Clear Sky Science · it
Fondere indizi non testuali con NLP classico per migliorare il rilevamento multimodale della diffusione di fake news
Perché individuare le fake news sta diventando più difficile
Le nostre notizie quotidiane arrivano ormai tramite telefoni e feed social, dove storie vere e false viaggiano fianco a fianco ad alta velocità. Molti post falsi somigliano e suonano proprio come il giornalismo reale, il che li rende difficili da catturare con strumenti che leggono solo le parole. Questo studio propone un nuovo modo per i computer di giudicare le storie online non solo leggendo il testo, ma anche osservando come le persone lo condividono e come è strutturata la scrittura stessa, con l'obiettivo di segnalare la disinformazione in modo più accurato e più rapido.
Guardare oltre le parole sullo schermo
La maggior parte dei precedenti rivelatori di fake news si è concentrata su una singola fonte di informazione, di solito il testo dell'articolo. Contavano le frequenze delle parole, analizzavano lo stile di scrittura o usavano modelli linguistici moderni per cogliere il significato. Questi sistemi funzionano bene nei casi semplici, ma faticano quando le storie false imitano accuratamente il tono e il vocabolario di fonti affidabili. Altri ricercatori hanno iniziato ad aggiungere segnali extra dai social media, come la frequenza di condivisione di un post o chi lo condivide, ma di solito hanno semplicemente aggregato tutti questi segnali senza chiedersi quali contano di più per ciascuna storia. Il nuovo studio sostiene che sia il contenuto sia il modo in cui si diffonde portano indizi, e che un sistema flessibile deve decidere al volo a quali indizi dare più fiducia.
Tre tipi di indizi per ogni notizia
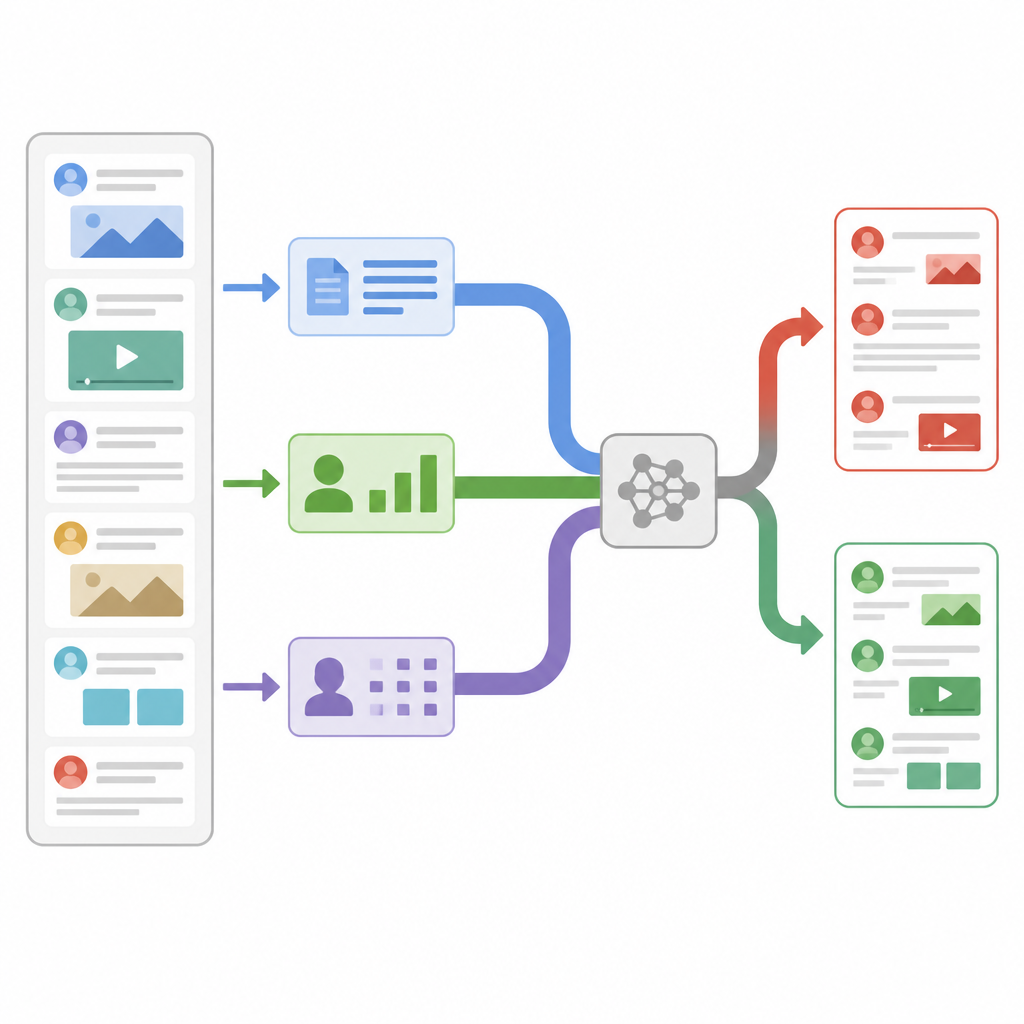
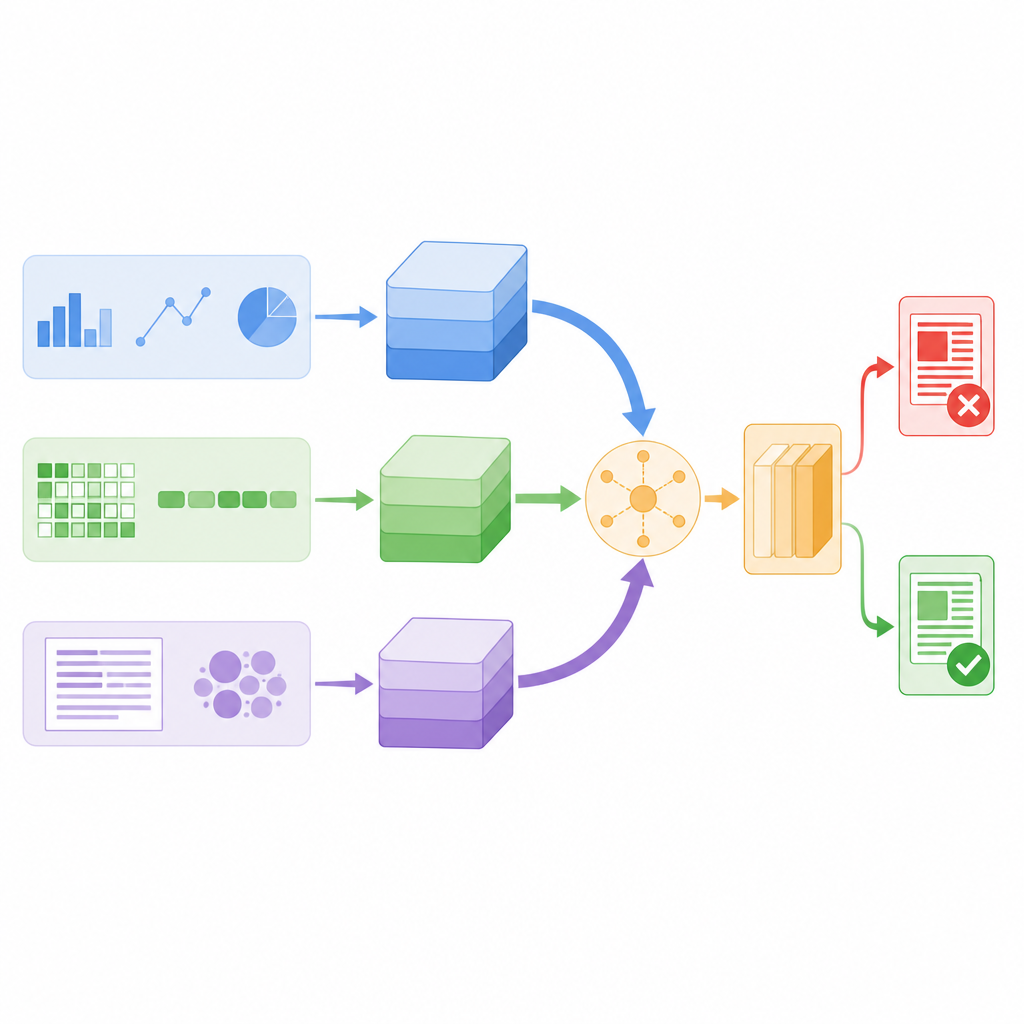
