Clear Sky Science · fr
Fusionner des indices non textuels avec le TAL classique pour améliorer la détection multimodale de la diffusion de fausses informations
Pourquoi repérer les fausses nouvelles devient plus difficile
Nos informations quotidiennes arrivent désormais par téléphone et via les fils sociaux, où véritables et fausses histoires circulent côte à côte à grande vitesse. Beaucoup de publications fabriquées ressemblent et sonnent comme du journalisme réel, ce qui les rend difficiles à détecter avec des outils qui se contentent de lire les mots. Cette étude présente une nouvelle manière pour les ordinateurs d’évaluer les histoires en ligne en lisant non seulement le texte, mais aussi en observant comment les gens le partagent et comment le propos est structuré, dans le but de signaler la désinformation de façon plus précise et plus rapide.
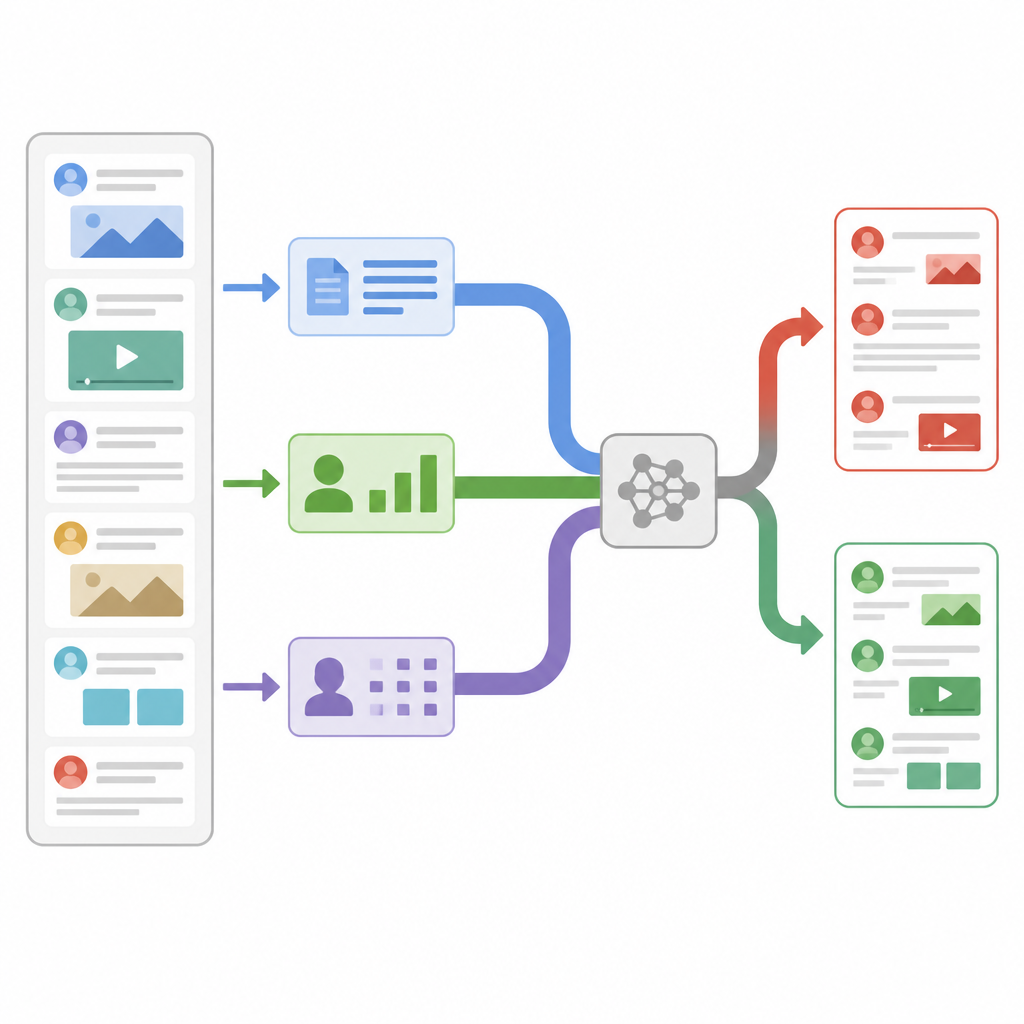
Regarder au‑delà des mots à l’écran
La plupart des détecteurs de fausses informations antérieurs se concentraient sur une seule source d’information, généralement le texte de l’article. Ils comptaient les fréquences de mots, étudiaient le style d’écriture ou utilisaient des modèles de langue modernes pour appréhender le sens. Ces systèmes fonctionnent bien dans des cas simples, mais peinent lorsque des histoires fabriquées imitent soigneusement le ton et le vocabulaire de sources crédibles. D’autres chercheurs ont commencé à ajouter des signaux issus des réseaux sociaux, comme la fréquence de partage d’un post ou l’identité de ceux qui le partagent, mais ils ont généralement agrégé ces signaux sans se demander lesquels importent le plus pour chaque message. La nouvelle étude soutient que le contenu et la manière dont il se propage portent tous deux des indices, et qu’un système flexible doit décider en temps réel lesquels privilégier.
