Clear Sky Science · pl
Łączenie wskazówek nietekstowych z klasycznym NLP dla lepszego wykrywania rozprzestrzeniania się fałszywych informacji w multimodalnych danych
Dlaczego wykrywanie fake newsów staje się trudniejsze
Nasz codzienny dostęp do wiadomości odbywa się dziś przez telefony i kanały społecznościowe, gdzie prawdziwe i fałszywe historie przemieszczają się równolegle z dużą prędkością. Wiele fałszywych postów wygląda i brzmi jak prawdziwe dziennikarstwo, co utrudnia ich wykrycie narzędziom opierającym się wyłącznie na analizie słów. W badaniu przedstawiono nowe podejście, które pozwala komputerom oceniać treści online nie tylko przez czytanie tekstu, lecz także przez obserwację sposobu, w jaki ludzie go udostępniają, oraz cech samego stylu pisma, z celem bardziej dokładnego i szybszego wykrywania dezinformacji.
Patrzeć poza słowa na ekranie
Większość wcześniejszych detektorów fałszywych informacji koncentrowała się na jednym źródle danych, zazwyczaj na tekście artykułu. Zliczano częstość słów, analizowano styl pisania lub wykorzystywano nowoczesne modele językowe do uchwycenia znaczenia. Systemy te radzą sobie dobrze w prostych przypadkach, ale mają trudności, gdy fałszywe historie starannie naśladują ton i słownictwo zaufanych źródeł. Inni badacze zaczęli dodawać sygnały z mediów społecznościowych, takie jak częstotliwość udostępnień lub to, kto je publikuje, jednak zwykle jedynie łączyli te sygnały bez zastanowienia, które z nich są najważniejsze dla konkretnej historii. Nowe badanie argumentuje, że zarówno treść, jak i sposób jej rozprzestrzeniania niosą wskazówki, i że elastyczny system musi na bieżąco decydować, którym wskazówkom ufać bardziej.
Trzy rodzaje wskazówek dla każdego wpisu
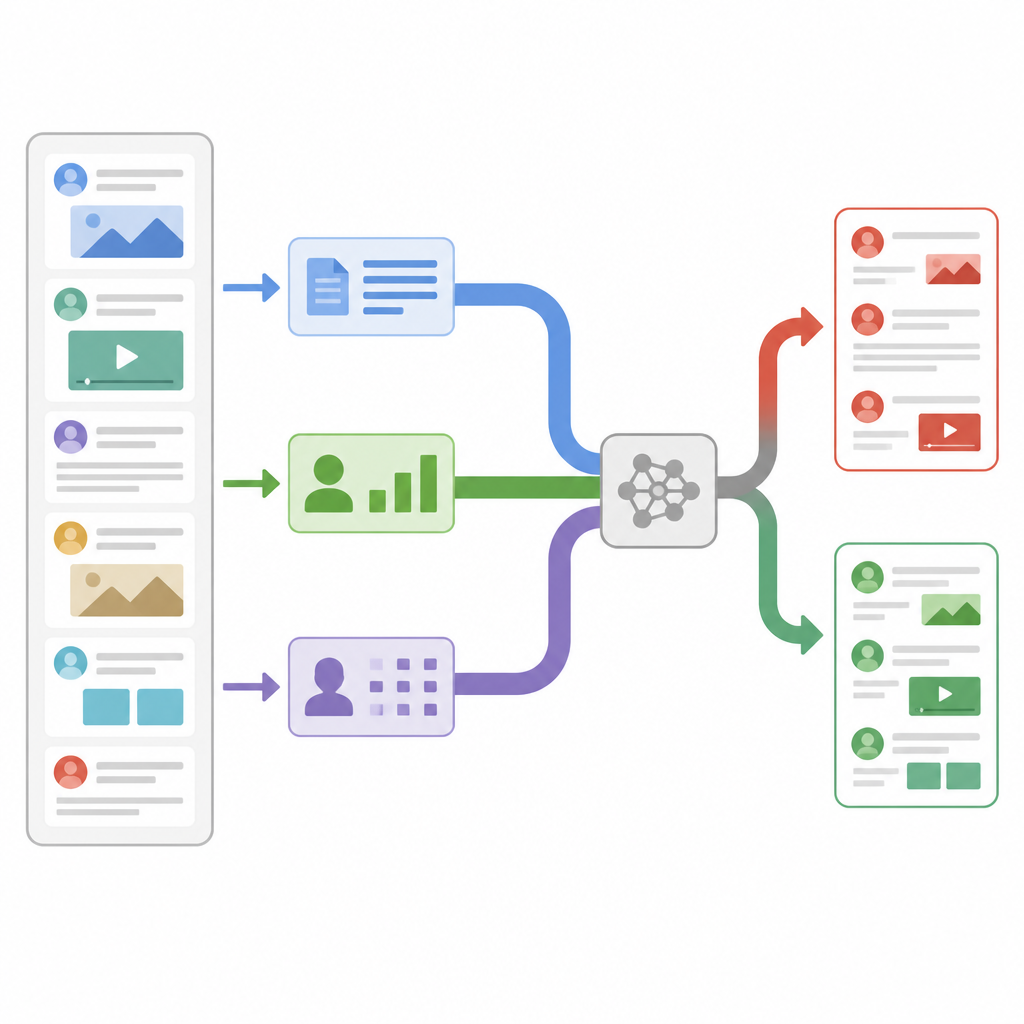
