Clear Sky Science · pt
Fundindo indícios não textuais com PNL clássica para detecção aprimorada da propagação de notícias falsas multimodais
Por que detectar notícias falsas está ficando mais difícil
Nossas notícias diárias agora chegam por telefones e feeds sociais, onde histórias verdadeiras e falsas circulam lado a lado em alta velocidade. Muitas postagens falsas parecem e soam exatamente como jornalismo real, o que as torna difíceis de identificar com ferramentas que apenas leem as palavras. Este estudo apresenta uma nova maneira de fazer com que computadores julguem histórias online não apenas lendo o texto, mas também observando como as pessoas o compartilham e como a escrita em si é construída, com o objetivo de sinalizar desinformação de forma mais precisa e mais rápida.
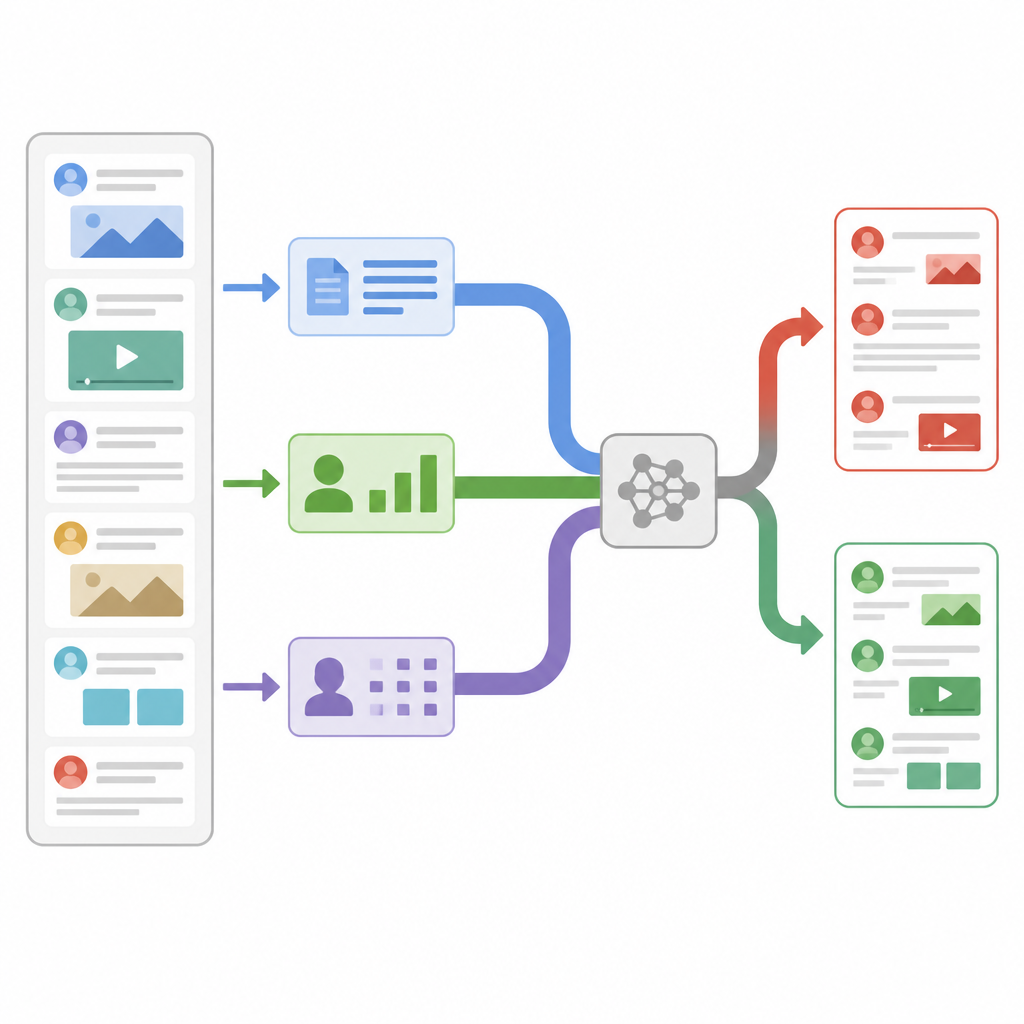
Olhando além das palavras na tela
A maioria dos detectores anteriores de notícias falsas concentrou-se em uma única fonte de informação, geralmente o texto do artigo. Eles contavam frequências de palavras, examinavam o estilo de escrita ou usavam modelos de linguagem modernos para entender o significado. Esses sistemas funcionam bem em casos simples, mas têm dificuldade quando histórias falsas imitam cuidadosamente o tom e o vocabulário de veículos confiáveis. Outros pesquisadores começaram a acrescentar sinais extras das mídias sociais, como a frequência de compartilhamento de uma postagem ou quem a está compartilhando, mas normalmente apenas juntavam todos esses sinais sem perguntar quais importam mais para cada história. O novo estudo argumenta que tanto o conteúdo quanto a forma como ele se espalha carregam pistas, e que um sistema flexível deve decidir na hora quais pistas confiar mais.
