Clear Sky Science · ar
من البيانات إلى الاكتشاف: صعود نماذج التنبؤ المعلوماتية في تطوير الأدوية
لماذا يهم تسريع اكتشاف الأدوية
لا تزال العديد من الأمراض الخطيرة تفتقر إلى علاجات فعالة، وحتى عند اكتشاف أدوية واعدة، تكون الرحلة من الفكرة إلى رف الصيدلية طويلة ومكلفة. يستعرض هذا المقال كيف يمكن لنماذج حاسوبية أذكى أن تفرز مجموعات هائلة من البيانات الكيميائية والبيولوجية لتحديد عدد قليل من المرشحين الواعدين بشكل أسرع وأكثر موثوقية. من خلال استعارة أفكار من نظرية المعلومات—الرياضيات التي تصف مقدار ما يمكن معرفته من البيانات—يُظهر المؤلفون طريقة لتضييق نطاق البحث عن أدوية جديدة وفهم أفضل للعوامل التي تجعل جزيئًا ما مرجحًا أن يعمل داخل الجسم.
من التجربة والخطأ إلى التصميم القائم على البيانات
اعتمد اكتشاف الأدوية التقليدي على مزيج من التخمين المستنير، والفحص المختبري، وفي أحيان قليلة على حوادث محظوظة مثل اكتشاف البنسلين. اليوم يمكن للباحثين اختبار ملايين المركبات في الحواسيب قبل لمس أنبوب اختبار واحد. تصنف أدوات الفحص الافتراضي الجزيئات وفقًا لسلوكها البيولوجي المتوقع، مما يساعد العلماء على التركيز على الأكثر وعدًا. ومع ذلك، فإن العديد من الأدوات الحالية إما تعامل كل جزيء بمعزل عن غيره أو تقدم تقديرات احتمال تقريبية، وغالبًا ما تكافح لالتقاط كيف يشكّل السياق البيولوجي الواقعي—مثل كيفية تحرك الدواء داخل الجسم—نجاحه أو فشله.
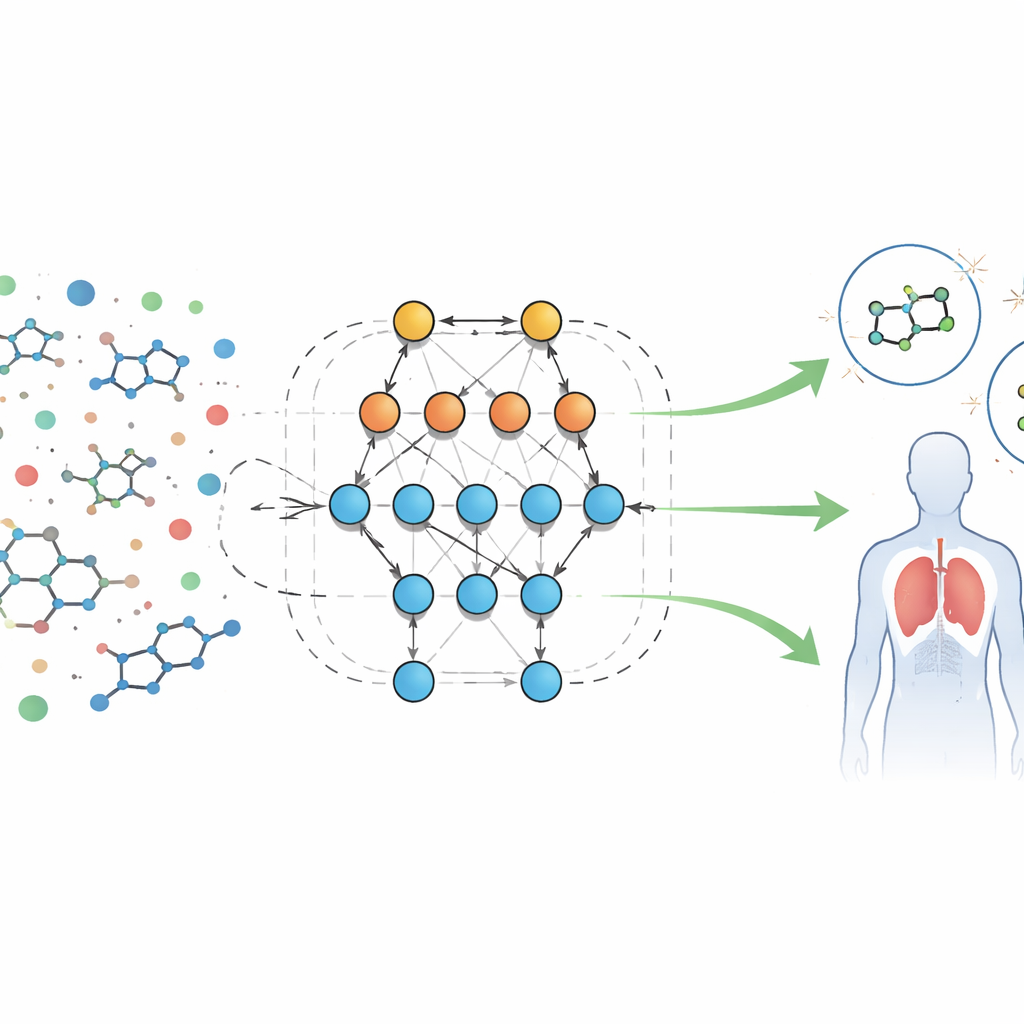
طريقة جديدة لقراءة البصمات البيولوجية
يحلل المؤلفون مجموعة بيانات عامة كبيرة لنتائج الفحص البيولوجي لمركبات موجهة نحو مستقبل الببتيد الفورميلي، وهو بروتين يشارك في الالتهاب والدفاع المناعي. تأتي كل عينة مع عشرات الميزات القابلة للقياس، أو "المواصفات"، مثل حجم الجزيء، سهولة ذوبانه في الدهون أو الماء، القدرة على عبور الحاجز الدماغي