Trois types d’indices pour chaque élément d’information
Les auteurs ont conçu un modèle qui examine chaque message à travers trois lentilles simultanées. D’abord, il calcule des statistiques conçues à la main sur le texte et sur le compte qui a posté, comme la fréquence de repartage ou de commentaires des abonnés, l’heure d’envoi, et l’intensité d’utilisation de la ponctuation ou des hashtags. Ensuite, il zoome au niveau des caractères individuels, en décomposant les mots en courtes chaînes de caractères afin de reconnaître des motifs quand les gens emploient de l’argot, des orthographes créatives ou des fautes volontaires. Troisièmement, il considère le sens des mots, en transformant chaque mot en un vecteur numérique qui capture son usage dans la langue courante. Chaque lentille condense ses observations en un résumé compact via son propre petit réseau neuronal, de sorte que les détails bruyants sont filtrés avant la fusion des indices.
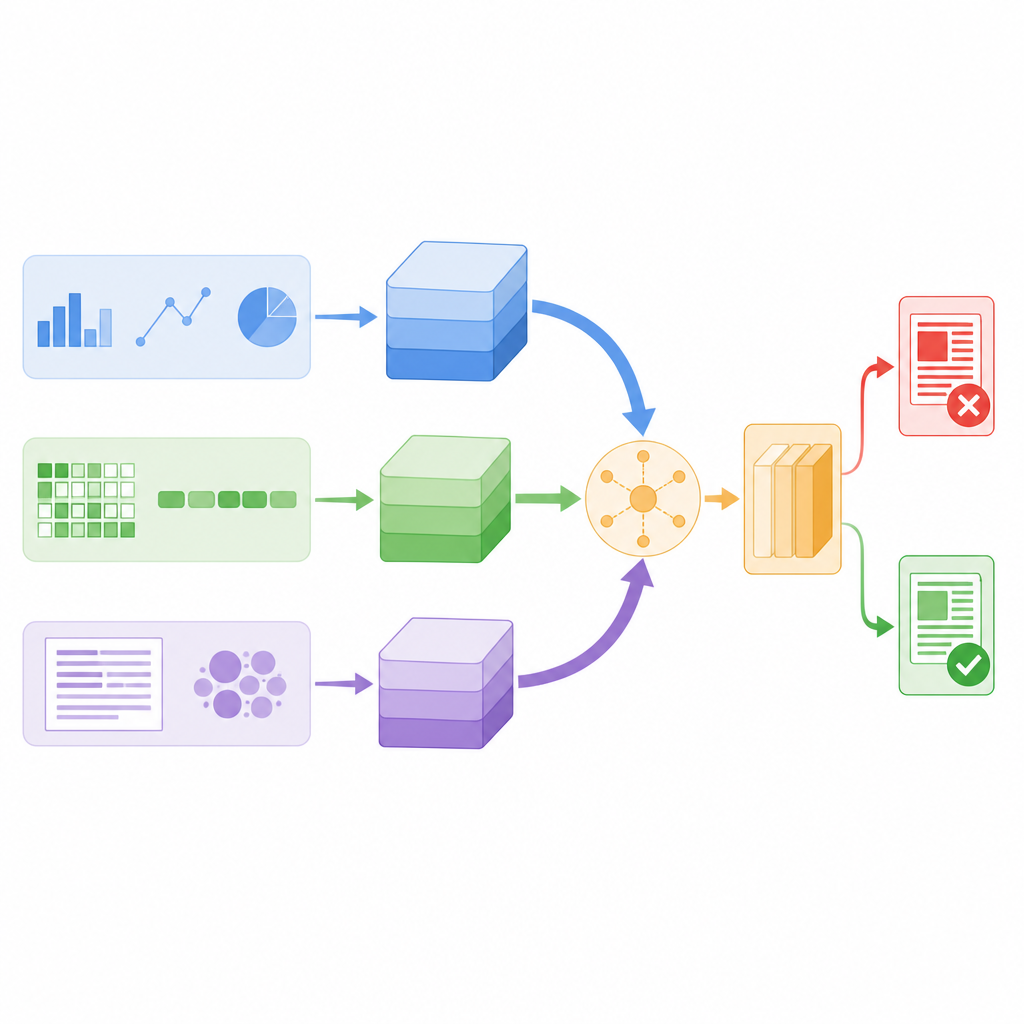
Laisser le système choisir ce qu’il faut privilégier
Plutôt que d’empiler simplement tous ces résumés, le modèle utilise un mécanisme appelé self-attention pour les pondérer différemment selon chaque histoire. Concrètement, cela signifie que le système apprend quand s’appuyer davantage sur le comportement des utilisateurs, quand se concentrer sur le sens des mots, et quand exploiter les motifs au niveau des caractères. Par exemple, si un message semble linguistiquement normal mais se propage selon un schéma de partage suspect, la branche comportementale peut peser plus lourd. Les trois branches échangent des informations via des scores d’attention puis sont moyennées en un vecteur de décision unique, qui alimente un classificateur final étiquetant la nouvelle comme vraie ou fausse. Cette architecture maintient le nombre total de paramètres du modèle relativement bas, le rendant suffisamment rapide pour une surveillance en temps réel.
