Clear Sky Science · es
Fusionar señales no textuales con PLN clásico para mejorar la detección multimodal de propagación de noticias falsas
Por qué detectar noticias falsas se está volviendo más difícil
Nuestras noticias diarias llegan ahora a través de teléfonos y feeds sociales, donde historias verdaderas y falsas circulan juntas a gran velocidad. Muchas publicaciones falsas se parecen y suenan igual que el periodismo real, lo que las hace difíciles de atrapar con herramientas que solo leen las palabras. Este estudio presenta una nueva forma para que los ordenadores juzguen las historias en línea no solo leyendo el texto, sino también observando cómo la gente las comparte y cómo está construido el propio escrito, con el objetivo de señalar la desinformación de forma más precisa y rápida.
Mirar más allá de las palabras en la pantalla
La mayoría de los detectores anteriores de noticias falsas se centraron en una única fuente de información, normalmente el texto del artículo. Contaban frecuencias de palabras, analizaban el estilo de escritura o usaban modelos de lenguaje modernos para entender el significado. Estos sistemas funcionan bien en casos simples, pero tienen dificultades cuando las historias falsas imitan cuidadosamente el tono y el vocabulario de medios de confianza. Otros investigadores empezaron a añadir señales extra de redes sociales, como la frecuencia de compartidos o quiénes las comparten, pero por lo general solo pegaban todas esas señales sin preguntar cuáles importan más en cada historia. El nuevo estudio sostiene que tanto el contenido como la forma en que se difunde contienen pistas, y que un sistema flexible debe decidir sobre la marcha en cuáles pistas confiar más.
Tres tipos de pistas de cada noticia
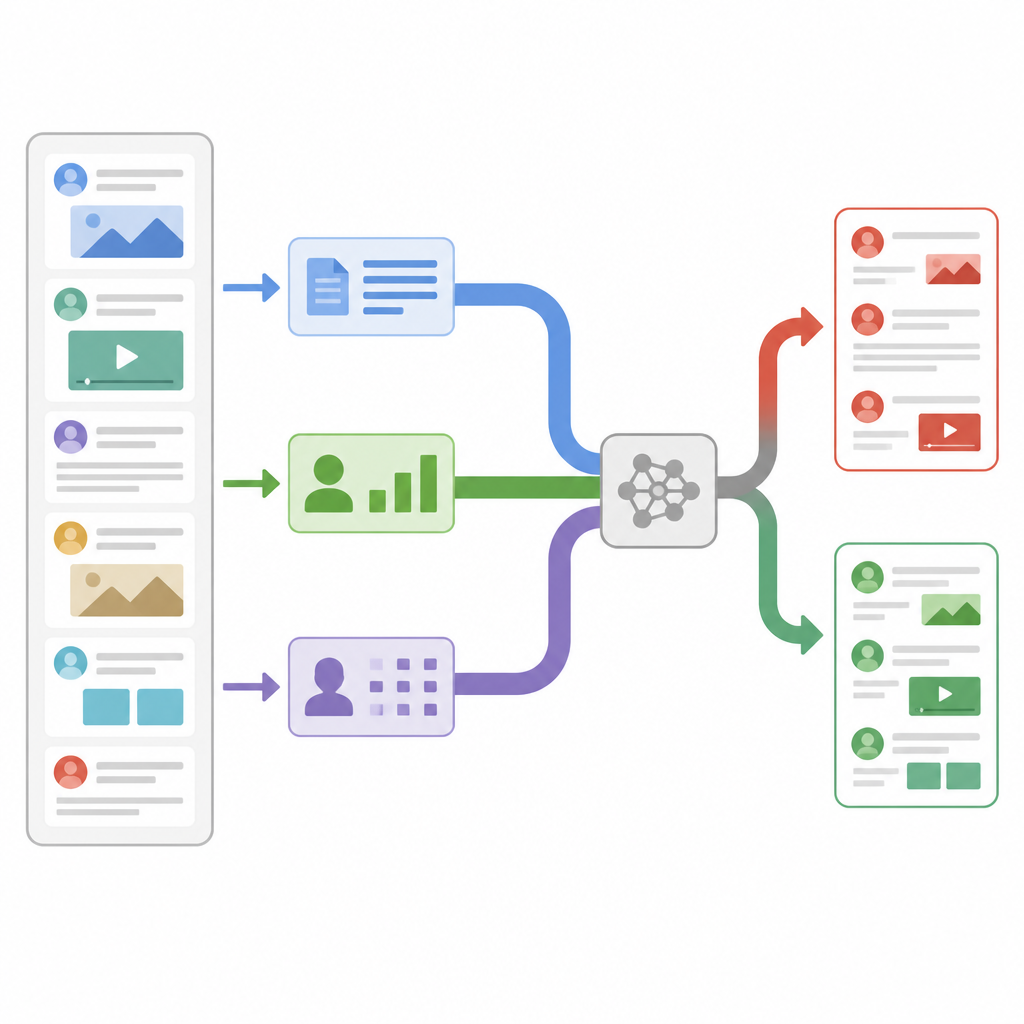
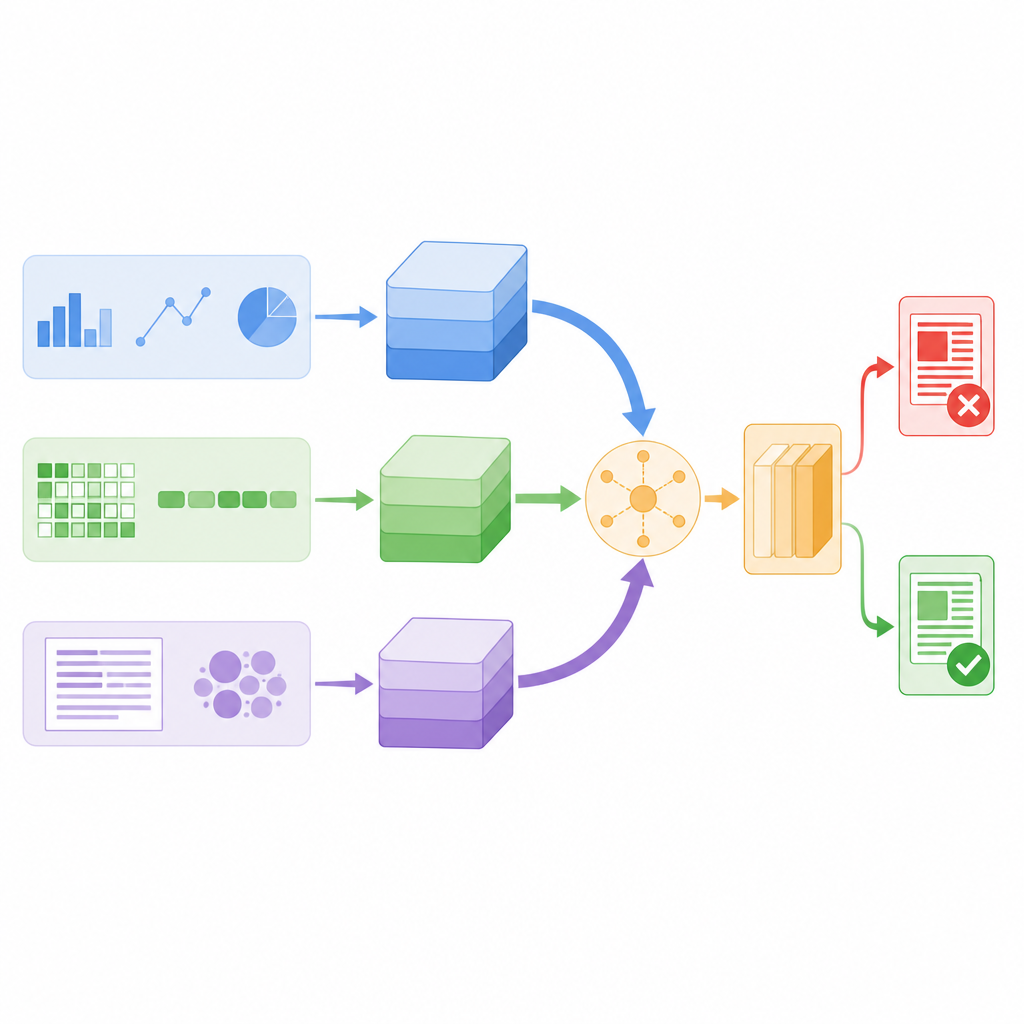
