Clear Sky Science · he
שילוב רמזים שאינם טקסטואליים עם NLP קלאסי לזיהוי מפושט של הפצת חדשות מזויפות
מדוע זיהוי חדשות מזויפות נעשה קשה יותר
החדשות היומיומיות שלנו מגיעות כיום דרך טלפונים ופידים חברתיים, שבהם סיפורים נכונים ושגויים מטיילים זה לצד זה במהירות רבה. פוסטים מזויפים רבים נראים ונשמעים בדיוק כמו עיתונאות אמיתית, מה שמקשה על כלי זיהוי שמתבססים רק על קריאת המילים. מחקר זה מציע שיטה חדשה למחשבים לשפוט סיפורים מקוונים לא רק על־פי הטקסט, אלא גם על־פי אופן השיתוף של אנשים ועל המבנה הכתיבתי של הכתיבה, במטרה לסמן מידע מטעה בדיוק ובמהירות גדולים יותר.
מסתכלים מעבר למילים על המסך
רוב גלאי החדשות המזויפות הקודמים התמקדו במקור מידע יחיד, בדרך כלל טקסט המאמר. הם ספזו תדירויות מילים, בחנו סגנון כתיבה או השתמשו במודלים לשוניים מודרניים כדי להבין משמעות. מערכות אלה עובדות היטב במקרים פשוטים, אך מתקשות כאשר סיפורים מזויפים מחקים בקפידה את הטון והאוצר המילים של מקורות מהימנים. חוקרים אחרים החלו להוסיף איתותים חברתיים נוספים, כגון תדירות השיתוף או זהות השותפים לשיתוף, אך בדרך כלל הם פשוט חיברו את כל האיתותים הללו מבלי לשאול אילו מהם חשובים יותר לכל סיפור. המחקר החדש טוען כי גם התוכן וגם אופן ההפצה נושאים רמזים, ומערכת גמישה חייבת להחליט בזמן אמת אילו רמזים כדאי לסמוך עליהם יותר.
שלושה סוגי רמזים מכל פריט חדשות
החוקרים תכננו מודל הבוחן כל פוסט חדשות דרך שלוש עדשות שונות בו־זמנית. ראשית, הוא מחשב סטטיסטיקות מהונדסות על הטקסט ועל החשבון שפרסם אותו, כגון תדירות שבה העוקבים משחזרים או מגיבים, מתי נשלח המסר וכמה נעשה שימוש בסימני פיסוק או בהאשתגים. שנית, הוא מתמקד ברמת התווים הבודדים, מפצל מילים לשרשראות תווים קצakata כדי לזהות דפוסים גם כשאנשים משתמשים בסלנג, איות יצירתי או שגיאות מכוונות. שלישית, הוא בוחן משמעות מילים, מהופך כל מילה לוקטור מספרי הלוכד את ההקשר והשימוש היומיומי שלה. כל עדשה ממקצרת את הממצאים לסיכום קומפקטי באמצעות רשת עצבית קטנה משלה, כך שפרטים רועשים מסוננים לפני שילוב הרמזים.
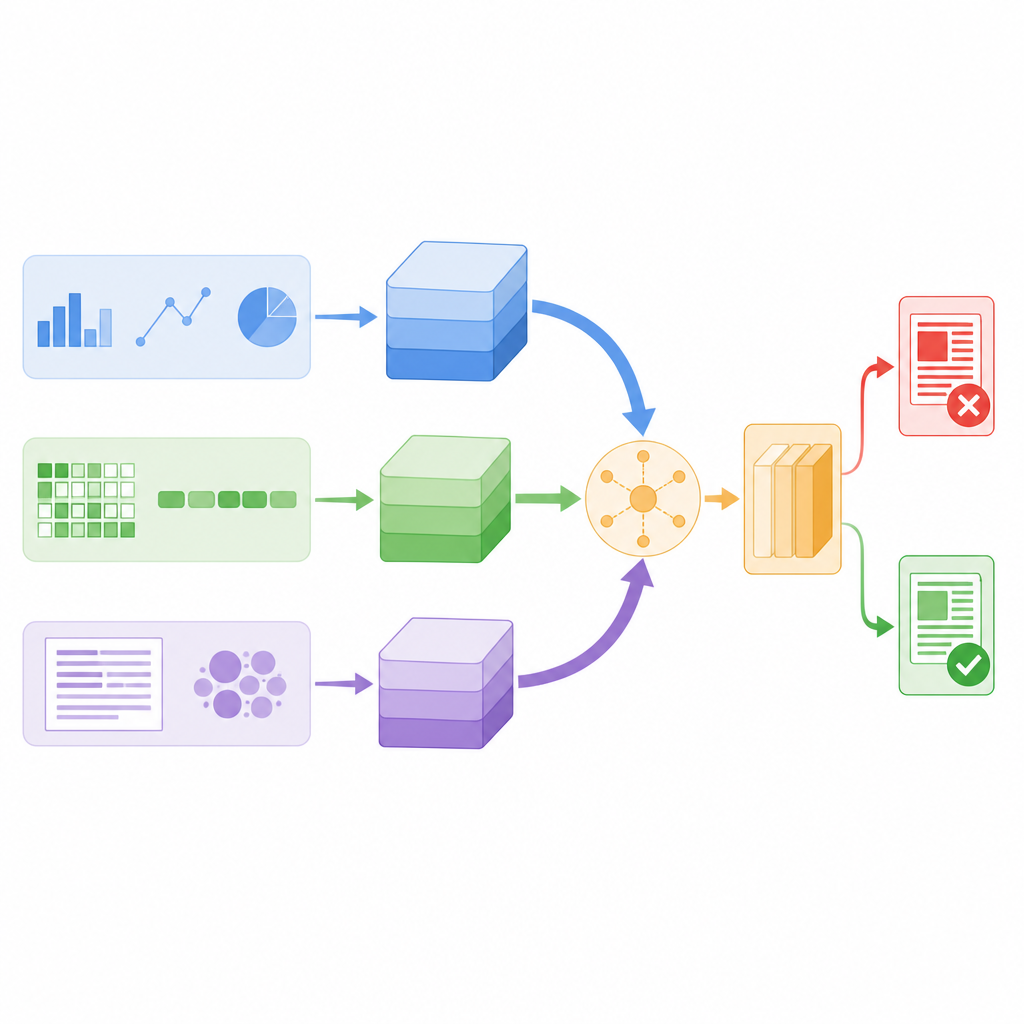
מאפשרים למערכת לבחור במה להאמין