I ricercatori hanno progettato un modello che esamina ogni post di notizia attraverso tre lenti differenti simultaneamente. Primo, calcola statistiche ingegnerizzate sul testo e sull'account che lo ha pubblicato, come la frequenza con cui i follower ritrasmettono o commentano, quando il messaggio è stato inviato e quanto vengono usati punteggiatura o hashtag. Secondo, si concentra a livello di singoli caratteri, scomponendo le parole in brevi catene di caratteri così da riconoscere pattern anche quando le persone usano gergo, ortografie creative o errori intenzionali. Terzo, considera il significato delle parole, trasformando ogni parola in un vettore numerico che cattura il suo uso nel linguaggio quotidiano. Ogni lente converte i risultati in un riassunto compatto tramite una propria piccola rete neurale, in modo che i dettagli rumorosi vengano filtrati prima che gli indizi vengano combinati.
Lasciare che il sistema scelga cosa fidarsi
Invece di limitarsi a impilare tutti questi riassunti, il modello utilizza un meccanismo chiamato self-attention per pesarli diversamente per ogni storia. In pratica, questo significa che il sistema impara quando affidarsi maggiormente al comportamento degli utenti, quando concentrarsi sul significato delle parole e quando puntare sui pattern a livello di caratteri. Per esempio, se un post appare linguisticamente normale ma si diffonde con uno schema di condivisione sospetto, il ramo comportamentale può avere più peso. Tutti e tre i rami scambiano informazioni tramite punteggi di attenzione e vengono poi mediati in un unico vettore decisionale, che alimenta un classificatore finale che etichetta la notizia come vera o falsa. Questo progetto mantiene il numero totale di parametri del modello relativamente basso, rendendolo sufficientemente veloce per il monitoraggio in tempo reale.
