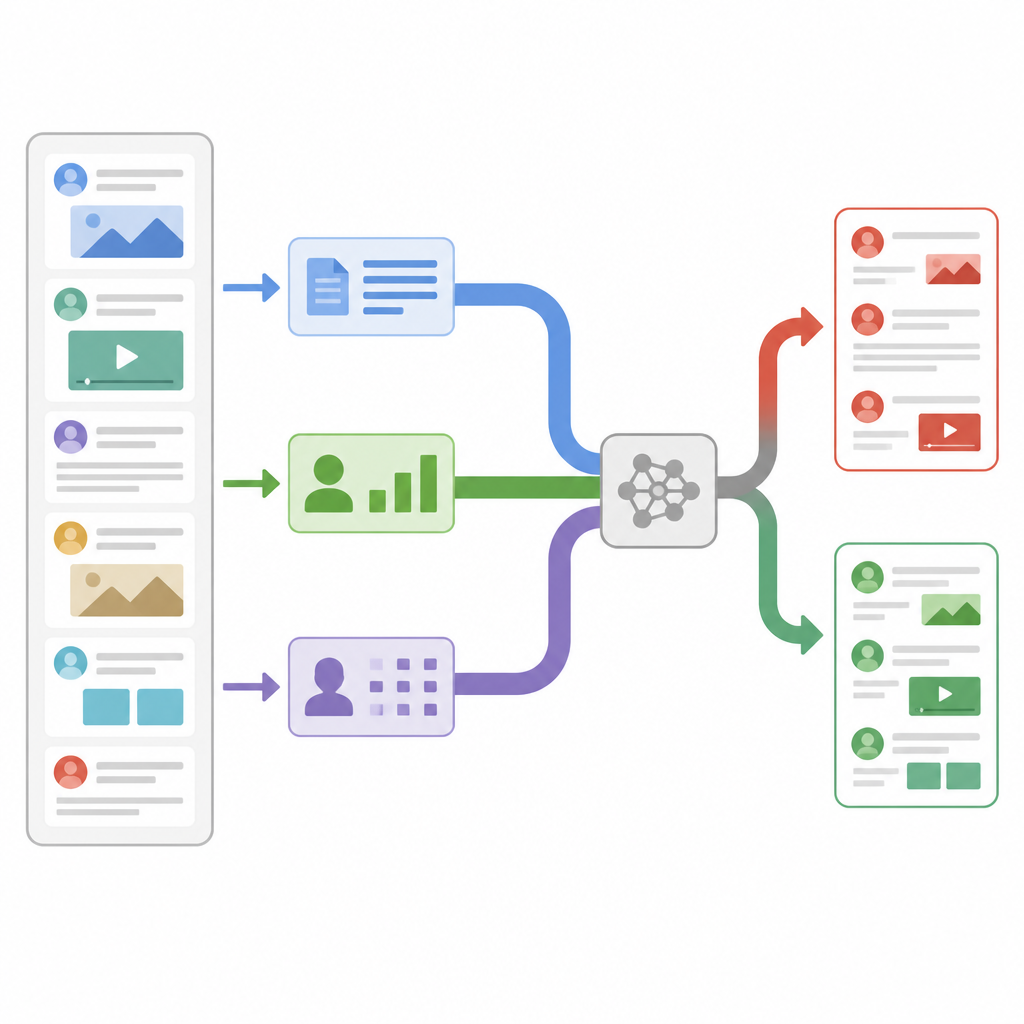
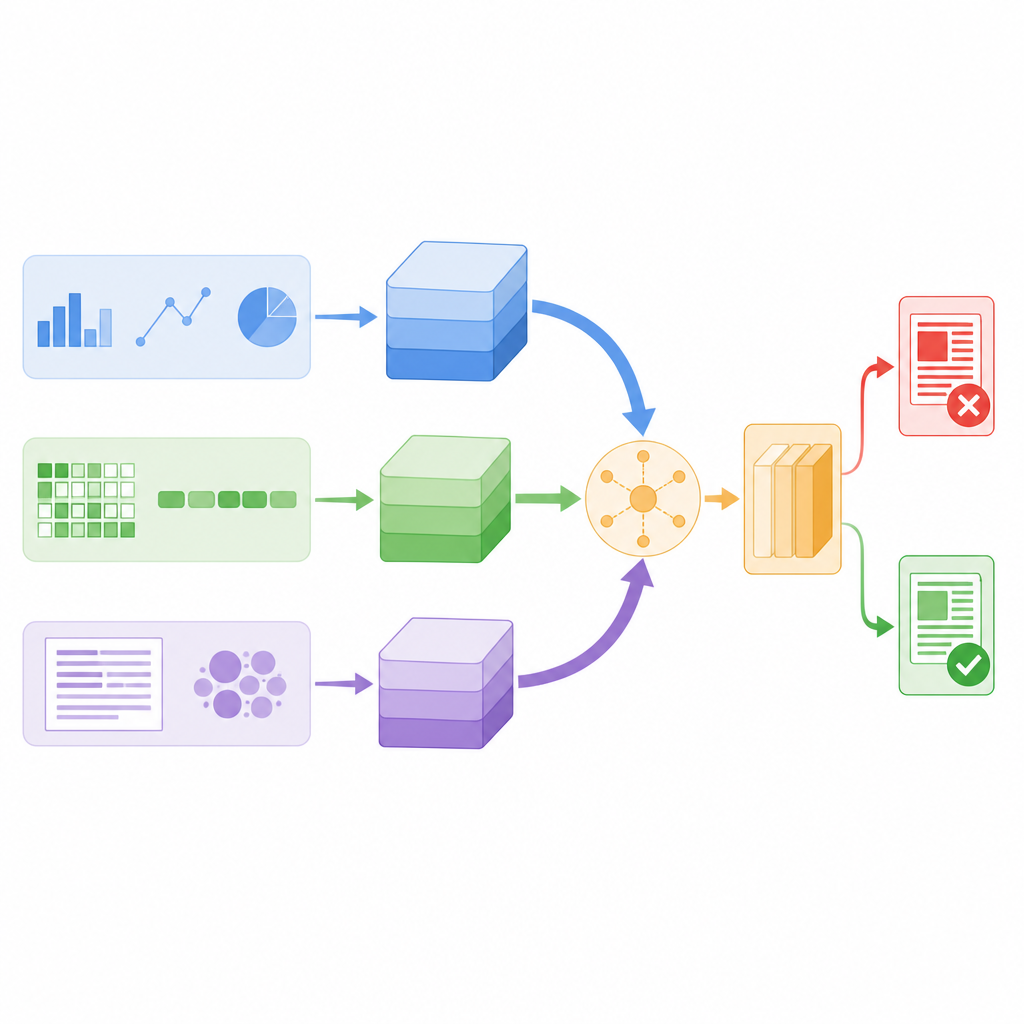
Die Forscher entwarfen ein Modell, das jeden Nachrichtenbeitrag gleichzeitig durch drei verschiedene Linsen betrachtet. Erstens berechnet es handgefertigte Statistiken über den Text und das Konto, das ihn postete, wie etwa wie häufig Follower weiterverbreiten oder kommentieren, wann die Nachricht gesendet wurde und wie stark sie Satzzeichen oder Hashtags verwendet. Zweitens zoomt es auf die Ebene einzelner Zeichen, zerlegt Wörter in kurze Zeichenketten, sodass Muster auch dann erkannt werden können, wenn Menschen Slang, kreative Schreibweisen oder absichtliche Tippfehler verwenden. Drittens betrachtet es Wortbedeutungen, indem jedes Wort in einen numerischen Vektor übersetzt wird, der seine Nutzung in der Alltagssprache erfasst. Jede Linse verdichtet ihre Erkenntnisse mithilfe eines eigenen kleinen neuronalen Netzes zu einer kompakten Zusammenfassung, sodass rauschende Details herausgefiltert werden, bevor die Hinweise kombiniert werden.
Das System entscheiden lassen, worauf es vertraut
Anstatt diese Zusammenfassungen einfach nur übereinanderzustapeln, nutzt das Modell einen Mechanismus namens Self-Attention, um sie für jede Geschichte unterschiedlich zu gewichten. Praktisch bedeutet das: Das System lernt, wann es stärker auf Nutzerverhalten setzen sollte, wann es sich auf Wortbedeutungen konzentriert und wann es sich auf Zeichenmuster stützt. Wenn ein Beitrag zum Beispiel linguistisch normal wirkt, sich aber in einem verdächtigen Verbreitungsmuster bewegt, kann der Verhaltenszweig mehr Gewicht erhalten. Alle drei Zweige tauschen Informationen über Aufmerksamkeitswerte aus und werden dann zu einem einzelnen Entscheidungsvektor gemittelt, der einen finalen Klassifikator versorgt, der die Nachricht als echt oder falsch einstuft. Dieses Design hält die Gesamtzahl der Modellparameter relativ gering und macht es schnell genug für Echtzeitüberwachung.