Três tipos de pistas de cada item de notícia
Os pesquisadores projetaram um modelo que examina cada postagem de notícias por três lentes diferentes ao mesmo tempo. Primeiro, ele calcula estatísticas projetadas sobre o texto e sobre a conta que a publicou, como a frequência com que seguidores repostam ou comentam, quando a mensagem foi enviada e quão intensamente ela usa pontuação ou hashtags. Segundo, ele aproxima-se ao nível dos caracteres individuais, quebrando palavras em pequenas sequências de caracteres para que ainda possa reconhecer padrões quando as pessoas usam gírias, grafias criativas ou erros de digitação deliberados. Terceiro, ele analisa o significado das palavras, transformando cada palavra em um vetor numérico que captura como ela é usada na linguagem cotidiana. Cada lente transforma suas descobertas em um resumo compacto usando sua própria pequena rede neural, de modo que detalhes ruidosos sejam filtrados antes que as pistas sejam combinadas.
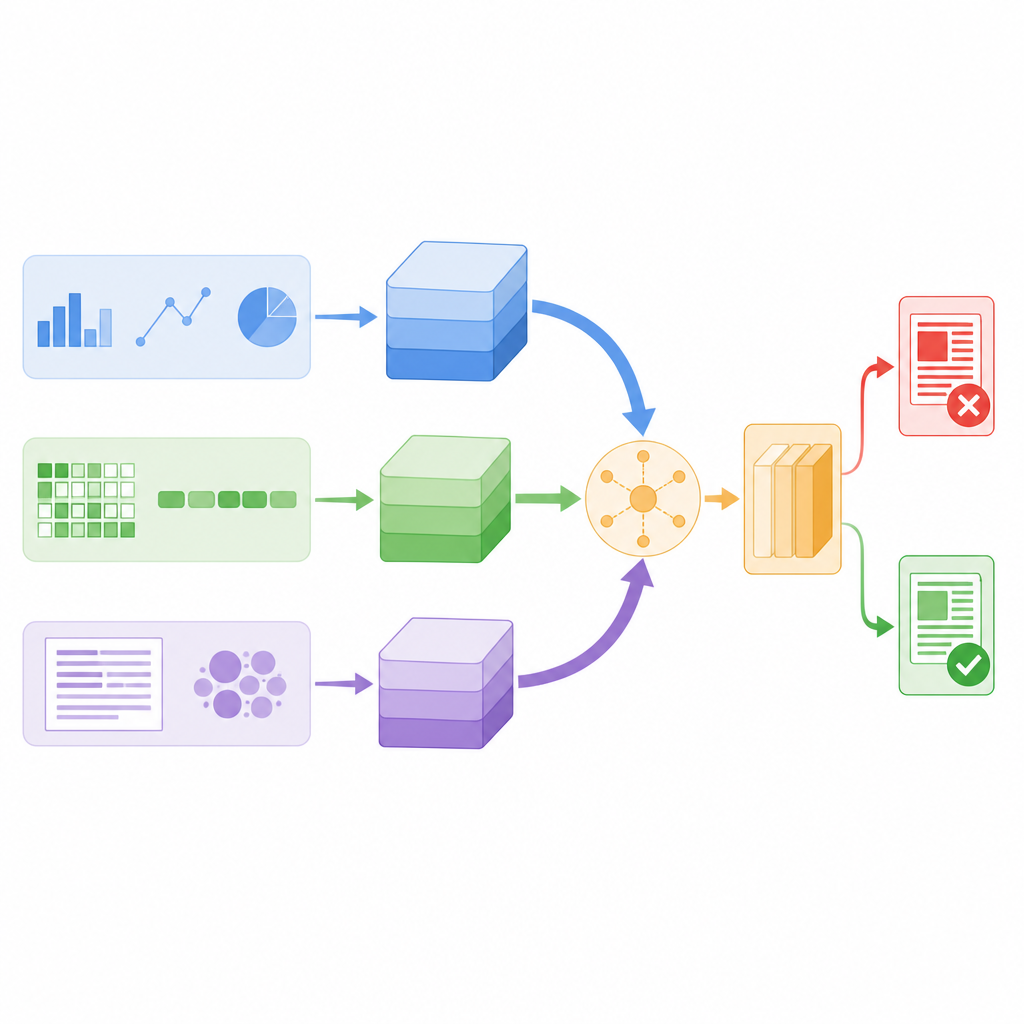
Deixando o sistema escolher em que confiar
Em vez de simplesmente empilhar todos esses resumos, o modelo usa um mecanismo chamado self-attention para pesá-los de forma diferente para cada história. Na prática, isso significa que o sistema aprende quando se apoiar mais no comportamento dos usuários, quando focar no significado das palavras e quando confiar em padrões de caracteres. Por exemplo, se uma postagem parece linguisticamente normal mas se espalha por um padrão de compartilhamento suspeito, o ramo comportamental pode ter mais peso. Todos os três ramos trocam informações por meio de escores de atenção e então são combinados em um único vetor de decisão, que alimenta um classificador final que rotula a notícia como real ou falsa. Esse desenho mantém o número total de parâmetros do modelo relativamente baixo, tornando-o rápido o suficiente para monitoramento em tempo real.
