Clear Sky Science · sv
Att förena icke-textrika ledtrådar med klassisk NLP för förbättrad upptäckt av multimodalt spridd falsk information
Varför det blir svårare att upptäcka falska nyheter
Våra dagliga nyheter når oss nu via telefoner och sociala flöden, där sanna och falska berättelser färdas sida vid sida i hög hastighet. Många falska inlägg ser och låter precis som riktig journalistik, vilket gör dem svåra att fånga med verktyg som bara läser orden. I denna studie presenteras ett nytt sätt för datorer att bedöma onlineberättelser genom att inte bara läsa texten, utan också observera hur människor delar den och hur själva skrivandet är uppbyggt, med målet att flagga desinformation mer noggrant och snabbare.
Att se bortom orden på skärmen
De flesta tidigare detektorer för falska nyheter fokuserade på en enda informationskälla, vanligtvis artikeltexten. De räknade ordfrekvenser, analyserade skrivstil eller använde moderna språkmodeller för att förstå betydelsen. Dessa system fungerar väl i enkla fall, men får problem när falska berättelser noggrant imiterar tonen och vokabulären hos betrodda källor. Andra forskare började lägga till extra signaler från sociala medier, såsom hur ofta ett inlägg delas eller vem som delar det, men de fogade ofta bara samman dessa signaler utan att fråga vilka som spelar störst roll för varje berättelse. Den nya studien hävdar att både innehållet och sättet det sprids på bär på ledtrådar, och att ett flexibelt system måste avgöra i farten vilka ledtrådar som är mest pålitliga.
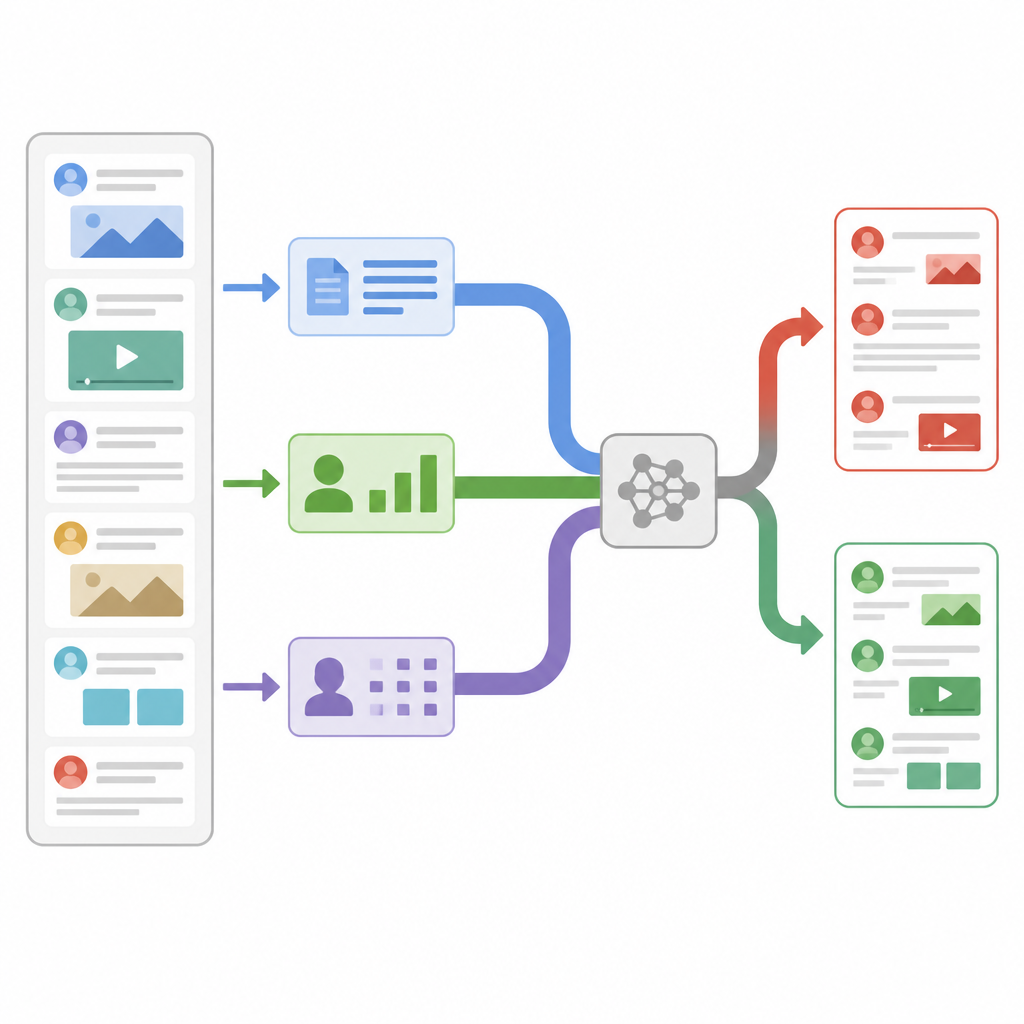
Tre slags ledtrådar från varje nyhetspost
