Clear Sky Science · tr
Geliştirilmiş çok modlu sahte haber yayılımı tespiti için metin dışı ipuçlarını klasik NLP ile birleştirme
Neden sahte haberi tespit etmek zorlaşıyor
Günlük haberler artık telefonlar ve sosyal akışlar aracılığıyla geliyor; burada doğru ve yanlış hikâyeler yüksek hızla yan yana dolaşıyor. Birçok sahte gönderi gerçek gazeteciliğe çok benziyor; bu da yalnızca kelimeleri okuyan araçlarla yakalanmalarını güçleştiriyor. Bu çalışma, bilgisayarların çevrimiçi hikâyeleri yalnızca metni okumakla kalmayıp, aynı zamanda insanların bunları nasıl paylaştığını ve yazının kendi yapısını da izleyerek değerlendirmesi için yeni bir yol sunuyor; amaç yanlış bilgiyi daha doğru ve hızlı şekilde işaretlemek.
Ekrandaki sözcüklerin ötesine bakmak
Önceki çoğu sahte haber algılayıcı tek bir bilgi kaynağına, genellikle makale metnine odaklandı. Kelime frekanslarını saydılar, yazım stiline baktılar veya anlamı anlamak için modern dil modellerini kullandılar. Bu sistemler basit vakalarda iyi çalışıyor, ancak sahte hikâyeler güvenilir yayınların tonu ve sözcük dağarcığını dikkatle taklit ettiğinde zorlanıyorlar. Diğer araştırmacılar, bir gönderinin ne kadar paylaşıldığı veya kimlerin paylaştığı gibi sosyal medyadan ekstra sinyaller eklemeye başladı; ancak genellikle bu sinyalleri hangi hikâye için en önemli olduklarını sormadan yapıştırdılar. Yeni çalışma, hem içeriğin hem de yayılma biçiminin ipuçları taşıdığını ve esnek bir sistemin hangi ipuçlarına daha çok güvenileceğine duruma göre karar vermesi gerektiğini savunuyor.
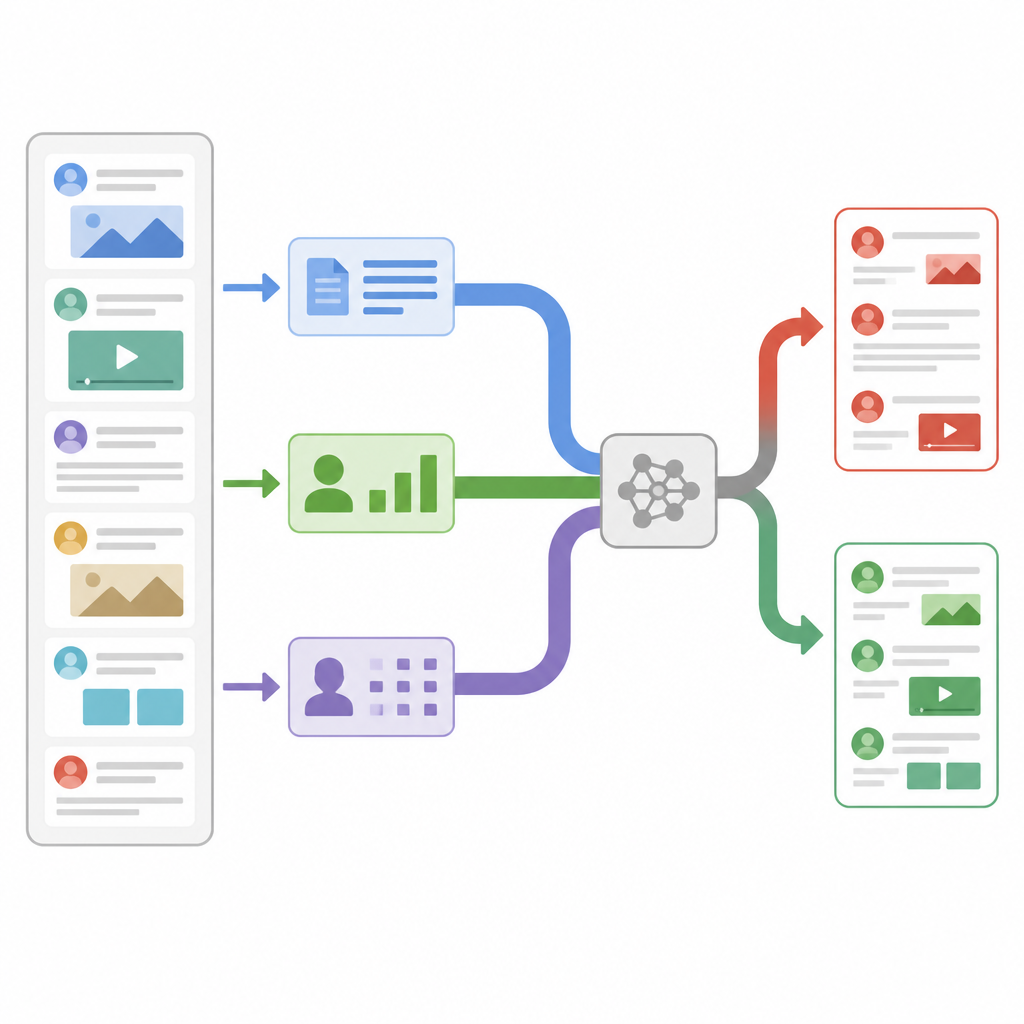
Her haber öğesinden üç tür ipucu
