Clear Sky Science · zh
从数据到发现:信息论预测模型在药物开发中的崛起
为何更快的药物发现至关重要
许多严重疾病仍然缺乏有效疗法,即便发现了有前景的药物,从概念走到药房货架也需要漫长且昂贵的过程。本文探讨了更智能的计算模型如何在庞大的化学与生物数据集中筛选出少数有希望的候选药物,更快且更可靠地定位目标。借鉴信息论——关于从数据中能学到多少的数学——作者展示了一种缩小新药搜索范围并更好理解是什么使分子在体内具有活性的途径。
从试错走向数据驱动设计
传统药物发现依赖于有根据的猜测、实验室筛选,有时也靠运气,如青霉素的发现。如今,研究人员可以在真正动手做实验之前在计算机中测试数百万种化合物。虚拟筛选工具根据预测的生物学行为对分子进行分类,帮助科学家聚焦最有希望的候选分子。然而,许多现有工具要么将每个分子孤立处理,要么只给出粗略的概率估计,常常难以捕捉现实生物学背景(例如药物在体内的运动方式)如何影响成功或失败。
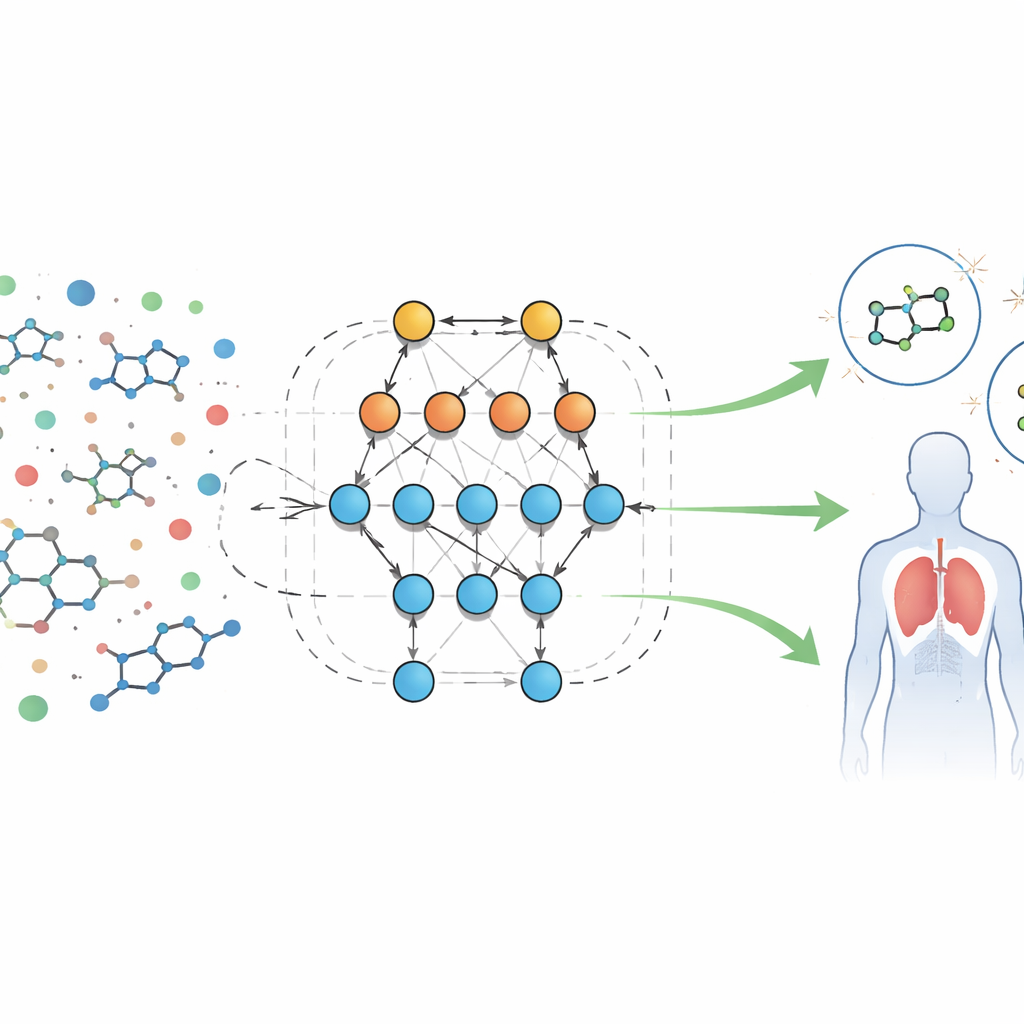
读取生物指纹的新方法
作者分析了面向甲酰肽受体(一种参与炎症和免疫防御的蛋白质)的分子生物筛选大规模公开数据集。每个样本都带有数十个可测特征或“描述符”,例如分子大小、在脂肪或水中溶解的难易程度、穿过血脑屏障的能力以及形成氢键的能力。团队没有为这些特征编写固定方程,而是使用名为 Eidos 的自动化系统,直接从数据构建基于信息论的预测模型。这些模型被称为 ASC(自动化系统-认知)分析,能够学习特征组合如何与样本在生物学测试中表现为活性(可能有用)或非活性相关联。
清理数据并选择重要特征
现实中的筛选数据通常很嘈杂:测量可能不一致,有些样本可能不符合任何清晰模式。Eidos 系统首先过滤掉这些“伪像”,移除了一千多条可疑记录,只保留约两千多条可靠样本。随后它检查三百多项特征,评估哪些特征实际上有助于区分活性与非活性样本。利用信息论概念,为每个特征评分,衡量其减少结果不确定性的程度。分析显示,只有少数特征携带大部分有用信息,这意味着研究者可以安全地忽略许多测量,同时保留几乎全部的预测能力。这样的裁剪使模型更简单、更易解释且运行更快。