Quelle est son efficacité sur des données réelles de réseaux sociaux
L’équipe a testé son approche sur deux collections Twitter largement utilisées. L’une, appelée GossipCop, couvre les rumeurs people ; l’autre, PolitiFact, contient des affirmations politiques. Sur les deux jeux, le modèle a largement surpassé les méthodes antérieures qui n’utilisaient que le texte, que le comportement, ou de simples combinaisons des deux. Sur GossipCop il a correctement étiqueté environ 99 % des éléments, et sur l’ensemble plus difficile PolitiFact il a atteint environ 96 % de précision. Il a aussi résisté à des tests plus exigeants, comme l’ajout de fautes de frappe de type clavier au texte ou l’évaluation par un modèle entraîné sur des nouvelles people de messages politiques. Dans ces cas, les indices au niveau des caractères et le signal comportemental ont contribué à préserver une grande partie de la performance lorsque les modèles basés sur les mots seuls faiblissaient.
Ce que cela signifie pour les lecteurs au quotidien
L’étude montre qu’une détection fiable des fausses informations doit prêter attention non seulement au contenu d’un récit, mais aussi à la manière dont il est rédigé et à la façon dont il circule dans un réseau social. En combinant ces vues et en laissant le système adapter leur importance au cas par cas, le modèle proposé peut signaler les publications suspectes avec une forte confiance tout en restant suffisamment léger pour être déployé sur des plateformes en direct. Pour les utilisateurs ordinaires, cela ne remplace pas une lecture attentive ni la vérification humaine des faits, mais cela peut servir de couche d’alerte précoce qui ralentit la diffusion d’histoires trompeuses avant qu’elles n’atteignent de larges audiences.
Citation: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Mots-clés: fausses informations, réseaux sociaux, désinformation, apprentissage profond, analyse multimodale