الدموي، والقدرة على تكوين روابط هيدروجينية. بدلًا من كتابة معادلات ثابتة لكيفية تصرّف هذه الميزات، يستخدم الفريق نظامًا آليًا يُدعى Eidos، يبني نماذج تنبؤية معلوماتية مباشرة من البيانات. تُعرف هذه النماذج بتحليل ASC (النظام الآلي-الإدراكي)، وتتعلّم كيف ترتبط تراكيب الميزات بما إذا كانت العينة تظهر نشاطًا (مفيدة محتملًا) أو لا في الاختبارات البيولوجية.
تنقية البيانات واختيار ما يهم
بيانات الفحص في العالم الحقيقي صاخبة: قد تكون القياسات غير متسقة، وقد لا تنتمي بعض العينات إلى أي نمط واضح. يقوم نظام Eidos أولًا بفلترة هذه "الزائفة"، بإزالة أكثر من ألف إدخال مشكوك فيه والحفاظ على نحو أكثر من ألفي عينة موثوقة. ثم يفحص أكثر من 300 ميزة ليرى أيها يساعد فعليًا في تمييز العينات النشطة عن غير النشطة. باستخدام مفاهيم من نظرية المعلومات، تُعطى كل ميزة درجة تُقاس بمدى تقليلها لعدم اليقين حول النتيجة. تكشف التحليلات أن أقلية فقط من الميزات تحمل معظم المعلومات المفيدة، مما يعني أن الباحثين يمكنهم تجاهل العديد من القياسات مع الاحتفاظ تقريبًا بكل القدرة التنبؤية. يسهّل هذا التقليص جعل النماذج أبسط، وأسهل في التفسير، وأسرع في التشغيل.
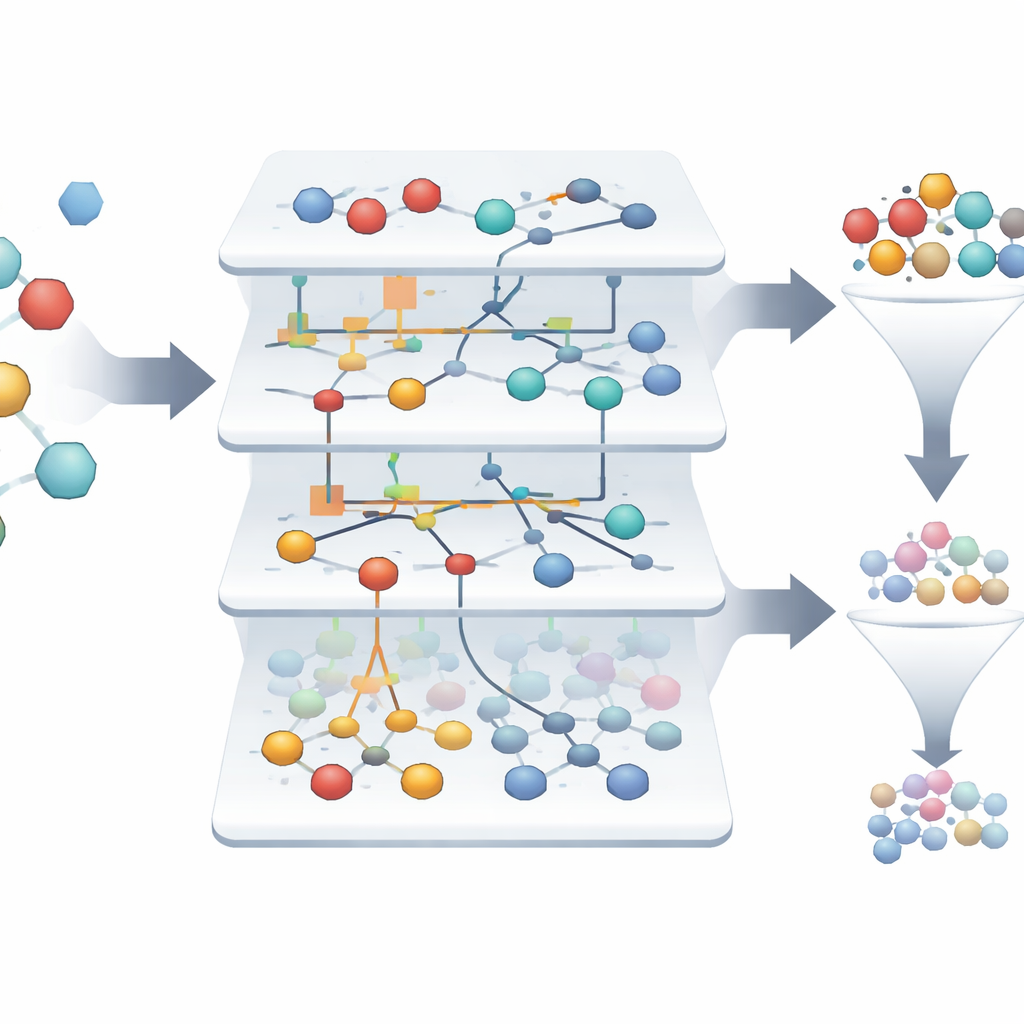
العثور على الفائزين النادرين في بحر من الإخفاقات
في مجموعة البيانات المدروسة، نحو 1.4% فقط من الجزيئات نشطة فعليًا، ما يجعل من الصعب رصد القلائل الفائزين بين آلاف الإخفاقات. تبني النماذج القائمة على ASC تلقائيًا "بورتريهات معلوماتية" تُظهر مدى تأثير كل ميزة وتركيبة ميزات في دفع العينة نحو حالة نشاط أو لا نشاط. من أكثر من ثلاثة آلاف عينة أصلية، يسلط النظام الضوء على عينتين فقط تبرزان كمرشحين موثوقين للغاية للأدوية المستهدفة لمستقبل الببتيد الفورميلي، مع موثوقية نموذج تقارب 99.9% في الاختبارات الرجعية. تُظهر مخططات الشبكات المرئية أي الخصائص الجزيئية تدعم الحالة النشطة بقوة، مما يمنح العلماء خريطة قابلة للتفسير لما يحفّز السلوك الواعد.