Forskarna utformade en modell som granskar varje nyhetspost genom tre olika linser samtidigt. För det första beräknar den konstruerade statistik om texten och om kontot som publicerade den, såsom hur ofta följare återpostar eller kommenterar, när meddelandet skickades och hur mycket interpunktion eller hashtags som används. För det andra zoomar den in till individuell teckennivå och delar ord i korta teckenkedjor så att den fortfarande kan känna igen mönster när folk använder slang, kreativ stavning eller avsiktliga felstavningar. För det tredje undersöker den ordens betydelse genom att omvandla varje ord till en numerisk vektor som fångar hur det används i vardagligt språk. Varje lins omvandlar sina fynd till en kompakt sammanfattning med hjälp av sitt eget lilla neurala nätverk, så att brusigt detaljinnehåll filtreras bort innan ledtrådarna kombineras.
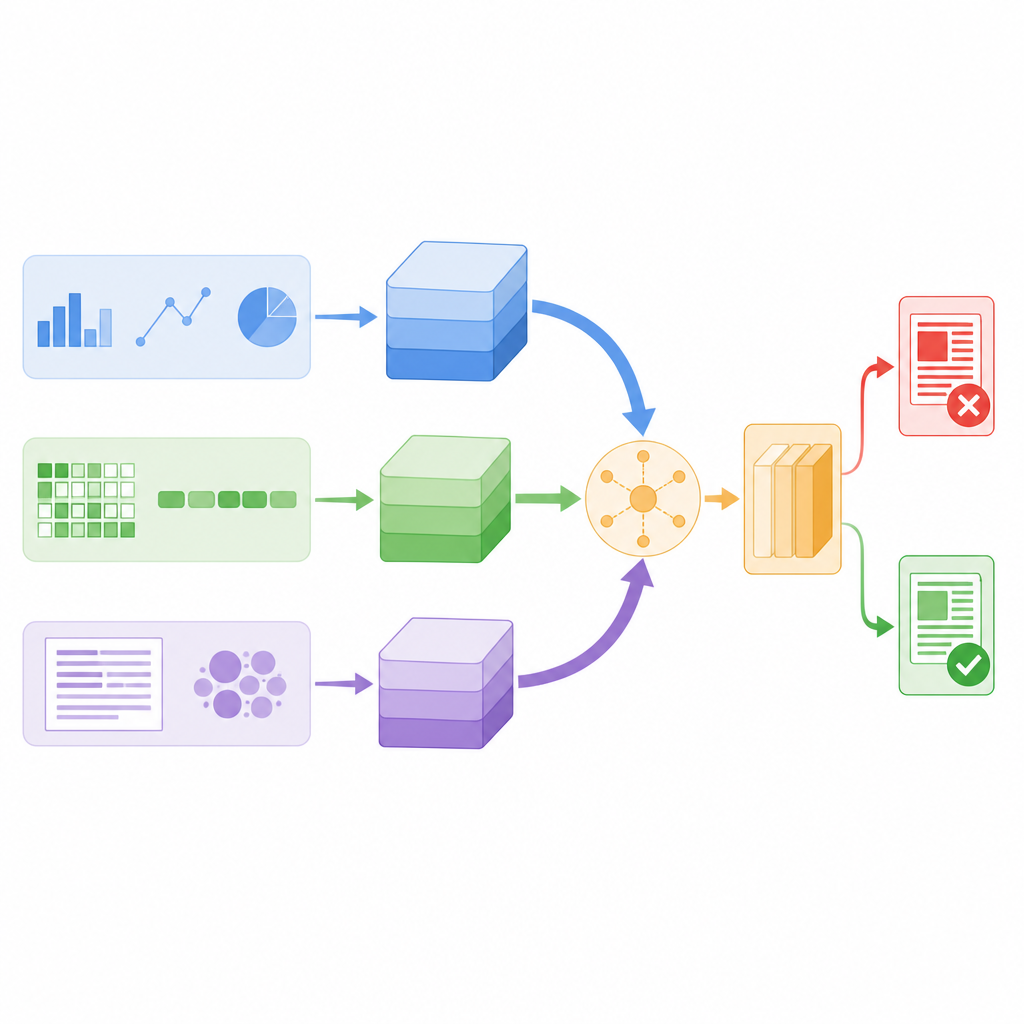
Låta systemet välja vad som är pålitligt
I stället för att bara stapla ihop alla dessa sammanfattningar använder modellen en mekanism kallad självuppmärksamhet för att väga dem olika för varje berättelse. I praktiken innebär detta att systemet lär sig när det ska förlita sig mer på användarbeteende, när det ska fokusera på ordens betydelse och när det ska lita på teckenmönster. Om ett inlägg till exempel ser språkligt normalt ut men sprids via ett misstänkt delningsmönster kan beteendeflödet få större vikt. Alla tre grenar utbyter information genom uppmärksamhetspoäng och genomsnittas sedan till en enda beslutsvektor, som matar en slutlig klassificerare som märker nyheten som verklig eller falsk. Denna konstruktion håller antalet modellparametrar relativt lågt, vilket gör den tillräckligt snabb för övervakning i realtid.
