Clear Sky Science · nl
Het combineren van niet-tekstuele signalen met klassieke NLP voor verbeterde detectie van multimodale verspreiding van nepnieuws
Waarom het opsporen van nepnieuws moeilijker wordt
Ons dagelijkse nieuws komt nu binnen via telefoons en social feeds, waar waarheidsgetrouwe en valse verhalen zij aan zij en met hoge snelheid circuleren. Veel nepberichten zien eruit en klinken net als echte journalistiek, wat ze lastig te onderscheppen maakt met tools die alleen de woorden lezen. Deze studie presenteert een nieuwe manier voor computers om online verhalen te beoordelen door niet alleen de tekst te lezen, maar ook te observeren hoe mensen het delen en hoe het schrijven zelf is opgebouwd, met als doel misinformatie nauwkeuriger en sneller te signaleren.
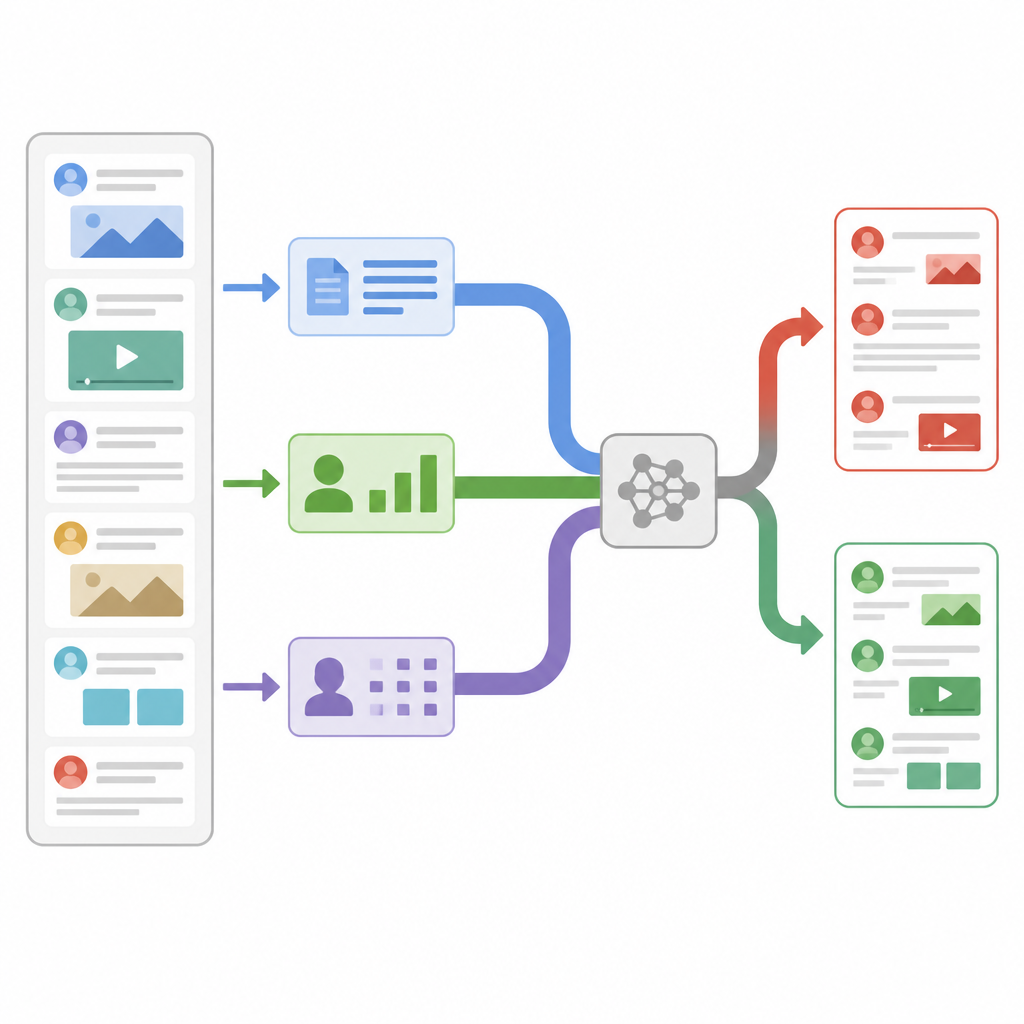
Kijk verder dan de woorden op het scherm
De meeste eerdere nepnieuwsdetectoren richtten zich op één informatiebron, doorgaans de artikeltekst. Ze telden woordfrequenties, keken naar schrijfstijl of gebruikten moderne taalmodellen om betekenis vast te stellen. Deze systemen presteren goed in eenvoudige gevallen, maar hebben moeite wanneer nepverhalen de toon en woordenschat van betrouwbare media zorgvuldig nabootsen. Andere onderzoekers voegden extra signalen uit sociale media toe, zoals hoe vaak een bericht gedeeld wordt of wie het deelt, maar die combineren die signalen meestal gewoon zonder te onderzoeken welke voor elk verhaal het belangrijkst zijn. De nieuwe studie stelt dat zowel de inhoud als de manier van verspreiding aanwijzingen bevatten, en dat een flexibel systeem ter plekke moet beslissen welke aanwijzingen meer vertrouwen verdienen.