Quanto funziona sui dati reali dei social media
Il team ha testato il loro approccio su due raccolte basate su Twitter ampiamente usate. Una, chiamata GossipCop, copre voci di intrattenimento; l'altra, PolitiFact, contiene affermazioni politiche. In entrambi i set, il modello ha superato di gran lunga i metodi precedenti che usavano solo testo, solo comportamento o semplici combinazioni di entrambi. Su GossipCop ha etichettato correttamente circa il 99 percento degli elementi, e sul più difficile set PolitiFact ha raggiunto circa il 96 percento di accuratezza. Ha anche resistito a test più severi, come l'aggiunta di refusi in stile tastiera al testo o il fatto di chiedere al modello addestrato su notizie di celebrità di giudicare post politici. In questi casi, gli indizi a livello di carattere e quelli comportamentali hanno aiutato a preservare gran parte delle prestazioni quando i modelli basati solo sulle parole fallivano.
Cosa significa per i lettori quotidiani
Lo studio dimostra che un rilevamento affidabile delle fake news deve prestare attenzione non solo a ciò che una storia dice, ma anche a come è scritta e a come si muove attraverso una rete sociale. Fondendo queste prospettive e permettendo al sistema di adattarne l'importanza caso per caso, il modello proposto può segnalare post sospetti con alta fiducia rimanendo abbastanza leggero da essere distribuito su piattaforme in tempo reale. Per gli utenti comuni, questo non sostituisce la lettura attenta o la verifica umana dei fatti, ma può agire come uno strato di allerta precoce che rallenta la diffusione di storie fuorvianti prima che raggiungano un vasto pubblico.
Citazione: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Parole chiave: fake news, social media, misinformazione, deep learning, analisi multimodale