Clear Sky Science · en
Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection
Why spotting fake news is getting harder
Our daily news now arrives through phones and social feeds, where true and false stories travel side by side at high speed. Many fake posts look and sound just like real journalism, which makes them hard to catch with tools that only read the words. This study presents a new way for computers to judge online stories by not only reading the text, but also watching how people share it and how the writing itself is put together, with the goal of flagging misinformation more accurately and more quickly.
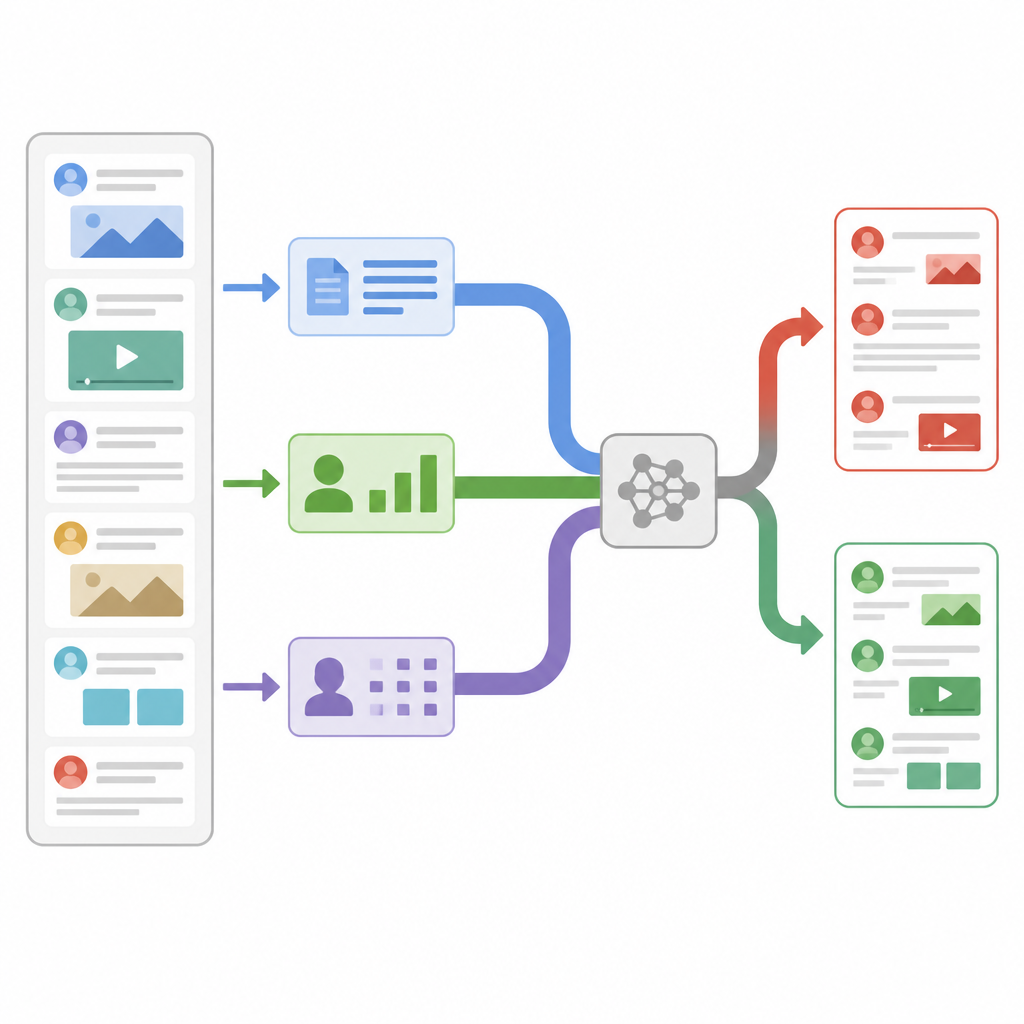
Looking beyond the words on the screen
Most earlier fake news detectors focused on a single source of information, usually the article text. They counted word frequencies, looked at writing style, or used modern language models to understand meaning. These systems work well on simple cases, but struggle when fake stories carefully imitate the tone and vocabulary of trusted outlets. Other researchers began adding extra signals from social media, such as how often a post is shared or who is sharing it, yet they usually just glued all these signals together without asking which ones matter most for each story. The new study argues that both the content and the way it spreads carry clues, and that a flexible system must decide on the fly which clues to trust more.
Three kinds of clues from each news item
The researchers designed a model that examines every news post through three different lenses at the same time. First, it computes engineered statistics about the text and about the account that posted it, such as how often followers repost or comment, when the message was sent, and how heavily it uses punctuation or hashtags. Second, it zooms in to the level of individual characters, breaking words into short character chains so that it can still recognize patterns when people use slang, creative spelling, or deliberate typos. Third, it looks at word meaning, turning each word into a numeric vector that captures how it is used in everyday language. Each lens turns its findings into a compact summary using its own small neural network, so that noisy details are filtered out before the clues are combined.