Drie soorten aanwijzingen per nieuwsitem
De onderzoekers ontwierpen een model dat elk nieuwsbericht gelijktijdig door drie verschillende lenzen bekijkt. Ten eerste berekent het geconstrueerde statistieken over de tekst en over het account dat het plaatste, zoals hoe vaak volgers opnieuw plaatsen of reageren, wanneer het bericht is verstuurd en hoe intensief het gebruik van leestekens of hashtags is. Ten tweede zoomt het in op het niveau van individuele tekens, waarbij woorden worden opgesplitst in korte tekenreeksen zodat het patronen kan herkennen wanneer mensen slang, creatieve spelling of opzettelijke tikfouten gebruiken. Ten derde kijkt het naar woordbetekenis, waarbij elk woord wordt omgezet in een numerieke vector die vastlegt hoe het in alledaagse taal wordt gebruikt. Elke lens zet zijn bevindingen om in een compacte samenvatting met behulp van een eigen klein neuraal netwerk, zodat ruis wordt gefilterd voordat de aanwijzingen worden gecombineerd.
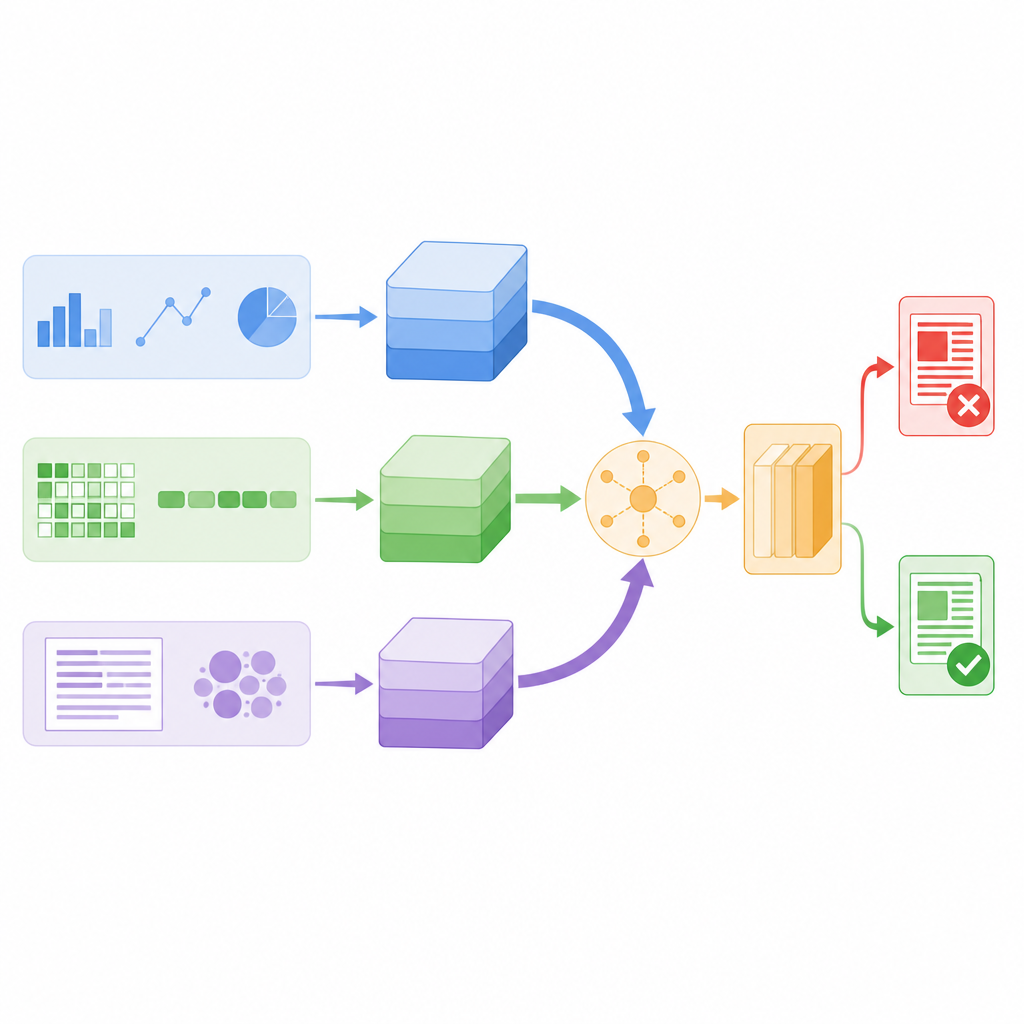
Het systeem laten kiezen wat betrouwbaar is
In plaats van al deze samenvattingen simpelweg op te stapelen, gebruikt het model een mechanisme dat self-attention heet om ze voor elk verhaal verschillend te wegen. In de praktijk betekent dit dat het systeem leert wanneer het meer moet leunen op gebruikersgedrag, wanneer het zich moet concentreren op woordbetekenis en wanneer het moet vertrouwen op tekenpatronen. Als een bericht bijvoorbeeld linguïstisch normaal lijkt maar via een verdachte deelstructuur circuleert, kan de gedragscomponent zwaarder wegen. Alle drie de takken wisselen informatie uit via attentiescores en worden vervolgens gemiddeld tot één beslissingsvector, die een uiteindelijke classifier voedt die het nieuws als echt of nep labelt. Dit ontwerp houdt het totale aantal modelparameters relatief laag, waardoor het snel genoeg is voor realtime monitoring.