Araştırmacılar, her haber gönderisini aynı anda üç farklı mercekten inceleyen bir model tasarladı. Birincisi, metin ve gönderiyi paylaşan hesap hakkında mühendislik temelli istatistikler hesaplar; örneğin takipçilerin ne sıklıkta yeniden paylaştığı veya yorum yaptığı, mesajın ne zaman gönderildiği ve noktalama işaretleri veya etiketlerin ne kadar yoğun kullanıldığı gibi. İkincisi, bireysel karakter düzeyine yakınlaşıp kelimeleri kısa karakter zincirlerine bölerek insanların argo, yaratıcı yazım veya kasıtlı yazım hataları kullandığında bile desenleri tanıyabilmeyi sağlar. Üçüncüsü, her kelimeyi günlük dilde nasıl kullanıldığını yakalayan sayısal bir vektöre çevirerek sözcük anlamına bakar. Her mercek, bulgularını kendi küçük sinir ağı ile sıkıştırılmış bir özet haline getirir; böylece gürültülü ayrıntılar ipuçları birleştirilmeden önce filtrelenir.
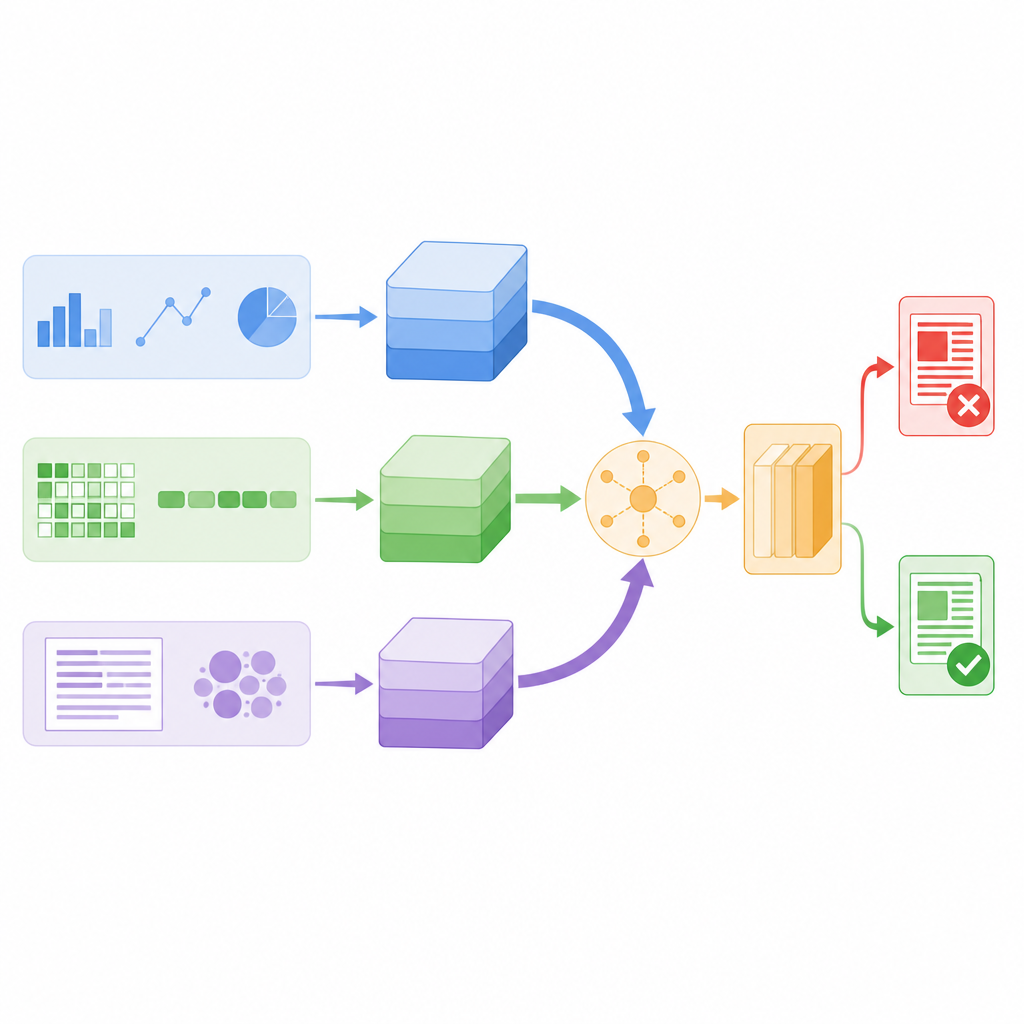
Sistemin neye güveneceğine kendisinin karar vermesi
Bu özetleri basitçe üst üste koymak yerine model, bunları her hikâye için farklı ağırlıklandırmak üzere kendine dikkat (self-attention) adı verilen bir mekanizma kullanır. Pratikte bu, sistemin ne zaman kullanıcı davranışına daha fazla yaslanacağını, ne zaman sözcük anlamına odaklanacağını ve ne zaman karakter desenlerine güveneceğini öğrenmesi demektir. Örneğin, bir gönderi dilbilimsel olarak normal görünür ama şüpheli bir paylaşım modeli üzerinden yayılıyorsa davranışsal dal daha fazla ağırlık taşıyabilir. Üç dalın her biri dikkat skorları aracılığıyla bilgi alışverişinde bulunur ve ardından tek bir karar vektöründe ortalanır; bu vektör nihai sınıflandırıcıya beslenir ve haberin gerçek ya da sahte olarak etiketlenmesini sağlar. Bu tasarım, model parametrelerinin toplam sayısını nispeten düşük tutar; bu da gerçek zamanlı izleme için yeterince hızlı olmasını sağlar.
Gerçek sosyal medya verilerinde ne kadar iyi çalışıyor