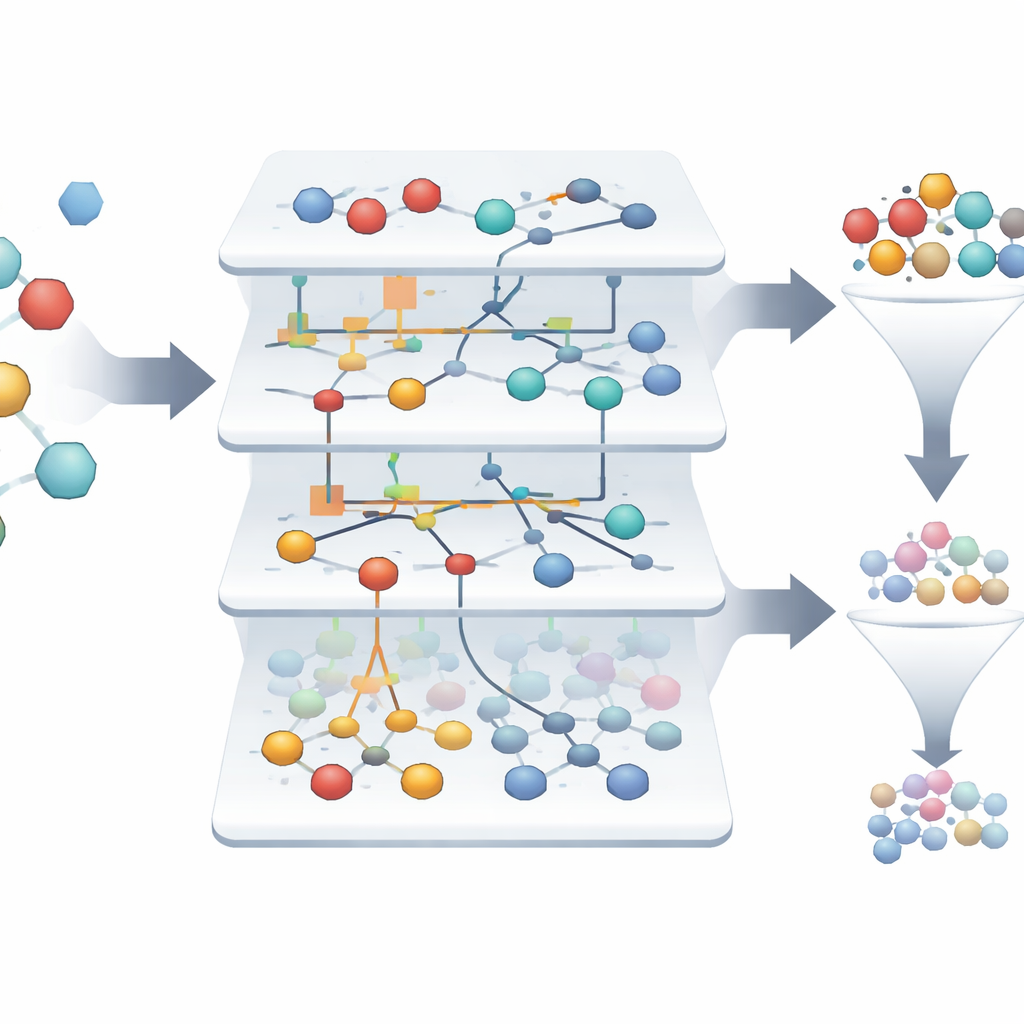
在失败海洋中找到稀有赢家
在所研究的数据集中,只有约 1.4% 的分子是真正活性的,从成千上万的失败中识别出少数赢家具有挑战性。基于 ASC 的模型自动构建“信息肖像”,展示每个特征及特征组合在多大程度上将样本推向活性或非活性。来自三千多条原始样本中,系统仅突出两条作为针对甲酰肽受体的高度可靠药物候选,模型在回溯性测试中的可靠性接近 99.9%。可视化网络图展示了哪些分子特征最强烈地支持活性状态,为科学家提供了一个可解释的、说明促成有希望行为的驱动因素的地图。
该方法的比较与后续方向
作者将他们的方法与一些流行的早期预测工具(如 pkCSM、SwissADME 和 ADMETlab)进行了对比,这些工具估计药物的吸收、分布、代谢和排泄情况。相比主要依赖预定义规则或通用机器学习的系统,ASC 框架明确衡量每个特征对关于类似药物行为知识增量的贡献,并能模拟生物学背景的变化。同时,研究也指出了局限:数据集相对较小且高度不平衡,该方法目前仅应用于单一受体。作者建议未来版本可以将 ASC 模型与深度学习结合,并扩展到多个靶点。
对未来药物的意义
从实践角度看,这项工作表明信息丰富的模型能够将混乱的筛选数据转化为清晰且可检验的预测,指出哪些分子值得进一步关注。通过自动清理数据、对特征重要性排序并突出稀有但有前景的化合物,这一方法可减少进入实验室乃至临床所需的时间和成本。虽然它不能取代动物研究或人体试验,但可作为强有力的筛选与指导工具,帮助科学家更高效、更有信心地将原始数据转化为潜在疗法。
引用: Saied, H., Alfahad, O., Aljaffer, A.A. et al. From data to discovery: The rise of information-theoretic predictive models in drug development. Sci Rep 16, 12857 (2026). https://doi.org/10.1038/s41598-026-45644-5
关键词: 药物发现, 虚拟筛选, 预测建模, 生物测定数据, 甲酰肽受体