Hur bra fungerar det på verkliga sociala mediedata
Teamet testade sin metod på två vida använda Twitter-baserade samlingar. Den ena, kallad GossipCop, täcker underhållningsrykten; den andra, PolitiFact, innehåller politiska påståenden. I båda uppsättningarna överträffade modellen kraftigt tidigare metoder som bara använde text, endast beteende eller enkla kombinationer av båda. På GossipCop klassificerade den korrekt omkring 99 procent av objekten, och på den svårare PolitiFact-uppsättningen nådde den cirka 96 procents noggrannhet. Den höll sig också under tuffare tester, såsom att lägga till tangentbordsliknande felstavningar i texten eller att låta modellen som tränats på kändisnyheter bedöma politiska inlägg. I dessa fall hjälpte teckennivå- och beteendeflaggorna till att bevara mycket av prestandan när enbart ordbaserade modeller brast.
Vad detta betyder för vardagliga nyhetsläsare
Studien visar att tillförlitlig upptäckt av falska nyheter måste uppmärksamma inte bara vad en berättelse säger, utan också hur den är skriven och hur den rör sig genom ett socialt nätverk. Genom att blanda dessa perspektiv och låta systemet anpassa deras betydelse från fall till fall kan den föreslagna modellen flagga misstänkta inlägg med hög säkerhet samtidigt som den förblir tillräckligt lättviktig för att användas i liveplattformar. För vanliga användare ersätter detta inte noggrant läsande eller mänsklig faktagranskning, men det kan fungera som ett tidigt varningslager som bromsar spridningen av vilseledande berättelser innan de når stora publiker.
Citering: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Nyckelord: falska nyheter, sociala medier, desinformation, djupinlärning, multimodal analys