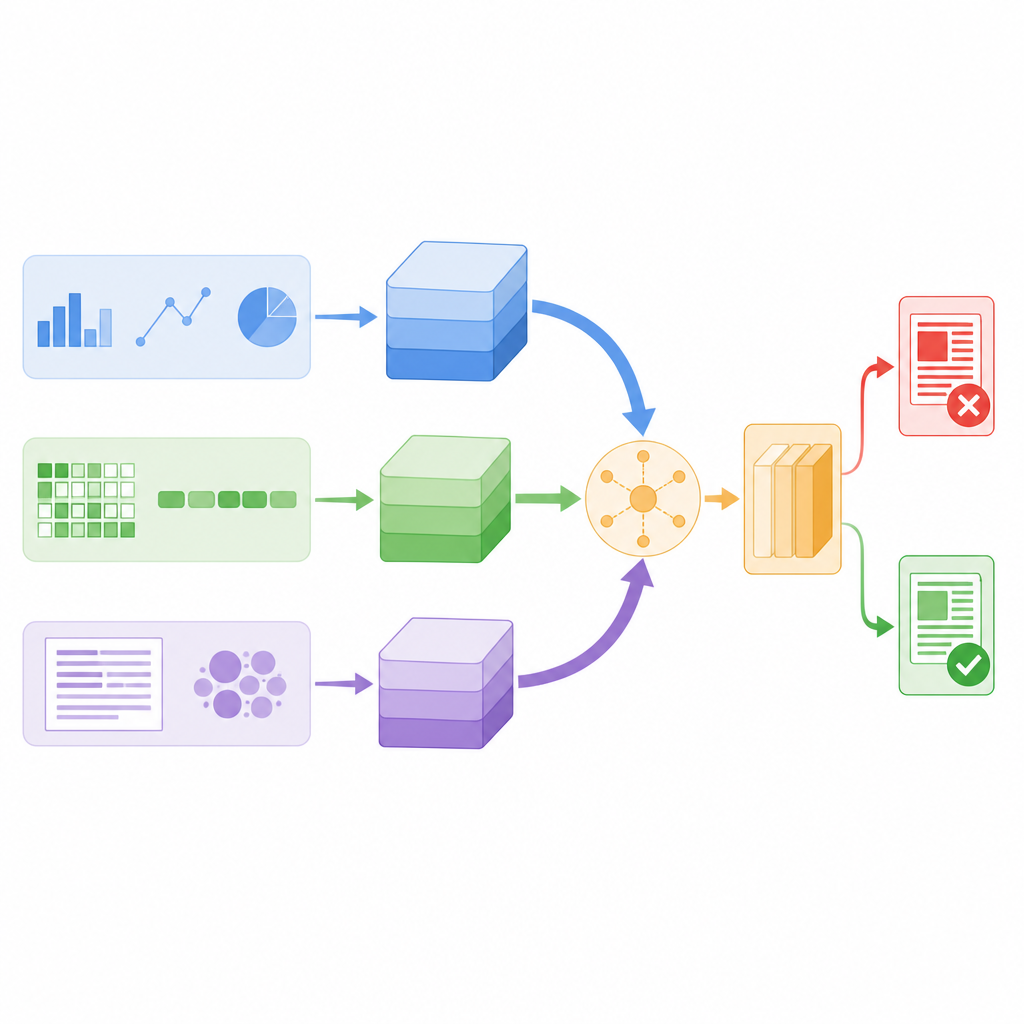
Badacze zaprojektowali model, który jednocześnie analizuje każdy post przez trzy różne soczewki. Po pierwsze, oblicza zaprojektowane statystyki dotyczące tekstu i konta, które go opublikowało, takie jak częstość repostów czy komentarzy przez obserwujących, czas wysłania wiadomości oraz intensywność użycia interpunkcji czy hashtagów. Po drugie, przygląda się poziomowi pojedynczych znaków, rozbijając słowa na krótkie ciągi znaków, dzięki czemu potrafi rozpoznawać wzorce, gdy użytkownicy stosują slangi, kreatywne pisownie lub celowe literówki. Po trzecie, analizuje znaczenie słów, zamieniając każde słowo na wektor liczbowy, który odzwierciedla jego użycie w codziennym języku. Każda z tych perspektyw zamienia swoje ustalenia w zwięzłe podsumowanie za pomocą własnej małej sieci neuronowej, tak aby odfiltrować szumy przed połączeniem wskazówek.
Pozwolić systemowi wybrać, czemu ufać
Zamiast po prostu składać wszystkie podsumowania razem, model wykorzystuje mechanizm zwany self-attention, aby różnie je ważyć dla każdej historii. W praktyce oznacza to, że system uczy się, kiedy bardziej polegać na zachowaniu użytkowników, kiedy skupić się na znaczeniu słów, a kiedy zaufać wzorcom na poziomie znaków. Na przykład, jeśli post językowo wygląda normalnie, ale rozprzestrzenia się w podejrzany sposób, gałąź behawioralna może zyskać większą wagę. Wszystkie trzy gałęzie wymieniają się informacjami przez wyniki uwagi, a następnie uśredniane są do pojedynczego wektora decyzyjnego, który zasila końcowy klasyfikator oznaczający wiadomość jako prawdziwą lub fałszywą. Taka konstrukcja utrzymuje względnie niewielką liczbę parametrów modelu, co sprawia, że jest wystarczająco szybki do monitoringu w czasie rzeczywistym.