كيف يقارن هذا النهج وما التالي
يقارن المؤلفون طريقتهم بأدوات التنبؤ المبكرة الشائعة مثل pkCSM وSwissADME وADMETlab، التي تُقدر كيف يمتص الجسم الدواء ويوزعه ويكسّره ويخرجه. بينما تعتمد تلك الأنظمة أساسًا على قواعد محددة مسبقًا أو تعلم آلي عام الغرض، يقيس إطار ASC بشكل صريح مقدار مساهمة كل ميزة في المعرفة المكتسبة حول سلوك شبيه بالدواء ويمكنه محاكاة تغييرات السياق البيولوجي. في الوقت نفسه، تشير الدراسة إلى حدود: فمجموعة البيانات صغيرة نسبيًا وغير متوازنة بشدة، وطُبّق الأسلوب حتى الآن على مستقبل واحد فقط. يقترح المؤلفون أن الإصدارات المستقبلية قد تجمع نماذج ASC مع التعلم العميق وتمتد إلى أهداف متعددة.
ما الذي يعنيه هذا للأدوية المستقبلية
عمليًا، يُظهر هذا العمل أن النماذج الغنية بالمعلومات يمكن أن تحول بيانات الفحص الفوضوية إلى توقعات واضحة وقابلة للاختبار حول أي الجزيئات تستحق اهتمامًا إضافيًا. من خلال تنظيف البيانات تلقائيًا، وترتيب أهمية الميزات، وتسليط الضوء على المركبات النادرة والواعدة، يمكن لهذا النهج تقليل الوقت والتكلفة اللازمين للوصول إلى المختبر وفي النهاية إلى العيادة. وبينما لا يحل محل دراسات الحيوانات أو التجارب البشرية، فإنه يعمل كمرشح ومرشد قوي، يساعد العلماء على الانتقال من البيانات الخام إلى علاجات محتملة بكفاءة وطمأنينة أكبر.
الاستشهاد: Saied, H., Alfahad, O., Aljaffer, A.A. et al. From data to discovery: The rise of information-theoretic predictive models in drug development. Sci Rep 16, 12857 (2026). https://doi.org/10.1038/s41598-026-45644-5
الكلمات المفتاحية: اكتشاف الأدوية, الفحص الافتراضي, النمذجة التنبؤية, بيانات الاختبارات البيولوجية, مستقبل الببتيد الفورميلي