Takım yaklaşımını iki yaygın kullanılan Twitter tabanlı koleksiyon üzerinde test etti. Birincisi GossipCop adını taşıyor ve eğlence dedikodularını kapsıyor; diğeri PolitiFact ise politik iddialar içeriyor. Her iki sette de model yalnızca metin kullanan, yalnızca davranış kullanan veya her ikisinin basit kombinasyonlarını kullanan önceki yöntemleri büyük ölçüde geride bıraktı. GossipCop üzerinde öğelerin yaklaşık yüzde 99’unu doğru etiketledi, daha zor olan PolitiFact setinde ise yaklaşık yüzde 96 doğruluk seviyesine ulaştı. Ayrıca, metne klavye tarzı yazım hataları ekleme veya ünlü haberleri üzerinde eğitilmiş modeli politik gönderileri değerlendirmeye zorlamak gibi daha zorlu testlerde de dayanıklılık gösterdi. Bu durumlarda karakter düzeyindeki ve davranışsal ipuçları, yalnızca sözcük temelli modeller çöktüğünde performansın büyük bir kısmını korumaya yardımcı oldu.
Günlük haber okuyucuları için bunun anlamı
Çalışma, güvenilir sahte haber tespitinin sadece bir hikâyenin ne söylediğine değil, aynı zamanda nasıl yazıldığına ve bir sosyal ağ içinde nasıl yayıldığına da dikkat etmesi gerektiğini gösteriyor. Bu görüşleri harmanlayıp sistemin önemlerini vaka bazında uyarlamasına izin vererek önerilen model, şüpheli gönderileri yüksek güvenle işaretleyebilir ve canlı platformlara dağıtılabilecek kadar hafif kalabilir. Olağan kullanıcılar için bu, dikkatli okumayı veya insanlı doğrulamayı yerine koymaz; ancak yanıltıcı hikâyeler geniş kitlelere ulaşmadan önce yayılmasını yavaşlatacak erken bir uyarı katmanı olarak iş görebilir.
Atıf: Dang, J., Sun, Y. & Yu, C. Fusing non-textual cues with classical NLP for enhanced multimodal fake news spread detection. Sci Rep 16, 16193 (2026). https://doi.org/10.1038/s41598-026-45735-3
Anahtar kelimeler: sahte haber, sosyal medya, yanlış bilgi, derin öğrenme, çok modlu analiz