Hoe goed werkt het op echte sociale-mediasets
Het team testte hun aanpak op twee veelgebruikte, Twitter-gebaseerde verzamelingen. De ene, GossipCop genaamd, bestrijkt entertainmentroddels; de andere, PolitiFact, bevat politieke beweringen. In beide datasets presteerde het model aanzienlijk beter dan eerdere methoden die alleen tekst, alleen gedrag of simpele combinaties van beide gebruikten. Op GossipCop labelde het ongeveer 99 procent van de items correct, en op de moeilijkere PolitiFact-set behaalde het circa 96 procent nauwkeurigheid. Het hield ook stand bij zwaardere tests, zoals het toevoegen van toetsenbordachtige typefouten aan de tekst of het vragen aan het op celebrity-nieuws getrainde model om politieke berichten te beoordelen. In die gevallen hielpen de teken-niveau en gedragsaanwijzingen een groot deel van de prestaties te behouden waar woordgebaseerde modellen alleen faalden.
Wat dit betekent voor alledaagse nieuwslezers
De studie laat zien dat betrouwbare detectie van nepnieuws niet alleen moet letten op wat een verhaal zegt, maar ook op hoe het geschreven is en hoe het zich door een sociaal netwerk beweegt. Door deze invalshoeken te mengen en het systeem hun belangrijkheid geval per geval te laten aanpassen, kan het voorgestelde model verdachte berichten met hoge zekerheid markeren en tegelijk lichtgewicht genoeg blijven om in live platforms te worden ingezet. Voor gewone gebruikers vervangt dit geen zorgvuldig lezen of menselijke factchecking, maar het kan fungeren als een vroeg waarschuwingssysteem dat de verspreiding van misleidende verhalen vertraagt voordat ze grote publieken bereiken.
Bronvermelding: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Trefwoorden: nepnieuws, sociale media, misinformatie, deep learning, multimodale analyse