Los investigadores diseñaron un modelo que examina cada publicación de noticias a través de tres lentes diferentes al mismo tiempo. Primero, calcula estadísticas diseñadas sobre el texto y sobre la cuenta que la publicó, como la frecuencia con que los seguidores vuelven a publicar o comentan, cuándo se envió el mensaje y cuánto usa puntuación o hashtags. Segundo, se acerca al nivel de caracteres individuales, descomponiendo palabras en cadenas cortas de caracteres para poder reconocer patrones cuando las personas usan jerga, ortografías creativas o errores tipográficos deliberados. Tercero, analiza el significado de las palabras, convirtiendo cada palabra en un vector numérico que captura cómo se usa en el lenguaje cotidiano. Cada lente convierte sus hallazgos en un resumen compacto usando su propia pequeña red neuronal, de modo que los detalles ruidosos se filtran antes de combinar las pistas.
Dejar que el sistema elija en qué confiar
En lugar de simplemente apilar todos estos resúmenes, el modelo usa un mecanismo llamado autoatención para ponderarlos de forma distinta en cada historia. En la práctica, esto significa que el sistema aprende cuándo apoyarse más en el comportamiento de los usuarios, cuándo centrarse en el significado de las palabras y cuándo depender de los patrones de caracteres. Por ejemplo, si una publicación parece lingüísticamente normal pero se difunde con un patrón de compartidos sospechoso, la rama de comportamiento puede tener más peso. Las tres ramas intercambian información mediante puntuaciones de atención y luego se promedian en un único vector de decisión, que alimenta un clasificador final que etiqueta la noticia como real o falsa. Este diseño mantiene el número total de parámetros del modelo relativamente bajo, lo que lo hace lo suficientemente rápido para la monitorización en tiempo real.