Quão bem isso funciona em dados reais de mídias sociais
A equipe testou sua abordagem em duas coleções amplamente usadas baseadas no Twitter. Uma, chamada GossipCop, cobre boatos de entretenimento; a outra, PolitiFact, contém alegações políticas. Em ambos os conjuntos, o modelo superou em muito métodos anteriores que usavam apenas texto, apenas comportamento ou combinações simples de ambos. No GossipCop, rotulou corretamente cerca de 99% dos itens, e no conjunto mais difícil PolitiFact alcançou cerca de 96% de acurácia. Também se manteve sob testes mais rigorosos, como adicionar erros de digitação no estilo de teclado ao texto ou pedir ao modelo treinado em notícias de celebridades para julgar postagens políticas. Nesses casos, as pistas em nível de caracteres e comportamentais ajudaram a preservar grande parte do desempenho quando modelos baseados apenas em palavras falharam.
O que isso significa para leitores de notícias no dia a dia
O estudo mostra que a detecção confiável de notícias falsas deve prestar atenção não apenas ao que uma história diz, mas também a como ela é escrita e como se move por uma rede social. Ao misturar essas visões e permitir que o sistema adapte a importância delas caso a caso, o modelo proposto pode sinalizar postagens suspeitas com alta confiança enquanto permanece leve o suficiente para ser implantado em plataformas ao vivo. Para usuários comuns, isso não substitui a leitura cuidadosa ou a checagem humana dos fatos, mas pode atuar como uma camada de alerta precoce que desacelera a disseminação de histórias enganosas antes que atinjam grandes audiências.
Citação: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Palavras-chave: notícias falsas, mídias sociais, desinformação, aprendizado profundo, análise multimodal