Wie gut funktioniert es in realen Social-Media-Daten
Das Team testete seinen Ansatz an zwei weithin genutzten Twitter-basierten Sammlungen. Die eine, genannt GossipCop, behandelt Unterhaltungsgerüchte; die andere, PolitiFact, enthält politische Behauptungen. In beiden Datensätzen übertraf das Modell frühere Methoden, die nur Text, nur Verhalten oder einfache Kombinationen beider nutzten, deutlich. Bei GossipCop klassifizierte es etwa 99 Prozent der Beiträge korrekt, und im schwierigeren PolitiFact-Set erreichte es rund 96 Prozent Genauigkeit. Es hielt auch härteren Prüfungen stand, etwa wenn der Text um tippfehlerähnliche Eingaben ergänzt wurde oder wenn das auf Promi-Nachrichten trainierte Modell politische Beiträge beurteilen sollte. In diesen Fällen halfen die Zeichenebene und die Verhaltenshinweise, einen Großteil der Leistung zu bewahren, während rein wortbasierte Modelle versagten.
Was das für alltägliche Nachrichtenleser bedeutet
Die Studie zeigt, dass verlässliche Erkennung von Falschmeldungen nicht nur darauf achten muss, was eine Geschichte sagt, sondern auch, wie sie geschrieben ist und wie sie sich durch ein soziales Netzwerk bewegt. Indem diese Perspektiven kombiniert und ihre Bedeutung fallweise angepasst wird, kann das vorgeschlagene Modell verdächtige Beiträge mit hoher Zuversicht markieren und zugleich leichtgewichtig genug bleiben, um in Live-Plattformen eingesetzt zu werden. Für gewöhnliche Nutzende ersetzt dies kein sorgfältiges Lesen oder menschliche Faktenprüfung, kann aber als frühwarnende Schicht wirken, die die Verbreitung irreführender Geschichten bremst, bevor sie große Zielgruppen erreicht.
Zitation: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Schlüsselwörter: Falschmeldungen, Soziale Medien, Desinformation, Deep Learning, multimodale Analyse