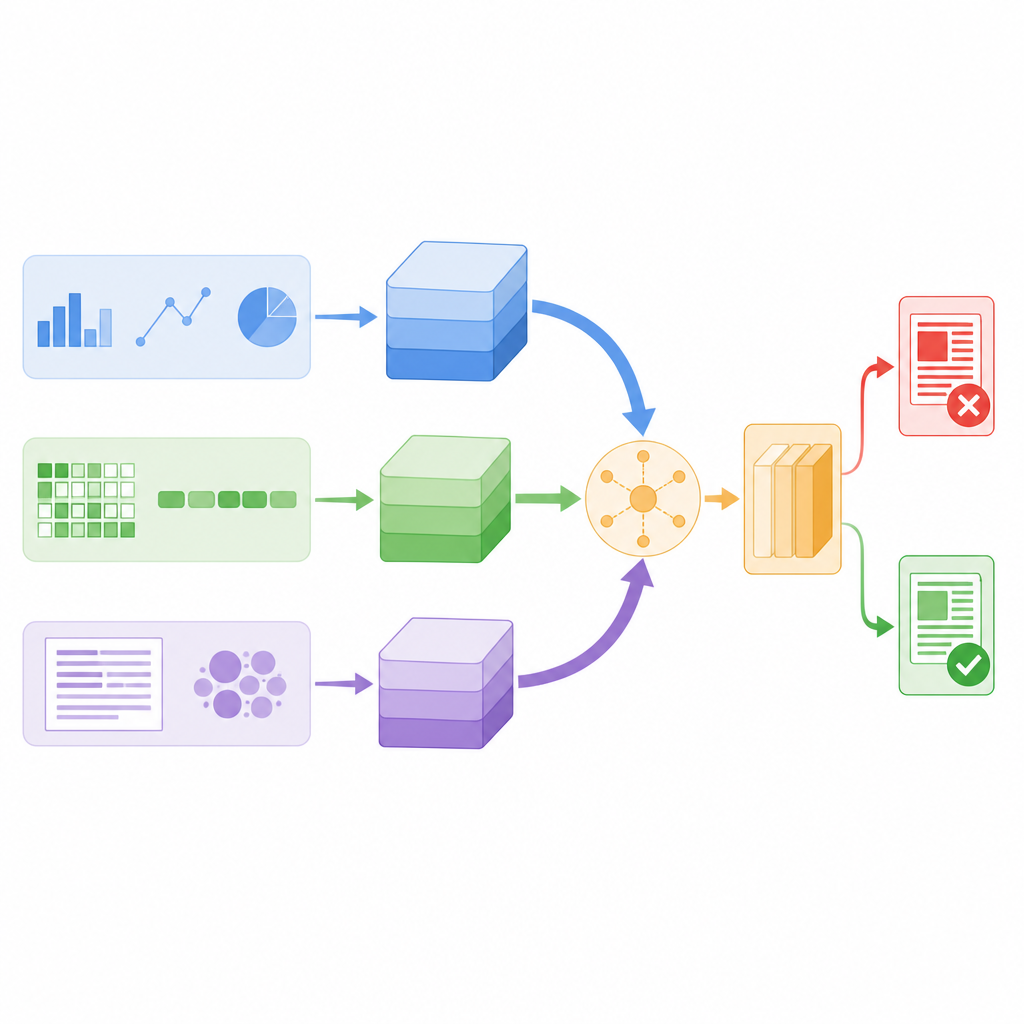
Letting the system choose what to trust
Instead of simply stacking all these summaries together, the model uses a mechanism called self attention to weigh them differently for each story. In practice, this means the system learns when to lean more on user behavior, when to focus on word meaning, and when to rely on character patterns. For example, if a post looks linguistically normal but travels through a suspicious sharing pattern, the behavioral branch can carry more weight. All three branches exchange information through attention scores and are then averaged into a single decision vector, which feeds a final classifier that labels the news as real or fake. This design keeps the total number of model parameters relatively low, making it fast enough for real time monitoring.
How well does it work in real social media data
The team tested their approach on two widely used Twitter based collections. One, called GossipCop, covers entertainment rumors; the other, PolitiFact, contains political claims. In both sets, the model greatly outperformed earlier methods that used only text, only behavior, or simple combinations of both. On GossipCop it correctly labeled about 99 percent of items, and on the more difficult PolitiFact set it reached about 96 percent accuracy. It also held up under tougher tests, such as adding keyboard style typos to the text or asking the model trained on celebrity news to judge political posts. In these cases, the character level and behavioral clues helped preserve much of the performance when word based models alone broke down.
What this means for everyday news readers
The study shows that reliable fake news detection must pay attention not just to what a story says, but also to how it is written and how it moves through a social network. By blending these views and letting the system adapt their importance case by case, the proposed model can flag suspicious posts with high confidence while staying lightweight enough to be deployed in live platforms. For ordinary users, this does not replace careful reading or human fact checking, but it could act as an early warning layer that slows the spread of misleading stories before they reach large audiences.
Citation: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Keywords: fake news, social media, misinformation, deep learning, multimodal analysis