במקום פשוט לערום את כל הסיכומים האלה זה על גבי זה, המודל משתמש במנגנון שנקרא תשומת לב עצמית כדי לשקול אותם באופן שונה לכל סיפור. למעשה, זה אומר שהמערכת לומדת מתי להישען יותר על התנהגות משתמשים, מתי להתמקד במשמעות המילים ומתי להסתמך על דפוסי תווים. למשל, אם פוסט נראה תקין לשונית אך מתפשט בדפוס שיתופים חשוד, הזרוע ההתנהגותית יכולה לתפוס משקל רב יותר. שלוש הזרועות מחליפות מידע באמצעות ציוני תשומת לב ואז ממוצעות לווקטור החלטה יחיד, שמזין מסווג סופי המתייג את החדשות כאמיתיות או מזויפות. העיצוב הזה שומר על מספר פרמטרים נמוך יחסית, מה שהופך אותו למהיר מספיק לניטור בזמן אמת.
כמה טוב זה עובד על נתונים אמיתיים מהרשתות החברתיות
הצוות בחן את הגישה בשני מאגרים מבוססי טוויטר שמשמשים באופן נרחב. האחד, שנקרא GossipCop, מכסה שמועות בידור; השני, PolitiFact, מכיל טענות פוליטיות. בשני המאגרים המודל השיג ביצועים גבוהים בהרבה משיטות קודמות שהשתמשו רק בטקסט, רק בהתנהגות או בשילובים פשוטים של השניים. ב־GossipCop הוא סיווג נכון כ־99 אחוזים מהפריטים, ובמערכת הקשה יותר PolitiFact הגיע לכ־96 אחוז דיוק. הוא גם עמד במבחנים קשים יותר, כמו הוספת שגיאות הקלדה בסגנון מקלדת לטקסט או שאלת המודל שאומן על חדשות סלבריטאים לשפוט פוסטים פוליטיים. במקרים אלה, הרמזים ברמת התווים ובהתנהגות עזרו לשמר חלק ניכר מהביצועים כאשר מודלים המבוססים אך ורק על מילים קרסו.
מה זה אומר לקוראי חדשות יומיומיים
המחקר מראה שזיהוי חדשות מזויפות אמין חייב לשים לב לא רק למה שסיפור אומר, אלא גם לאופן כתיבתו ולאופן שבו הוא נע ברשת חברתית. על ידי שילוב נקודות מבט אלה ומתן אפשרות למערכת להתאים את חשיבותן מקרה־מקרה, המודל המוצע יכול לסמן פוסטים חשודים בביטחון גבוה תוך שמירה על קלילות מספקת לפריסה בפלטפורמות חיות. עבור משתמשים רגילים, זה לא מחליף קריאה זהירה או בדיקת עובדות של בני אדם, אך יכול לשמש כשכבת התרעה מוקדמת שמאטה את התפשטות סיפורים מטעה לפני שיגיעו לקהלים גדולים.
ציטוט: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
מילות מפתח: חדשות מזויפות, רשתות חברתיות, מידע מטעה, למידה עמוקה, ניתוח מולטימודלי