Qué tan bien funciona en datos reales de redes sociales
El equipo probó su enfoque en dos colecciones de Twitter ampliamente usadas. Una, llamada GossipCop, cubre rumores del entretenimiento; la otra, PolitiFact, contiene afirmaciones políticas. En ambos conjuntos, el modelo superó con creces a métodos anteriores que usaban solo texto, solo comportamiento o combinaciones simples de ambos. En GossipCop etiquetó correctamente alrededor del 99 por ciento de los ítems, y en el más difícil conjunto PolitiFact alcanzó cerca del 96 por ciento de precisión. También se comportó bien en pruebas más duras, como añadir errores tipográficos de tipo teclado al texto o pedir al modelo entrenado en noticias de celebridades que juzgue publicaciones políticas. En esos casos, las pistas a nivel de caracteres y las conductuales ayudaron a preservar gran parte del rendimiento cuando los modelos basados solo en palabras fallaban.
Qué significa esto para los lectores cotidianos
El estudio muestra que una detección fiable de noticias falsas debe prestar atención no solo a lo que dice una historia, sino también a cómo está escrita y cómo se mueve por una red social. Al combinar estas perspectivas y permitir que el sistema adapte su importancia caso por caso, el modelo propuesto puede señalar publicaciones sospechosas con alta confianza y a la vez ser lo bastante ligero para desplegarse en plataformas en directo. Para los usuarios corrientes, esto no reemplaza la lectura atenta ni la verificación humana de hechos, pero podría actuar como una capa de aviso temprana que ralentice la difusión de historias engañosas antes de que alcancen a grandes audiencias.
Cita: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Palabras clave: noticias falsas, redes sociales, desinformación, aprendizaje profundo, análisis multimodal