Jak to działa na rzeczywistych danych z mediów społecznościowych
Zespół przetestował swoje podejście na dwóch szeroko stosowanych zestawach opartych na Twitterze. Jeden, zwany GossipCop, obejmuje plotki z branży rozrywkowej; drugi, PolitiFact, zawiera tezy polityczne. W obu zbiorach model znacznie przewyższał wcześniejsze metody używające wyłącznie tekstu, wyłącznie zachowania lub prostych kombinacji obu. W zbiorze GossipCop poprawnie oznaczył około 99 procent wpisów, a w trudniejszym zbiorze PolitiFact osiągnął około 96 procent dokładności. Wytrzymał też trudniejsze testy, takie jak dodawanie literówek imitujących pisanie na klawiaturze czy proszenie modelu wytrenowanego na wiadomościach o celebrytach o ocenę postów politycznych. W tych przypadkach wskazówki na poziomie znaków i behawioralne pomogły zachować dużą część wydajności, gdy modele oparte tylko na słowach zawodziły.
Co to oznacza dla przeciętnych czytelników wiadomości
Badanie pokazuje, że wiarygodne wykrywanie fałszywych informacji musi zwracać uwagę nie tylko na to, co mówi historia, lecz także na to, jak jest napisana i jak porusza się w sieci społecznej. Poprzez połączenie tych perspektyw i umożliwienie systemowi dostosowywania ich wagi w każdym przypadku, proponowany model może z dużą pewnością sygnalizować podejrzane wpisy, pozostając jednocześnie na tyle lekki, by wdrożyć go na żywych platformach. Dla zwykłych użytkowników nie zastępuje to uważnego czytania ani ludzkiej weryfikacji faktów, ale może działać jako warstwa wczesnego ostrzegania, która spowalnia rozprzestrzenianie się wprowadzających w błąd historii zanim dotrą do szerokich odbiorców.
Cytowanie: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Słowa kluczowe: fake news, social media, misinformation, deep learning, multimodal analysis